STRUM-LLM: Attributed and Structured Contrastive Summarization

0
Sign in to get full access
Overview
- This paper proposes STRUM-LLM, a novel method for generating attributed and structured contrastive summaries from large language models.
- The method aims to produce summaries that highlight key differences between two or more text inputs in a structured and interpretable way.
- STRUM-LLM leverages language models to identify salient attributes and generate contrastive bullet points that contrast the inputs.
Plain English Explanation
STRUM-LLM is a new technique that can analyze multiple pieces of text and summarize the key differences between them in a clear and organized way. Imagine you have two articles on the same topic - STRUM-LLM could review the articles and produce a summary that points out the main ways they differ, such as their perspectives, the facts they emphasize, or the conclusions they reach. This can be very helpful for quickly understanding how texts contrast with one another.
The method works by using powerful language models to identify the most important attributes or aspects of the input texts. It then generates concise bullet points that directly compare and contrast those attributes across the texts. This structured, attribute-based approach makes the summaries easier to understand and more informative than simply listing general differences.
This capability could be useful in many scenarios, such as comparing news articles on a current event, reviewing opposing arguments on a policy issue, or summarizing the key ways that scientific papers on the same topic reach different conclusions. By highlighting the most salient differences, STRUM-LLM can help readers rapidly grasp the core contrasts between texts without having to closely read each one.
Technical Explanation
STRUM-LLM is composed of three main components. First, it uses a language model to identify the most salient attributes or characteristics of each input text. This could include things like the key topics discussed, the dominant sentiment or tone, or the central claims or arguments made.
Next, STRUM-LLM generates contrastive bullet points that directly compare and contrast the attributes identified across the input texts. For example, it might note that "Text A emphasizes the economic impacts, while Text B focuses more on the environmental implications."
Finally, the method structures the summaries in a tabular format, with the attributes serving as rows and the input texts as columns. This helps preserve the interpretability and clarity of the contrastive summaries.
STRUM-LLM was evaluated on several benchmark datasets and was shown to outperform existing contrastive summarization approaches. The structured and attributed nature of the summaries was found to make them more informative and easier for humans to understand compared to more generic difference-highlighting.
Critical Analysis
The authors note that STRUM-LLM relies on the quality and capabilities of the underlying language model, so its performance may be limited by current model limitations. Additionally, the method requires that the input texts share a common set of salient attributes, which may not always be the case.
One potential issue not addressed in the paper is the risk of STRUM-LLM highlighting spurious or unimportant differences between texts, rather than the truly meaningful contrasts. Further research may be needed to ensure the summaries focus on the most substantive and relevant differences.
Overall, STRUM-LLM represents an innovative approach to contrastive summarization that could have valuable applications, particularly as language models continue to improve. However, as with any new technique, there are areas where further development and testing would be beneficial.
Conclusion
STRUM-LLM provides a novel method for generating structured, attributed, and contrastive summaries from large language models. By identifying key attributes and systematically comparing them across input texts, the technique can produce informative summaries that highlight the most salient differences. This capability could be particularly useful for tasks like reviewing opposing arguments, comparing news coverage, or synthesizing insights from related research papers. While the approach has some limitations, it represents an important step forward in making the outputs of powerful language models more interpretable and actionable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
STRUM-LLM: Attributed and Structured Contrastive Summarization
Beliz Gunel, James B. Wendt, Jing Xie, Yichao Zhou, Nguyen Vo, Zachary Fisher, Sandeep Tata
Users often struggle with decision-making between two options (A vs B), as it usually requires time-consuming research across multiple web pages. We propose STRUM-LLM that addresses this challenge by generating attributed, structured, and helpful contrastive summaries that highlight key differences between the two options. STRUM-LLM identifies helpful contrast: the specific attributes along which the two options differ significantly and which are most likely to influence the user's decision. Our technique is domain-agnostic, and does not require any human-labeled data or fixed attribute list as supervision. STRUM-LLM attributes all extractions back to the input sources along with textual evidence, and it does not have a limit on the length of input sources that it can process. STRUM-LLM Distilled has 100x more throughput than the models with comparable performance while being 10x smaller. In this paper, we provide extensive evaluations for our method and lay out future directions for our currently deployed system.
Read more4/1/2024

