PersonViT: Large-scale Self-supervised Vision Transformer for Person Re-Identificat

0
Sign in to get full access
Overview
- PersonViT is a large-scale self-supervised Vision Transformer (ViT) model for person re-identification (re-ID)
- It is pre-trained on a massive amount of unlabeled person images to learn powerful visual representations
- The learned representations can then be fine-tuned for person re--ID tasks, achieving state-of-the-art performance
Plain English Explanation
PersonViT is a new type of deep learning model that has been designed for the task of person re-identification. Person re-identification is the process of matching a person's image across different cameras or viewpoints.
The key innovation of PersonViT is that it uses a Vision Transformer architecture, which is a type of deep learning model that is particularly well-suited for processing and understanding visual information.
Unlike traditional convolutional neural networks, which look at images in a grid-like fashion, Vision Transformers break the image down into smaller patches and process them in a more flexible, context-aware way. This allows them to better capture the complex and variable patterns found in real-world person images.
The PersonViT model is first pre-trained on a massive dataset of unlabeled person images. This pre-training allows the model to learn powerful visual representations without the need for manual labeling.
These learned representations can then be fine-tuned on smaller, labeled person re-ID datasets to achieve state-of-the-art performance on this task. The pre-training step is crucial, as it allows the model to leverage a much larger and richer dataset than would be possible with the labeled data alone.
Technical Explanation
The authors of the paper propose PersonViT, a large-scale self-supervised Vision Transformer (ViT) model for person re-identification (re-ID). The core idea is to pre-train the ViT model on a massive amount of unlabeled person images in a self-supervised manner, and then fine-tune the learned representations for person re--ID tasks.
The PersonViT architecture is based on the standard ViT design, where the input image is divided into small patches, which are then processed by a series of transformer encoder layers. The model is pre-trained using a contrastive loss, which encourages the representation of similar person images to be close in the latent space, while dissimilar images are pushed apart.
The pre-training is performed on a large-scale dataset of 130 million person images crawled from the internet. This massive dataset allows the model to learn robust and generalizable visual representations of persons, without the need for manual labeling.
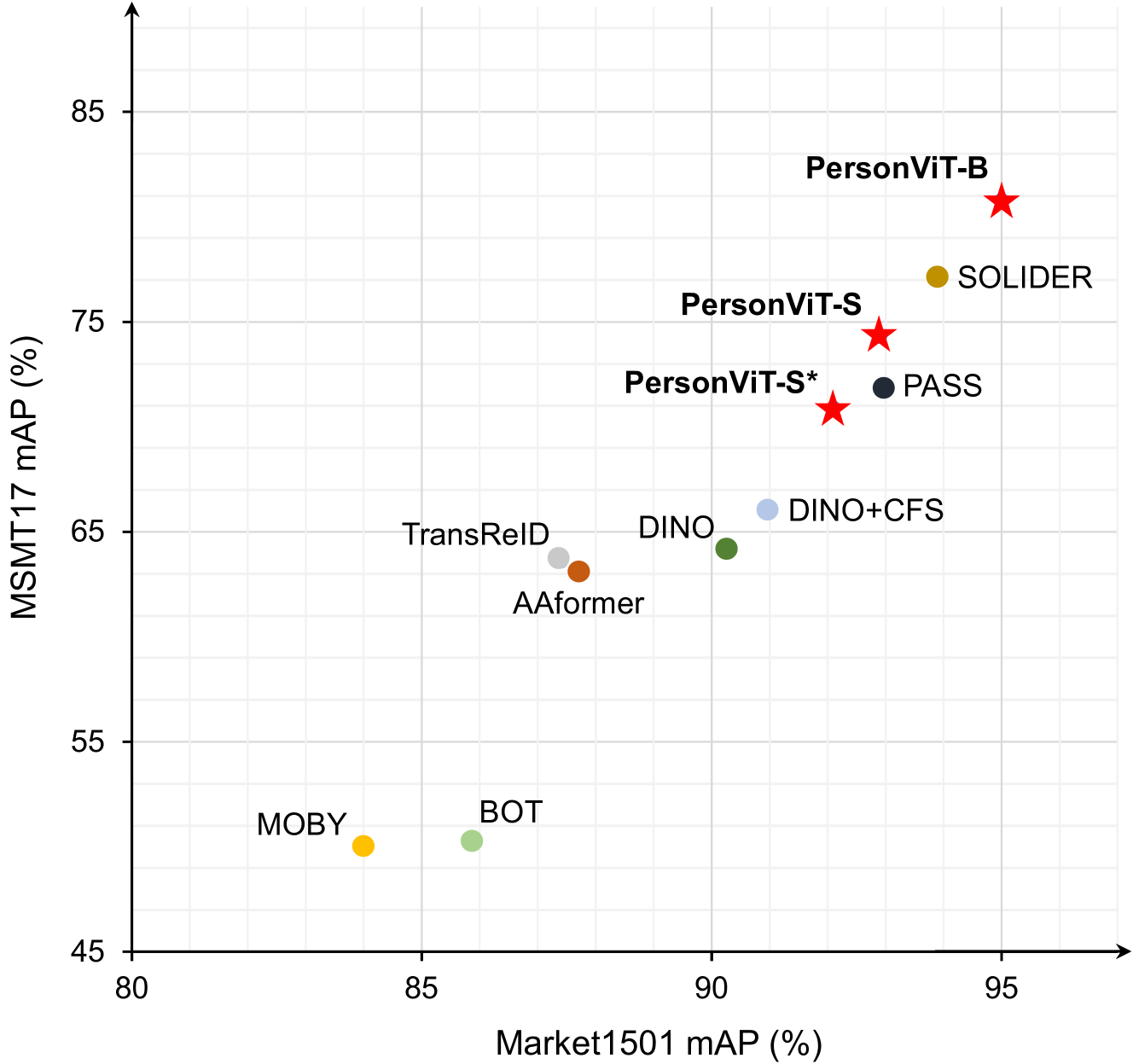
After pre-training, the PersonViT model can be fine-tuned on smaller, labeled person re-ID datasets. The authors show that this two-stage training procedure leads to state-of-the-art performance on several person re-ID benchmarks, outperforming previous methods that rely on supervised learning or weaker self-supervision schemes.
Critical Analysis
