StructuredRAG: JSON Response Formatting with Large Language Models

217

Sign in to get full access
Overview
- The paper introduces StructuredRAG, a framework for formatting JSON responses from large language models (LLMs) in a more structured and intuitive way.
- StructuredRAG aims to improve the usability and interpretability of LLM outputs, making it easier for users to understand and interact with the information provided.
- The framework includes features like hierarchical organization, type annotations, and contextual metadata to enhance the readability and utility of LLM-generated JSON responses.
Plain English Explanation
StructuredRAG is a new way of formatting the responses from large language models (LLMs) to make them more user-friendly. LLMs are powerful AI systems that can generate human-like text, but their outputs can sometimes be hard to understand or interact with, especially when the information is returned in a raw JSON format.
StructuredRAG aims to solve this problem by adding more structure and context to the LLM's responses. Instead of just getting a big block of text, the StructuredRAG framework organizes the information hierarchically, labels different types of content (like facts, opinions, or instructions), and provides additional metadata to help the user make sense of what they're seeing.
For example, instead of a JSON response that looks like this:
{
"text": "The capital of France is Paris. The Eiffel Tower is a famous landmark in Paris. Paris has a population of over 2 million people."
}
StructuredRAG would return something more like this:
{
"facts": [
{
"text": "The capital of France is Paris.",
"type": "geographic"
},
{
"text": "The Eiffel Tower is a famous landmark in Paris.",
"type": "landmark"
},
{
"text": "Paris has a population of over 2 million people.",
"type": "demographic"
}
],
"meta": {
"topic": "Paris, France",
"source": "Wikipedia"
}
}
This structured format makes it much easier for users to quickly understand and interact with the information provided by the LLM. The hierarchical organization, type annotations, and contextual metadata all help to improve the usability and interpretability of the LLM's output.
Technical Explanation
The core idea behind StructuredRAG is to take the unstructured text outputs of large language models and transform them into a more organized, annotated JSON format. This is achieved through a multi-step process:
-
Segmentation: The LLM's output is first divided into smaller, semantically meaningful segments (e.g., individual facts, opinions, or instructions).
-
Type Annotation: Each segment is then labeled with a specific type (e.g., geographic, demographic, landmark) to indicate the nature of the information it contains.
-
Hierarchical Organization: The segments are organized into a hierarchical structure, with related content grouped together and nested accordingly.
-
Contextual Metadata: Additional metadata is attached to provide relevant context about the overall topic, source, or other details that can help users interpret the information.
The resulting StructuredRAG format is designed to be more intuitive and useful for end-users, allowing them to quickly understand the content, identify different types of information, and navigate the responses more effectively.
The paper presents several use cases and examples demonstrating how StructuredRAG can be applied to improve the user experience when interacting with LLM-powered applications, such as question answering, task completion, and information retrieval.
Critical Analysis
The StructuredRAG framework addresses a crucial challenge in the field of large language models: how to present the often complex and unstructured outputs of these models in a way that is easily interpretable and actionable for users.
One of the key strengths of StructuredRAG is its flexibility and modularity. The framework is designed to be applicable to a wide range of LLM-powered applications, allowing developers to tailor the specific formatting and annotation schemes to their use case. This adaptability is important, as the informational needs and user preferences can vary significantly across different domains and applications.
That said, the paper does not provide a comprehensive evaluation of the framework's performance or user experience impact. While the authors present some illustrative examples, a more thorough user study or comparison to alternative approaches would help strengthen the case for StructuredRAG's practical benefits.
Additionally, the paper does not delve deeply into the technical challenges or design decisions involved in implementing the StructuredRAG pipeline. A more detailed discussion of the segmentation, annotation, and organization algorithms, as well as their potential limitations or failure modes, would be valuable for researchers and developers interested in replicating or extending the work.
Overall, the StructuredRAG framework represents a promising step towards improving the usability and accessibility of large language models. As LLMs continue to advance and become more integrated into our daily lives, innovations like StructuredRAG will be crucial in ensuring that their outputs can be effectively leveraged by a wide range of users.
Conclusion
The StructuredRAG framework introduced in this paper offers a novel approach to formatting the JSON responses of large language models (LLMs) in a more structured and user-friendly way. By organizing the LLM's output into a hierarchical structure, annotating different types of content, and providing relevant metadata, StructuredRAG aims to enhance the interpretability and utility of these powerful AI systems.
