Student Answer Forecasting: Transformer-Driven Answer Choice Prediction for Language Learning

0

Sign in to get full access
Methodology
Overview
- This paper presents a transformer-based model for predicting student answer choices in language learning applications.
- The model aims to forecast the likelihood of a student selecting a particular answer option given the question and other contextual information.
- The approach leverages large language models to capture the semantic relationships between questions, answers, and student understanding.
Plain English Explanation
The researchers have developed a machine learning model that can predict which answer a student is likely to choose when answering a language learning question. This model uses a type of artificial intelligence called a transformer, which is very good at understanding the meaning and relationships in language.
By analyzing the question, the possible answer choices, and other information about the student and the learning context, the transformer-based model can forecast which answer the student is most likely to select. This could be useful for creating more personalized and adaptive language learning experiences, where the system can anticipate student responses and provide tailored feedback or supplementary materials.
The key innovation is using powerful language models, which have been trained on massive amounts of text data, to capture the nuanced connections between questions, answers, and student understanding. This allows the model to make more accurate predictions compared to simpler approaches.
Technical Explanation
The paper describes a transformer-based architecture for predicting student answer choices in language learning assessments. The model takes as input the question stem, the available answer choices, and additional contextual features about the student and the learning environment. It then outputs the probability distribution over the possible answer options.
The core of the model is a transformer encoder that encodes the question, answers, and context into a joint representation. This allows the model to capture the semantic relationships between the various elements. The encoded representation is then passed through a prediction head to generate the final answer probabilities.
The researchers experiment with different variations of the transformer encoder, including using pre-trained language models like BERT as the base, as well as incorporating additional input features like student demographic information. They evaluate the model's performance on several benchmark datasets for student answer prediction, demonstrating improvements over existing approaches.
Critical Analysis
The paper presents a compelling approach to leveraging large language models for the task of student answer forecasting. By tapping into the rich contextual understanding of transformers, the model is able to make more nuanced predictions compared to simpler classification methods.
However, the paper does acknowledge some limitations. The model's performance is still not perfect, and it may struggle to generalize to new domains or question types beyond the specific datasets used in the experiments. Additionally, the reliance on large language models means the approach may be computationally intensive and require significant training data.
There are also open questions about the interpretability and explainability of the model's predictions. While the transformer architecture can capture complex relationships, it may be difficult to understand the precise reasoning behind the model's forecasts. Addressing this could be an area for future research.
Overall, the work represents an interesting application of state-of-the-art language models to the important problem of supporting language learning. With further refinement and exploration of the techniques, the approach has the potential to lead to more personalized and effective educational technologies.
Conclusion
This paper presents a novel transformer-based model for predicting student answer choices in language learning assessments. By leveraging the power of large language models, the approach can capture the nuanced semantic relationships between questions, answers, and student understanding to make more accurate forecasts.
While the model still has some limitations, the work demonstrates the promise of applying advanced AI techniques to enhance educational technology. With further research and development, this type of approach could lead to more personalized and adaptive language learning systems that can better support student progress and learning outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Student Answer Forecasting: Transformer-Driven Answer Choice Prediction for Language Learning
Elena Grazia Gado, Tommaso Martorella, Luca Zunino, Paola Mejia-Domenzain, Vinitra Swamy, Jibril Frej, Tanja Kaser
Intelligent Tutoring Systems (ITS) enhance personalized learning by predicting student answers to provide immediate and customized instruction. However, recent research has primarily focused on the correctness of the answer rather than the student's performance on specific answer choices, limiting insights into students' thought processes and potential misconceptions. To address this gap, we present MCQStudentBert, an answer forecasting model that leverages the capabilities of Large Language Models (LLMs) to integrate contextual understanding of students' answering history along with the text of the questions and answers. By predicting the specific answer choices students are likely to make, practitioners can easily extend the model to new answer choices or remove answer choices for the same multiple-choice question (MCQ) without retraining the model. In particular, we compare MLP, LSTM, BERT, and Mistral 7B architectures to generate embeddings from students' past interactions, which are then incorporated into a finetuned BERT's answer-forecasting mechanism. We apply our pipeline to a dataset of language learning MCQ, gathered from an ITS with over 10,000 students to explore the predictive accuracy of MCQStudentBert, which incorporates student interaction patterns, in comparison to correct answer prediction and traditional mastery-learning feature-based approaches. This work opens the door to more personalized content, modularization, and granular support.
Read more5/31/2024