0
A Comparative Study of Quality Evaluation Methods for Text Summarization
Huyen Nguyen, Haihua Chen, Lavanya Pobbathi, Junhua Ding
Evaluating text summarization has been a challenging task in natural language processing (NLP). Automatic metrics which heavily rely on reference summaries are not suitable in many situations, while human evaluation is time-consuming and labor-intensive. To bridge this gap, this paper proposes a novel method based on large language models (LLMs) for evaluating text summarization. We also conducts a comparative study on eight automatic metrics, human evaluation, and our proposed LLM-based method. Seven different types of state-of-the-art (SOTA) summarization models were evaluated. We perform extensive experiments and analysis on datasets with patent documents. Our results show that LLMs evaluation aligns closely with human evaluation, while widely-used automatic metrics such as ROUGE-2, BERTScore, and SummaC do not and also lack consistency. Based on the empirical comparison, we propose a LLM-powered framework for automatically evaluating and improving text summarization, which is beneficial and could attract wide attention among the community.
Read more7/2/2024
0
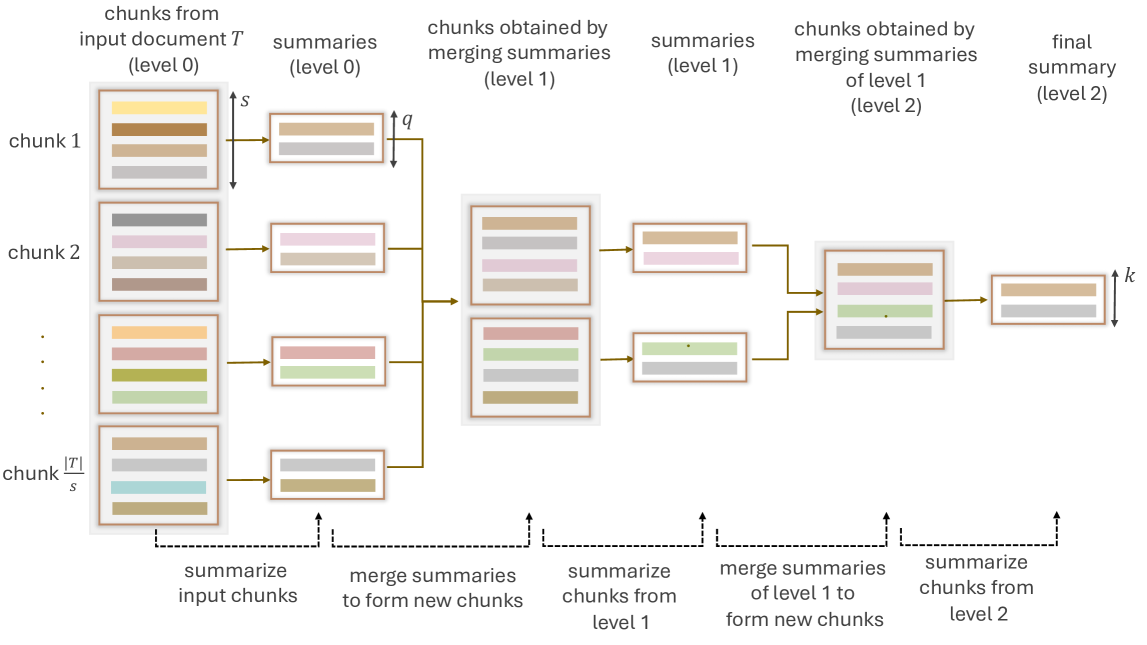
LaMSUM: A Novel Framework for Extractive Summarization of User Generated Content using LLMs
Garima Chhikara, Anurag Sharma, V. Gurucharan, Kripabandhu Ghosh, Abhijnan Chakraborty
Large Language Models (LLMs) have demonstrated impressive performance across a wide range of NLP tasks, including summarization. LLMs inherently produce abstractive summaries by paraphrasing the original text, while the generation of extractive summaries - selecting specific subsets from the original text - remains largely unexplored. LLMs have a limited context window size, restricting the amount of data that can be processed at once. We tackle this challenge by introducing LaMSUM, a novel multi-level framework designed to generate extractive summaries from large collections of user-generated text using LLMs. LaMSUM integrates summarization with different voting methods to achieve robust summaries. Extensive evaluation using four popular LLMs (Llama 3, Mixtral, Gemini, GPT-4o) demonstrates that LaMSUM outperforms state-of-the-art extractive summarization methods. Overall, this work represents one of the first attempts to achieve extractive summarization by leveraging the power of LLMs, and is likely to spark further interest within the research community.
Read more8/26/2024

0
MixSumm: Topic-based Data Augmentation using LLMs for Low-resource Extractive Text Summarization
Gaurav Sahu, Issam H. Laradji
Low-resource extractive text summarization is a vital but heavily underexplored area of research. Prior literature either focuses on abstractive text summarization or prompts a large language model (LLM) like GPT-3 directly to generate summaries. In this work, we propose MixSumm for low-resource extractive text summarization. Specifically, MixSumm prompts an open-source LLM, LLaMA-3-70b, to generate documents that mix information from multiple topics as opposed to generating documents without mixup, and then trains a summarization model on the generated dataset. We use ROUGE scores and L-Eval, a reference-free LLaMA-3-based evaluation method to measure the quality of generated summaries. We conduct extensive experiments on a challenging text summarization benchmark comprising the TweetSumm, WikiHow, and ArXiv/PubMed datasets and show that our LLM-based data augmentation framework outperforms recent prompt-based approaches for low-resource extractive summarization. Additionally, our results also demonstrate effective knowledge distillation from LLaMA-3-70b to a small BERT-based extractive summarizer.
Read more7/11/2024