The potential benefits of StructuredRAG are far-reaching, as LLMs become increasingly integrated into a wide range of applications and services. By making LLM outputs more accessible and intuitive for end-users, the framework could facilitate better understanding, decision-making, and task completion across a variety of domains, from question answering to task completion to information retrieval.
While the paper provides a solid conceptual foundation and some illustrative examples, further research and evaluation will be needed to fully validate the practical impact of StructuredRAG. Nevertheless, this work represents an important step forward in the ongoing effort to bridge the gap between the capabilities of large language models and the needs and expectations of human users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
217
StructuredRAG: JSON Response Formatting with Large Language Models
Connor Shorten, Charles Pierse, Thomas Benjamin Smith, Erika Cardenas, Akanksha Sharma, John Trengrove, Bob van Luijt
The ability of Large Language Models (LLMs) to generate structured outputs, such as JSON, is crucial for their use in Compound AI Systems. However, evaluating and improving this capability remains challenging. In this work, we introduce StructuredRAG, a benchmark of six tasks designed to assess LLMs' proficiency in following response format instructions. We evaluate two state-of-the-art LLMs, Gemini 1.5 Pro and Llama 3 8B-instruct with 4-bit quantization using two distinct prompting strategies. We introduce these prompting strategies as f-String and Follow the Format (FF) prompting. Across 24 experiments, we find an average success rate of 82.55%. We further find a high variance in performance across tasks, models, and prompting strategies with success rates ranging from 0 to 100%. We find that Llama 3 8B-instruct often performs competitively with Gemini 1.5 Pro. We observe that task complexity significantly influences performance, with tasks involving lists or composite object outputs proving more challenging. Our findings highlight the need for further research into improving the reliability and consistency of structured output generation in LLMs. We have open-sourced our experimental code and results at github.com/weaviate/structured-rag.
Read more8/22/2024

0
ERATTA: Extreme RAG for Table To Answers with Large Language Models
Sohini Roychowdhury, Marko Krema, Anvar Mahammad, Brian Moore, Arijit Mukherjee, Punit Prakashchandra
Large language models (LLMs) with retrieval augmented-generation (RAG) have been the optimal choice for scalable generative AI solutions in the recent past. Although RAG implemented with AI agents (agentic-RAG) has been recently popularized, its suffers from unstable cost and unreliable performances for Enterprise-level data-practices. Most existing use-cases that incorporate RAG with LLMs have been either generic or extremely domain specific, thereby questioning the scalability and generalizability of RAG-LLM approaches. In this work, we propose a unique LLM-based system where multiple LLMs can be invoked to enable data authentication, user-query routing, data-retrieval and custom prompting for question-answering capabilities from Enterprise-data tables. The source tables here are highly fluctuating and large in size and the proposed framework enables structured responses in under 10 seconds per query. Additionally, we propose a five metric scoring module that detects and reports hallucinations in the LLM responses. Our proposed system and scoring metrics achieve >90% confidence scores across hundreds of user queries in the sustainability, financial health and social media domains. Extensions to the proposed extreme RAG architectures can enable heterogeneous source querying using LLMs.