0
Answer, Assemble, Ace: Understanding How Transformers Answer Multiple Choice Questions
Sarah Wiegreffe, Oyvind Tafjord, Yonatan Belinkov, Hannaneh Hajishirzi, Ashish Sabharwal
Multiple-choice question answering (MCQA) is a key competence of performant transformer language models that is tested by mainstream benchmarks. However, recent evidence shows that models can have quite a range of performance, particularly when the task format is diversified slightly (such as by shuffling answer choice order). In this work we ask: how do successful models perform formatted MCQA? We employ vocabulary projection and activation patching methods to localize key hidden states that encode relevant information for predicting the correct answer. We find that prediction of a specific answer symbol is causally attributed to a single middle layer, and specifically its multi-head self-attention mechanism. We show that subsequent layers increase the probability of the predicted answer symbol in vocabulary space, and that this probability increase is associated with a sparse set of attention heads with unique roles. We additionally uncover differences in how different models adjust to alternative symbols. Finally, we demonstrate that a synthetic task can disentangle sources of model error to pinpoint when a model has learned formatted MCQA, and show that an inability to separate answer symbol tokens in vocabulary space is a property of models unable to perform formatted MCQA tasks.
Read more7/23/2024
0
UnibucLLM: Harnessing LLMs for Automated Prediction of Item Difficulty and Response Time for Multiple-Choice Questions
Ana-Cristina Rogoz, Radu Tudor Ionescu
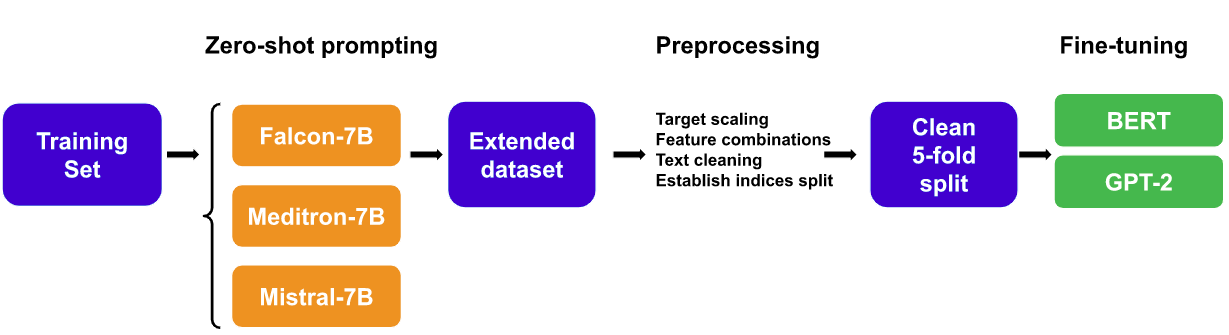
This work explores a novel data augmentation method based on Large Language Models (LLMs) for predicting item difficulty and response time of retired USMLE Multiple-Choice Questions (MCQs) in the BEA 2024 Shared Task. Our approach is based on augmenting the dataset with answers from zero-shot LLMs (Falcon, Meditron, Mistral) and employing transformer-based models based on six alternative feature combinations. The results suggest that predicting the difficulty of questions is more challenging. Notably, our top performing methods consistently include the question text, and benefit from the variability of LLM answers, highlighting the potential of LLMs for improving automated assessment in medical licensing exams. We make our code available https://github.com/ana-rogoz/BEA-2024.
Read more4/23/2024
0
A review on the use of large language models as virtual tutors
Silvia Garc'ia-M'endez, Francisco de Arriba-P'erez, Mar'ia del Carmen Somoza-L'opez
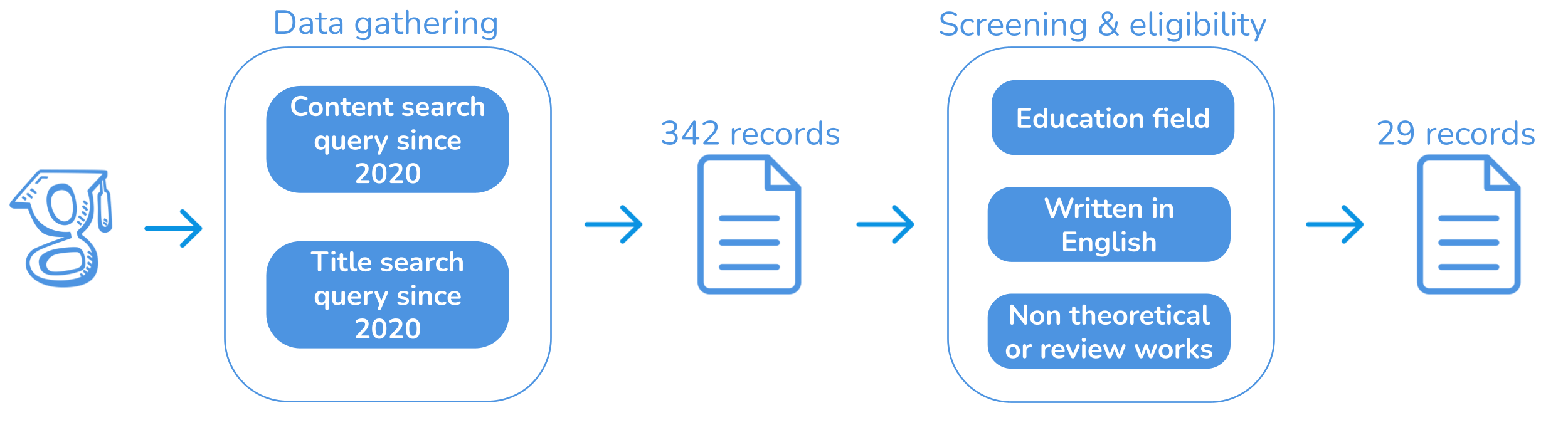
Transformer architectures contribute to managing long-term dependencies for Natural Language Processing, representing one of the most recent changes in the field. These architectures are the basis of the innovative, cutting-edge Large Language Models (LLMs) that have produced a huge buzz in several fields and industrial sectors, among the ones education stands out. Accordingly, these generative Artificial Intelligence-based solutions have directed the change in techniques and the evolution in educational methods and contents, along with network infrastructure, towards high-quality learning. Given the popularity of LLMs, this review seeks to provide a comprehensive overview of those solutions designed specifically to generate and evaluate educational materials and which involve students and teachers in their design or experimental plan. To the best of our knowledge, this is the first review of educational applications (e.g., student assessment) of LLMs. As expected, the most common role of these systems is as virtual tutors for automatic question generation. Moreover, the most popular models are GTP-3 and BERT. However, due to the continuous launch of new generative models, new works are expected to be published shortly.
Read more9/6/2024