Study on Aspect Ratio Variability toward Robustness of Vision Transformer-based Vehicle Re-identification

0

Sign in to get full access
Overview
- This paper explores the impact of aspect ratio variability on the robustness of vision transformer-based vehicle re-identification models.
- The authors investigate how varying the aspect ratio of vehicle images affects the performance of these models, which are important for applications like autonomous driving and urban surveillance.
- The findings provide insights into the design of robust and flexible vision transformer architectures that can handle diverse image inputs.
Plain English Explanation
Vehicle re-identification is the task of identifying the same vehicle across different camera views, which is crucial for applications like autonomous driving and urban surveillance. Vision transformer models have shown promising results for this task, but their performance can be sensitive to variations in the aspect ratio (the ratio of an image's width to its height) of the input vehicle images.
In this study, the researchers examine how changes in aspect ratio affect the robustness of vision transformer-based vehicle re-identification models. They experiment with different aspect ratios to understand how the models handle diverse image inputs, which is important for real-world applications where the cameras may capture vehicles at various angles and distances, resulting in varying aspect ratios.
The findings from this research provide valuable insights for designing more flexible and robust vision transformer architectures that can effectively handle the aspect ratio variability often encountered in vehicle re-identification tasks. This work contributes to the ongoing efforts to develop reliable and versatile computer vision systems for autonomous and intelligent transportation applications.
Technical Explanation
The paper investigates the impact of aspect ratio variability on the performance of vision transformer-based vehicle re-identification models. The authors conducted experiments using the VeRi-776 dataset, which contains vehicle images with diverse aspect ratios.
They trained vision transformer models with different input image aspect ratios, ranging from 1:1 to 2:1, to assess the models' robustness to aspect ratio variations. The authors evaluated the models' performance using standard metrics, such as Rank-1 accuracy and mean average precision (mAP), and analyzed the results to understand the relationship between aspect ratio and model performance.
The experimental results demonstrate that the vision transformer models exhibit a significant performance drop when the aspect ratio of the input images deviates from the training distribution. The authors also observed that the models tend to be more sensitive to aspect ratio changes in the horizontal direction (width) compared to the vertical direction (height).
Based on these findings, the researchers propose several strategies to improve the aspect ratio robustness of vision transformer-based vehicle re-identification models, including multi-scale training, dynamic aspect ratio augmentation, and architectural modifications to the vision transformer backbone.
Critical Analysis
The paper provides valuable insights into the impact of aspect ratio variability on the robustness of vision transformer-based vehicle re-identification models. The experimental results highlight the importance of accounting for diverse image inputs in the design of these models, which is crucial for real-world applications.
However, the paper could have further explored the underlying reasons for the observed sensitivity to aspect ratio changes. Providing a more detailed analysis of the model's internal representations and how they are affected by aspect ratio variations could have led to a deeper understanding of the problem and more targeted solutions.
Additionally, the paper could have compared the aspect ratio robustness of vision transformers with other popular vehicle re-identification approaches, such as convolutional neural networks, to better contextualize the findings and understand the unique challenges faced by transformer-based models.
While the proposed strategies for improving aspect ratio robustness seem promising, the paper would have benefited from a more thorough evaluation of these techniques, including their computational cost and trade-offs with other performance metrics, to provide a more comprehensive assessment of their practical applicability.
Conclusion
This study sheds light on the aspect ratio sensitivity of vision transformer-based vehicle re-identification models, an important issue for real-world applications. The findings highlight the need for developing flexible and robust vision transformer architectures that can effectively handle diverse image inputs, a crucial step towards building reliable and versatile computer vision systems for autonomous and intelligent transportation applications.
The insights and strategies presented in this paper contribute to the ongoing efforts to advance the state-of-the-art in vehicle re-identification and pave the way for more robust and adaptive vision transformer models that can operate reliably in dynamic environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Study on Aspect Ratio Variability toward Robustness of Vision Transformer-based Vehicle Re-identification
Mei Qiu, Lauren Christopher, Lingxi Li
Vision Transformers (ViTs) have excelled in vehicle re-identification (ReID) tasks. However, non-square aspect ratios of image or video input might significantly affect the re-identification performance. To address this issue, we propose a novel ViT-based ReID framework in this paper, which fuses models trained on a variety of aspect ratios. Our main contributions are threefold: (i) We analyze aspect ratio performance on VeRi-776 and VehicleID datasets, guiding input settings based on aspect ratios of original images. (ii) We introduce patch-wise mixup intra-image during ViT patchification (guided by spatial attention scores) and implement uneven stride for better object aspect ratio matching. (iii) We propose a dynamic feature fusing ReID network, enhancing model robustness. Our ReID method achieves a significantly improved mean Average Precision (mAP) of 91.0% compared to the the closest state-of-the-art (CAL) result of 80.9% on VehicleID dataset.