Read more9/4/2024
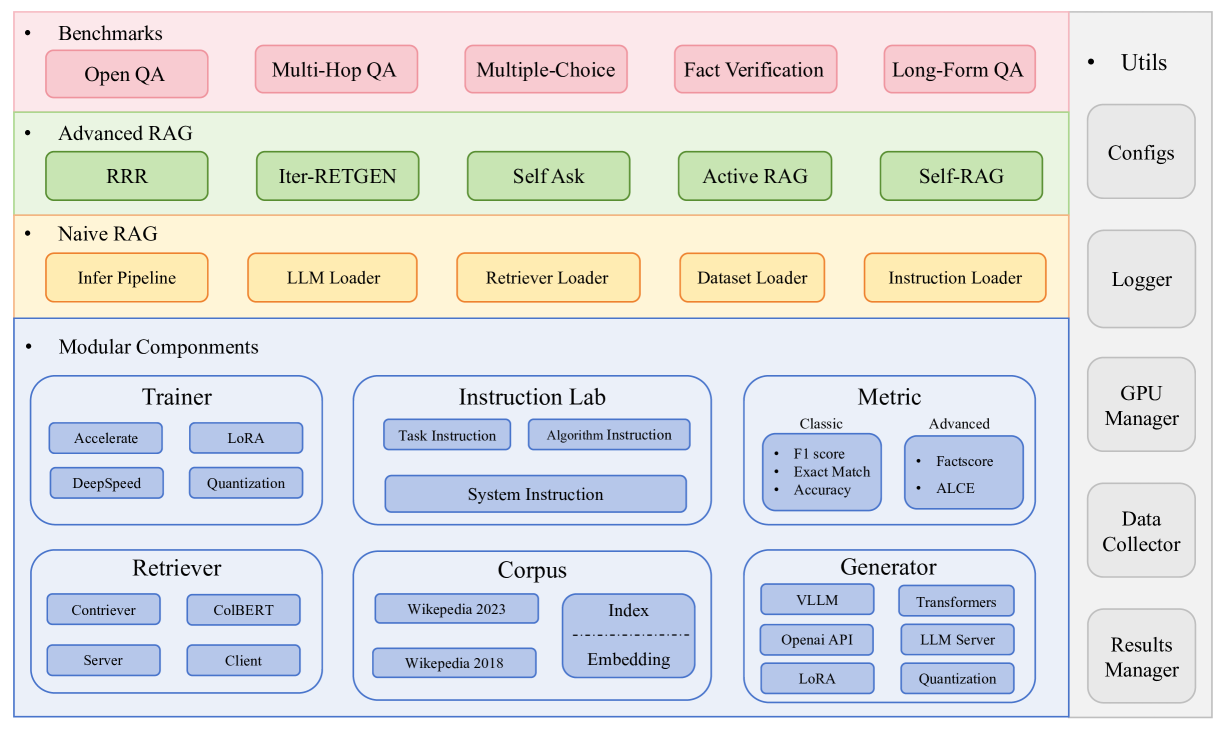
0
RAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented Generation
Xuanwang Zhang, Yunze Song, Yidong Wang, Shuyun Tang, Xinfeng Li, Zhengran Zeng, Zhen Wu, Wei Ye, Wenyuan Xu, Yue Zhang, Xinyu Dai, Shikun Zhang, Qingsong Wen
Large Language Models (LLMs) demonstrate human-level capabilities in dialogue, reasoning, and knowledge retention. However, even the most advanced LLMs face challenges such as hallucinations and real-time updating of their knowledge. Current research addresses this bottleneck by equipping LLMs with external knowledge, a technique known as Retrieval Augmented Generation (RAG). However, two key issues constrained the development of RAG. First, there is a growing lack of comprehensive and fair comparisons between novel RAG algorithms. Second, open-source tools such as LlamaIndex and LangChain employ high-level abstractions, which results in a lack of transparency and limits the ability to develop novel algorithms and evaluation metrics. To close this gap, we introduce RAGLAB, a modular and research-oriented open-source library. RAGLAB reproduces 6 existing algorithms and provides a comprehensive ecosystem for investigating RAG algorithms. Leveraging RAGLAB, we conduct a fair comparison of 6 RAG algorithms across 10 benchmarks. With RAGLAB, researchers can efficiently compare the performance of various algorithms and develop novel algorithms.
Read more9/10/2024

0
Evaluating Quality of Answers for Retrieval-Augmented Generation: A Strong LLM Is All You Need
Yang Wang, Alberto Garcia Hernandez, Roman Kyslyi, Nicholas Kersting
We present a comprehensive study of answer quality evaluation in Retrieval-Augmented Generation (RAG) applications using vRAG-Eval, a novel grading system that is designed to assess correctness, completeness, and honesty. We further map the grading of quality aspects aforementioned into a binary score, indicating an accept or reject decision, mirroring the intuitive thumbs-up or thumbs-down gesture commonly used in chat applications. This approach suits factual business settings where a clear decision opinion is essential. Our assessment applies vRAG-Eval to two Large Language Models (LLMs), evaluating the quality of answers generated by a vanilla RAG application. We compare these evaluations with human expert judgments and find a substantial alignment between GPT-4's assessments and those of human experts, reaching 83% agreement on accept or reject decisions. This study highlights the potential of LLMs as reliable evaluators in closed-domain, closed-ended settings, particularly when human evaluations require significant resources.
Read more7/8/2024