Structured Reinforcement Learning for Media Streaming at the Wireless Edge
2404.07315
0
0
Abstract
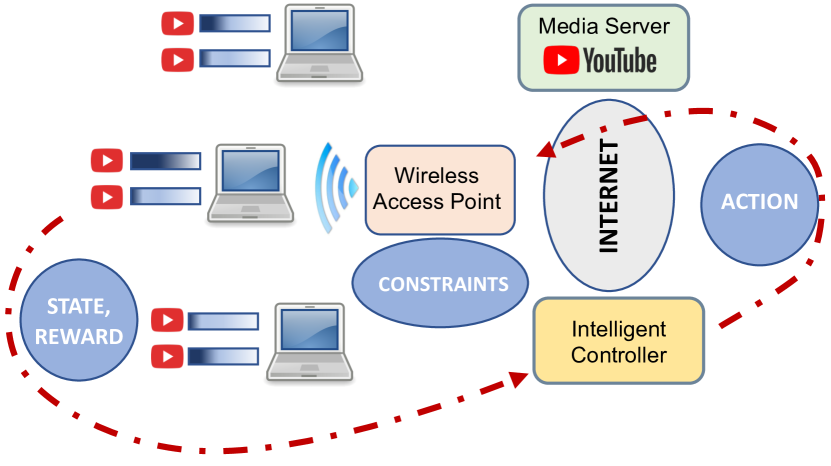
Media streaming is the dominant application over wireless edge (access) networks. The increasing softwarization of such networks has led to efforts at intelligent control, wherein application-specific actions may be dynamically taken to enhance the user experience. The goal of this work is to develop and demonstrate learning-based policies for optimal decision making to determine which clients to dynamically prioritize in a video streaming setting. We formulate the policy design question as a constrained Markov decision problem (CMDP), and observe that by using a Lagrangian relaxation we can decompose it into single-client problems. Further, the optimal policy takes a threshold form in the video buffer length, which enables us to design an efficient constrained reinforcement learning (CRL) algorithm to learn it. Specifically, we show that a natural policy gradient (NPG) based algorithm that is derived using the structure of our problem converges to the globally optimal policy. We then develop a simulation environment for training, and a real-world intelligent controller attached to a WiFi access point for evaluation. We empirically show that the structured learning approach enables fast learning. Furthermore, such a structured policy can be easily deployed due to low computational complexity, leading to policy execution taking only about 15$mu$s. Using YouTube streaming experiments in a resource constrained scenario, we demonstrate that the CRL approach can increase QoE by over 30%.
Create account to get full access
Overview
- This research paper explores the use of structured reinforcement learning to optimize media streaming at the wireless edge.
- It proposes a novel reinforcement learning framework to dynamically allocate resources and adapt media streaming strategies based on wireless channel conditions.
- The approach aims to improve user quality of experience while minimizing energy consumption and latency at the wireless edge.
Plain English Explanation
In this paper, the researchers are looking at ways to improve how videos and other media are streamed to devices at the wireless edge. The wireless edge refers to the devices and infrastructure, like cell towers, that connect people's devices to the internet wirelessly.
The key challenge is that wireless connections can be unstable and have varying quality, which can lead to issues like buffering or poor video quality for the user. The researchers propose using a technique called reinforcement learning to help the streaming system dynamically adapt to changing wireless conditions.
Reinforcement learning is a type of machine learning where the system learns by trial and error, getting rewards or penalties based on how well it performs a task. In this case, the system would learn how to best allocate network resources and adjust the media streaming strategy to maintain a good user experience, even as the wireless conditions change.
The goal is to improve the quality of experience for users watching videos or accessing other media on their devices, while also minimizing energy use and latency (the delay between when a user requests something and when they receive it). This could lead to smoother, more reliable media streaming at the wireless edge.
Technical Explanation
The paper introduces a structured reinforcement learning framework to optimize media streaming at the wireless edge. The approach leverages a hierarchical decision-making structure to dynamically allocate resources and adapt streaming strategies based on wireless channel conditions.
The framework models the media streaming problem as a Markov decision process, where the agent (the streaming system) observes the state of the wireless channel and takes actions to optimize the user's quality of experience, energy consumption, and latency.
The key technical contributions include:
- A structured reinforcement learning architecture that decomposes the problem into high-level and low-level decision-making.
- A model-based deep reinforcement learning approach to efficiently learn the optimal policies.
- Incorporation of domain knowledge to guide the exploration and learning process.
The authors evaluate their approach through simulations and demonstrate significant improvements in quality of experience, energy efficiency, and latency compared to baseline streaming strategies.
Critical Analysis
The paper provides a promising approach for optimizing media streaming at the wireless edge using structured reinforcement learning. The proposed framework effectively leverages the hierarchical nature of the problem to learn efficient policies for resource allocation and streaming strategy adaptation.
One potential limitation is the reliance on simulation-based evaluation. While the simulations seem to capture realistic wireless channel dynamics, it would be valuable to validate the approach through real-world deployments and user studies to fully understand its performance in practical settings.
Additionally, the paper does not extensively explore the impact of various wireless network characteristics, such as user mobility, interference, or network topology, on the reinforcement learning agent's performance. Investigating the robustness of the approach to different network conditions would be an important area for future research.
Finally, the authors could have discussed the computational and memory requirements of their model-based deep reinforcement learning approach, as well as any potential challenges in scaling the solution to large-scale deployments with many users and devices.
Conclusion
This research paper presents a novel structured reinforcement learning framework for optimizing media streaming at the wireless edge. By dynamically adapting resource allocation and streaming strategies based on wireless channel conditions, the approach aims to improve user quality of experience, energy efficiency, and latency.
