Structured Reinforcement Learning for Delay-Optimal Data Transmission in Dense mmWave Networks
2404.16920
0
0

Abstract
We study the data packet transmission problem (mmDPT) in dense cell-free millimeter wave (mmWave) networks, i.e., users sending data packet requests to access points (APs) via uplinks and APs transmitting requested data packets to users via downlinks. Our objective is to minimize the average delay in the system due to APs' limited service capacity and unreliable wireless channels between APs and users. This problem can be formulated as a restless multi-armed bandits problem with fairness constraint (RMAB-F). Since finding the optimal policy for RMAB-F is intractable, existing learning algorithms are computationally expensive and not suitable for practical dynamic dense mmWave networks. In this paper, we propose a structured reinforcement learning (RL) solution for mmDPT by exploiting the inherent structure encoded in RMAB-F. To achieve this, we first design a low-complexity and provably asymptotically optimal index policy for RMAB-F. Then, we leverage this structure information to develop a structured RL algorithm called mmDPT-TS, which provably achieves an tilde{O}(sqrt{T}) Bayesian regret. More importantly, mmDPT-TS is computation-efficient and thus amenable to practical implementation, as it fully exploits the structure of index policy for making decisions. Extensive emulation based on data collected in realistic mmWave networks demonstrate significant gains of mmDPT-TS over existing approaches.
Create account to get full access
Overview
- Presents a structured reinforcement learning approach to optimize data transmission in dense millimeter-wave (mmWave) networks
- Focuses on minimizing transmission delay for delay-sensitive data packets
- Formulates the problem as a restless multi-armed bandit (RMAB) model
- Proposes an index-based policy to dynamically allocate transmission resources
Plain English Explanation
This research paper introduces a structured reinforcement learning method to efficiently transmit data in dense millimeter-wave (mmWave) wireless networks. mmWave networks are emerging as a promising technology for high-speed data communication, but they face challenges in managing the large number of connected devices and ensuring timely delivery of delay-sensitive data.
The key idea is to model the data transmission problem as a restless multi-armed bandit (RMAB) problem. In this framework, each device or "arm" represents a potential transmission opportunity, and the goal is to dynamically allocate limited transmission resources to minimize the overall delay. The researchers develop an "index-based policy" that uses reinforcement learning to learn the optimal transmission decisions over time.
By formulating the problem in this structured way and leveraging reinforcement learning, the approach is able to make smart, adaptive decisions about which devices to serve at each time step. This helps ensure that delay-sensitive data is transmitted as quickly as possible, even in the face of the challenges posed by dense mmWave networks.
Technical Explanation
The paper starts by modeling the data transmission problem in dense mmWave networks as a restless multi-armed bandit (RMAB) problem. In this framework, each device or "arm" represents a potential transmission opportunity, and the goal is to dynamically allocate limited transmission resources to minimize the overall delay.
The researchers then propose a structured reinforcement learning approach to solve the RMAB problem. They develop an "index-based policy" that uses a deep Q-network (DQN) to learn the optimal transmission decisions over time. The index policy works by assigning a score or "index" to each device, representing its priority for transmission. These indices are updated at each time step based on the system's state and the reinforcement learning model's predictions.
To evaluate their approach, the authors conduct simulations in a dense mmWave network scenario. They compare their structured reinforcement learning method to several baseline policies, including random scheduling and greedy approaches. The results demonstrate that the proposed index-based policy significantly outperforms the baselines in terms of reducing overall transmission delay, especially for delay-sensitive data packets.
Critical Analysis
The paper presents a well-designed and thorough study of using structured reinforcement learning to optimize data transmission in dense mmWave networks. The RMAB formulation is a clever way to model the problem, and the index-based policy appears to be an effective solution.
One potential limitation is the reliance on simulation-based evaluation. While the simulation scenarios are carefully constructed, it would be valuable to also validate the approach through real-world experiments or testbed deployments to better understand its performance in practical settings. Efficient digital twin data processing for low-latency applications could be a relevant reference for this.
Additionally, the paper does not explore the impact of factors such as user mobility or joint optimization of uplink, OFDMA, and MU-MIMO on the proposed approach. Incorporating these elements could lead to a more comprehensive and realistic understanding of the method's capabilities.
Overall, the research makes a valuable contribution to the field of wireless communication and computing resource allocation, demonstrating the potential of structured reinforcement learning for optimizing delay-sensitive data transmission in dense mmWave networks.
Conclusion
This paper presents a structured reinforcement learning approach for optimizing data transmission in dense millimeter-wave (mmWave) networks. By formulating the problem as a restless multi-armed bandit (RMAB) and developing an index-based policy, the researchers have developed a novel method to dynamically allocate limited transmission resources and minimize overall delay, particularly for delay-sensitive data packets.
The simulation results show that the proposed approach significantly outperforms conventional scheduling policies, highlighting the potential of this structured reinforcement learning technique for improving the performance of mmWave networks in real-world scenarios. As mmWave technology continues to evolve and find application in diverse domains, this research represents an important step towards more efficient and reliable wireless communication systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Mobility-Aware Resource Allocation for mmWave IAB Networks: A Multi-Agent Reinforcement Learning Approach
Bibo Zhang, Ilario Filippini
0
0
MmWaves have been envisioned as a promising direction to provide Gbps wireless access. However, they are susceptible to high path losses and blockages, which directional antennas can only partially mitigate. That makes mmWave networks coverage-limited, thus requiring dense deployments. Integrated access and backhaul (IAB) architectures have emerged as a cost-effective solution for network densification. Resource allocation in mmWave IAB networks must face big challenges to cope with heavy temporal dynamics, such as intermittent links caused by user mobility and blockages from moving obstacles. This makes it extremely difficult to find optimal and adaptive solutions. In this article, exploiting the distributed structure of the problem, we propose a Multi-Agent Reinforcement Learning (MARL) framework to optimize user throughput via flow routing and link scheduling in mmWave IAB networks characterized by user mobility and link outages generated by moving obstacles. The proposed approach implicitly captures the environment dynamics, coordinates the interference, and manages the buffer levels of IAB relay nodes. We design different MARL components, considering full-duplex and half-duplex IAB-nodes. In addition, we provide a communication and coordination scheme for RL agents in an online training framework, addressing the feasibility issues of practical systems. Numerical results show the effectiveness of the proposed approach.