Read more7/11/2024

0
Optimizing ROI Benefits Vehicle ReID in ITS
Mei Qiu, Lauren Ann Christopher, Lingxi Li, Stanley Chien, Yaobin Chen
Vehicle re-identification (ReID) is a computer vision task that matches the same vehicle across different cameras or viewpoints in a surveillance system. This is crucial for Intelligent Transportation Systems (ITS), where the effectiveness is influenced by the regions from which vehicle images are cropped. This study explores whether optimal vehicle detection regions, guided by detection confidence scores, can enhance feature matching and ReID tasks. Using our framework with multiple Regions of Interest (ROIs) and lane-wise vehicle counts, we employed YOLOv8 for detection and DeepSORT for tracking across twelve Indiana Highway videos, including two pairs of videos from non-overlapping cameras. Tracked vehicle images were cropped from inside and outside the ROIs at five-frame intervals. Features were extracted using pre-trained models: ResNet50, ResNeXt50, Vision Transformer, and Swin-Transformer. Feature consistency was assessed through cosine similarity, information entropy, and clustering variance. Results showed that features from images cropped inside ROIs had higher mean cosine similarity values compared to those involving one image inside and one outside the ROIs. The most significant difference was observed during night conditions (0.7842 inside vs. 0.5 outside the ROI with Swin-Transformer) and in cross-camera scenarios (0.75 inside-inside vs. 0.52 inside-outside the ROI with Vision Transformer). Information entropy and clustering variance further supported that features in ROIs are more consistent. These findings suggest that strategically selected ROIs can enhance tracking performance and ReID accuracy in ITS.
Read more7/16/2024
0
PersonViT: Large-scale Self-supervised Vision Transformer for Person Re-Identificat
Bin Hu, Xinggang Wang, Wenyu Liu
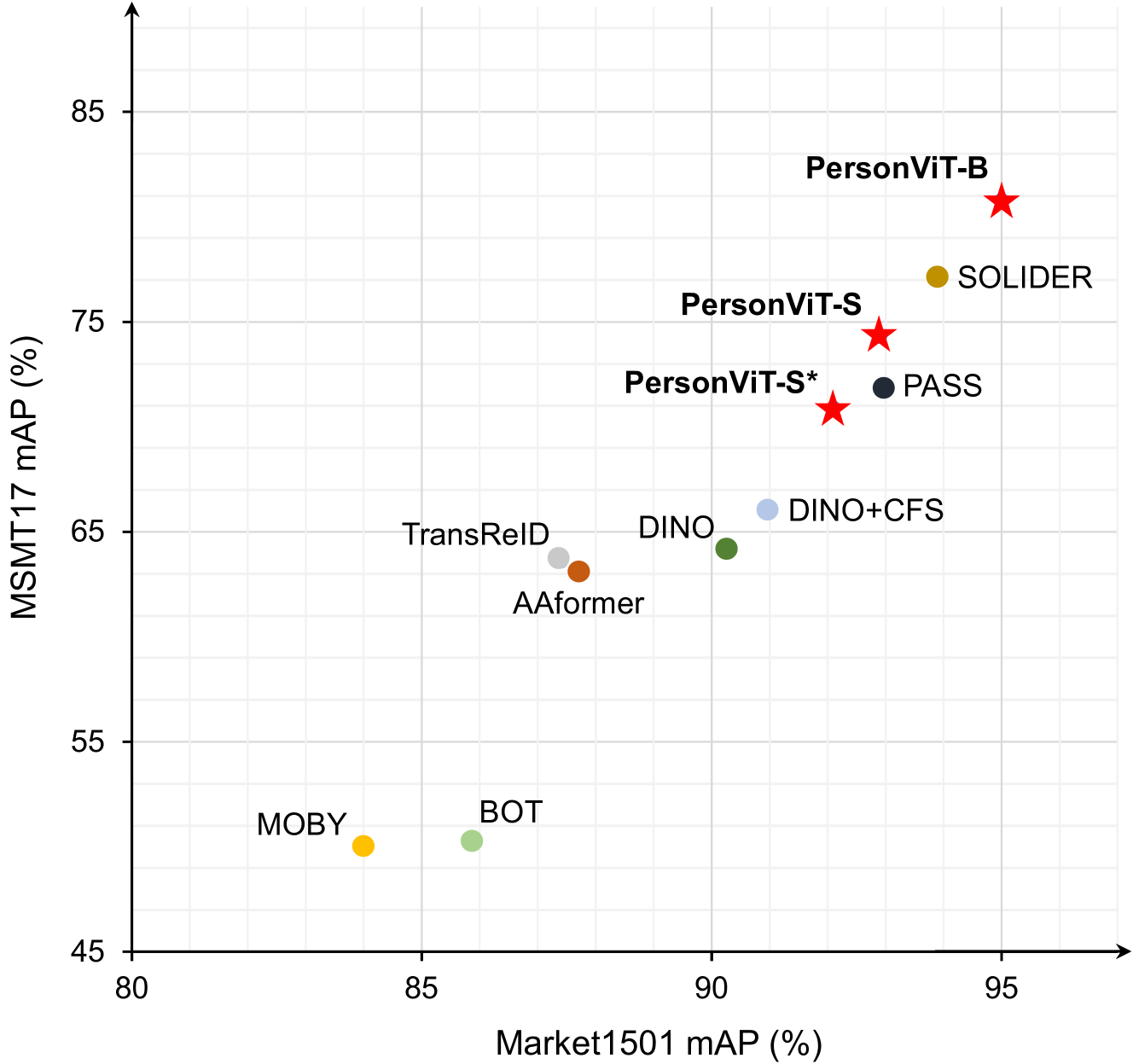
Person Re-Identification (ReID) aims to retrieve relevant individuals in non-overlapping camera images and has a wide range of applications in the field of public safety. In recent years, with the development of Vision Transformer (ViT) and self-supervised learning techniques, the performance of person ReID based on self-supervised pre-training has been greatly improved. Person ReID requires extracting highly discriminative local fine-grained features of the human body, while traditional ViT is good at extracting context-related global features, making it difficult to focus on local human body