The technical contributions, including the hierarchical decision-making structure and the model-based deep reinforcement learning approach, demonstrate the potential of reinforcement learning to address the complex challenges of media streaming in dynamic wireless environments. While further real-world validation and exploration of edge cases would be valuable, this work represents an important step towards more intelligent and responsive media delivery at the wireless edge.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Structured Reinforcement Learning for Delay-Optimal Data Transmission in Dense mmWave Networks
Shufan Wang, Guojun Xiong, Shichen Zhang, Huacheng Zeng, Jian Li, Shivendra Panwar
0
0
We study the data packet transmission problem (mmDPT) in dense cell-free millimeter wave (mmWave) networks, i.e., users sending data packet requests to access points (APs) via uplinks and APs transmitting requested data packets to users via downlinks. Our objective is to minimize the average delay in the system due to APs' limited service capacity and unreliable wireless channels between APs and users. This problem can be formulated as a restless multi-armed bandits problem with fairness constraint (RMAB-F). Since finding the optimal policy for RMAB-F is intractable, existing learning algorithms are computationally expensive and not suitable for practical dynamic dense mmWave networks. In this paper, we propose a structured reinforcement learning (RL) solution for mmDPT by exploiting the inherent structure encoded in RMAB-F. To achieve this, we first design a low-complexity and provably asymptotically optimal index policy for RMAB-F. Then, we leverage this structure information to develop a structured RL algorithm called mmDPT-TS, which provably achieves an tilde{O}(sqrt{T}) Bayesian regret. More importantly, mmDPT-TS is computation-efficient and thus amenable to practical implementation, as it fully exploits the structure of index policy for making decisions. Extensive emulation based on data collected in realistic mmWave networks demonstrate significant gains of mmDPT-TS over existing approaches.
4/29/2024
🤿
Closed-form congestion control via deep symbolic regression
Jean Martins, Igor Almeida, Ricardo Souza, Silvia Lins
0
0
As mobile networks embrace the 5G era, the interest in adopting Reinforcement Learning (RL) algorithms to handle challenges in ultra-low-latency and high throughput scenarios increases. Simultaneously, the advent of packetized fronthaul networks imposes demanding requirements that traditional congestion control mechanisms cannot accomplish, highlighting the potential of RL-based congestion control algorithms. Although learning RL policies optimized for satisfying the stringent fronthaul requirements is feasible, the adoption of neural network models in real deployments still poses some challenges regarding real-time inference and interpretability. This paper proposes a methodology to deal with such challenges while maintaining the performance and generalization capabilities provided by a baseline RL policy. The method consists of (1) training a congestion control policy specialized in fronthaul-like networks via reinforcement learning, (2) collecting state-action experiences from the baseline, and (3) performing deep symbolic regression on the collected dataset. The proposed process overcomes the challenges related to inference-time limitations through closed-form expressions that approximate the baseline performance (link utilization, delay, and fairness) and which can be directly implemented in any programming language. Finally, we analyze the inner workings of the closed-form expressions.
5/3/2024
🛠️
ReinWiFi: A Reinforcement-Learning-Based Framework for the Application-Layer QoS Optimization of WiFi Networks
Qianren Li, Bojie Lv, Yuncong Hong, Rui Wang
0
0
In this paper, a reinforcement-learning-based scheduling framework is proposed and implemented to optimize the application-layer quality-of-service (QoS) of a practical wireless local area network (WLAN) suffering from unknown interference. Particularly, application-layer tasks of file delivery and delay-sensitive communication, e.g., screen projection, in a WLAN with enhanced distributed channel access (EDCA) mechanism, are jointly scheduled by adjusting the contention window sizes and application-layer throughput limitation, such that their QoS, including the throughput of file delivery and the round trip time of the delay-sensitive communication, can be optimized. Due to the unknown interference and vendor-dependent implementation of the network interface card, the relation between the scheduling policy and the system QoS is unknown. Hence, a reinforcement learning method is proposed, in which a novel Q-network is trained to map from the historical scheduling parameters and QoS observations to the current scheduling action. It is demonstrated on a testbed that the proposed framework can achieve a significantly better QoS than the conventional EDCA mechanism.
5/7/2024
🛠️
Energy-Efficient Federated Edge Learning with Streaming Data: A Lyapunov Optimization Approach
Chung-Hsuan Hu, Zheng Chen, Erik G. Larsson
0
0
Federated learning (FL) has received significant attention in recent years for its advantages in efficient training of machine learning models across distributed clients without disclosing user-sensitive data. Specifically, in federated edge learning (FEEL) systems, the time-varying nature of wireless channels introduces inevitable system dynamics in the communication process, thereby affecting training latency and energy consumption. In this work, we further consider a streaming data scenario where new training data samples are randomly generated over time at edge devices. Our goal is to develop a dynamic scheduling and resource allocation algorithm to address the inherent randomness in data arrivals and resource availability under long-term energy constraints. To achieve this, we formulate a stochastic network optimization problem and use the Lyapunov drift-plus-penalty framework to obtain a dynamic resource management design. Our proposed algorithm makes adaptive decisions on device scheduling, computational capacity adjustment, and allocation of bandwidth and transmit power in every round. We provide convergence analysis for the considered setting with heterogeneous data and time-varying objective functions, which supports the rationale behind our proposed scheduling design. The effectiveness of our scheme is verified through simulation results, demonstrating improved learning performance and energy efficiency as compared to baseline schemes.
5/21/2024