4/24/2024
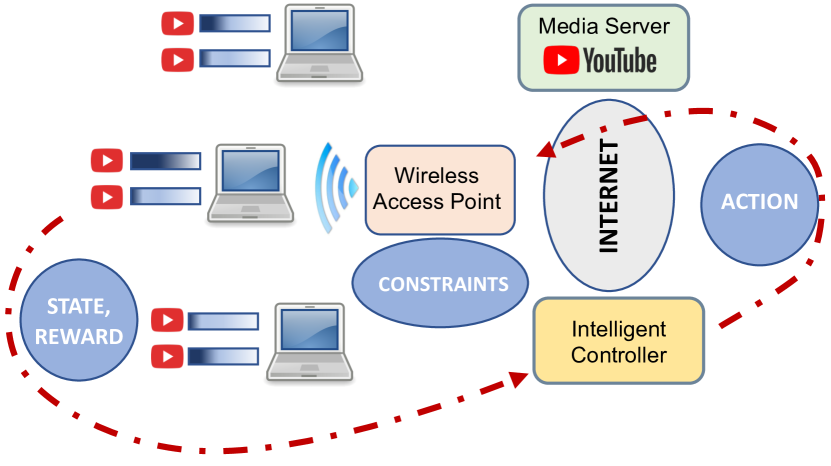
Structured Reinforcement Learning for Media Streaming at the Wireless Edge
Archana Bura, Sarat Chandra Bobbili, Shreyas Rameshkumar, Desik Rengarajan, Dileep Kalathil, Srinivas Shakkottai
0
0
Media streaming is the dominant application over wireless edge (access) networks. The increasing softwarization of such networks has led to efforts at intelligent control, wherein application-specific actions may be dynamically taken to enhance the user experience. The goal of this work is to develop and demonstrate learning-based policies for optimal decision making to determine which clients to dynamically prioritize in a video streaming setting. We formulate the policy design question as a constrained Markov decision problem (CMDP), and observe that by using a Lagrangian relaxation we can decompose it into single-client problems. Further, the optimal policy takes a threshold form in the video buffer length, which enables us to design an efficient constrained reinforcement learning (CRL) algorithm to learn it. Specifically, we show that a natural policy gradient (NPG) based algorithm that is derived using the structure of our problem converges to the globally optimal policy. We then develop a simulation environment for training, and a real-world intelligent controller attached to a WiFi access point for evaluation. We empirically show that the structured learning approach enables fast learning. Furthermore, such a structured policy can be easily deployed due to low computational complexity, leading to policy execution taking only about 15$mu$s. Using YouTube streaming experiments in a resource constrained scenario, we demonstrate that the CRL approach can increase QoE by over 30%.
4/12/2024
🔮
RACH Traffic Prediction in Massive Machine Type Communications
Hossein Mehri, Hao Chen, Hani Mehrpouyan
0
0
Traffic pattern prediction has emerged as a promising approach for efficiently managing and mitigating the impacts of event-driven bursty traffic in massive machine-type communication (mMTC) networks. However, achieving accurate predictions of bursty traffic remains a non-trivial task due to the inherent randomness of events, and these challenges intensify within live network environments. Consequently, there is a compelling imperative to design a lightweight and agile framework capable of assimilating continuously collected data from the network and accurately forecasting bursty traffic in mMTC networks. This paper addresses these challenges by presenting a machine learning-based framework tailored for forecasting bursty traffic in multi-channel slotted ALOHA networks. The proposed machine learning network comprises long-term short-term memory (LSTM) and a DenseNet with feed-forward neural network (FFNN) layers, where the residual connections enhance the training ability of the machine learning network in capturing complicated patterns. Furthermore, we develop a new low-complexity online prediction algorithm that updates the states of the LSTM network by leveraging frequently collected data from the mMTC network. Simulation results and complexity analysis demonstrate the superiority of our proposed algorithm in terms of both accuracy and complexity, making it well-suited for time-critical live scenarios. We evaluate the performance of the proposed framework in a network with a single base station and thousands of devices organized into groups with distinct traffic-generating characteristics. Comprehensive evaluations and simulations indicate that our proposed machine learning approach achieves a remarkable $52%$ higher accuracy in long-term predictions compared to traditional methods, without imposing additional processing load on the system.
5/9/2024
🏅
Continual Model-based Reinforcement Learning for Data Efficient Wireless Network Optimisation
Cengis Hasan, Alexandros Agapitos, David Lynch, Alberto Castagna, Giorgio Cruciata, Hao Wang, Aleksandar Milenovic
0
0
We present a method that addresses the pain point of long lead-time required to deploy cell-level parameter optimisation policies to new wireless network sites. Given a sequence of action spaces represented by overlapping subsets of cell-level configuration parameters provided by domain experts, we formulate throughput optimisation as Continual Reinforcement Learning of control policies. Simulation results suggest that the proposed system is able to shorten the end-to-end deployment lead-time by two-fold compared to a reinitialise-and-retrain baseline without any drop in optimisation gain.
5/1/2024