features. To this end, this article introduces the recently emerged Masked Image Modeling (MIM) self-supervised learning method into person ReID, and effectively extracts high-quality global and local features through large-scale unsupervised pre-training by combining masked image modeling and discriminative contrastive learning, and then conducts supervised fine-tuning training in the person ReID task. This person feature extraction method based on ViT with masked image modeling (PersonViT) has the good characteristics of unsupervised, scalable, and strong generalization capabilities, overcoming the problem of difficult annotation in supervised person ReID, and achieves state-of-the-art results on publicly available benchmark datasets, including MSMT17, Market1501, DukeMTMC-reID, and Occluded-Duke. The code and pre-trained models of the PersonViT method are released at url{https://github.com/hustvl/PersonViT} to promote further research in the person ReID field.
Read more8/21/2024
🖼️
0
VehicleGAN: Pair-flexible Pose Guided Image Synthesis for Vehicle Re-identification
Baolu Li, Ping Liu, Lan Fu, Jinlong Li, Jianwu Fang, Zhigang Xu, Hongkai Yu
Vehicle Re-identification (Re-ID) has been broadly studied in the last decade; however, the different camera view angle leading to confused discrimination in the feature subspace for the vehicles of various poses, is still challenging for the Vehicle Re-ID models in the real world. To promote the Vehicle Re-ID models, this paper proposes to synthesize a large number of vehicle images in the target pose, whose idea is to project the vehicles of diverse poses into the unified target pose so as to enhance feature discrimination. Considering that the paired data of the same vehicles in different traffic surveillance cameras might be not available in the real world, we propose the first Pair-flexible Pose Guided Image Synthesis method for Vehicle Re-ID, named as VehicleGAN in this paper, which works for both supervised and unsupervised settings without the knowledge of geometric 3D models. Because of the feature distribution difference between real and synthetic data, simply training a traditional metric learning based Re-ID model with data-level fusion (i.e., data augmentation) is not satisfactory, therefore we propose a new Joint Metric Learning (JML) via effective feature-level fusion from both real and synthetic data. Intensive experimental results on the public VeRi-776 and VehicleID datasets prove the accuracy and effectiveness of our proposed VehicleGAN and JML.
Read more4/17/2024