The key strength of PersonViT is its ability to leverage large-scale, unlabeled data to learn powerful visual representations for person re-ID. This is a significant advantage over previous methods that required expensive manual labeling of training data.
However, the paper does not address some potential limitations and areas for further research. For example, the pre-training dataset may contain biases or underrepresented groups, which could lead to unfairness or performance disparities when the model is deployed in real-world scenarios.
Additionally, the computational and storage requirements of the pre-trained PersonViT model may be prohibitive for some applications, especially on resource-constrained devices. The authors could have explored ways to distill the knowledge from the large model into more compact and efficient versions.
Overall, PersonViT represents an impressive advance in self-supervised learning for computer vision, with the potential to significantly improve the performance and accessibility of person re-ID systems. However, further research is needed to address the model's limitations and ensure its fair and responsible deployment.
Conclusion
PersonViT is a novel self-supervised Vision Transformer model that demonstrates state-of-the-art performance on person re-identification tasks. By leveraging a massive, unlabeled dataset of person images during pre-training, the model is able to learn robust and generalizable visual representations that can be effectively fine-tuned for downstream re-ID applications.
The key innovation of PersonViT is its use of a self-supervised, contrastive pre-training approach, which allows the model to discover and capture the underlying patterns and structures in person images without the need for manual labeling. This approach has the potential to significantly reduce the cost and effort required to develop high-performing person re-ID systems, with applications in surveillance, smart cities, and other domains.
While PersonViT shows promising results, further research is needed to address potential limitations, such as dataset biases and computational efficiency. Nonetheless, this work represents an important step forward in the field of self-supervised learning for computer vision, and its impact on person re-identification and beyond is likely to be substantial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PersonViT: Large-scale Self-supervised Vision Transformer for Person Re-Identificat
Bin Hu, Xinggang Wang, Wenyu Liu
Person Re-Identification (ReID) aims to retrieve relevant individuals in non-overlapping camera images and has a wide range of applications in the field of public safety. In recent years, with the development of Vision Transformer (ViT) and self-supervised learning techniques, the performance of person ReID based on self-supervised pre-training has been greatly improved. Person ReID requires extracting highly discriminative local fine-grained features of the human body, while traditional ViT is good at extracting context-related global features, making it difficult to focus on local human body features. To this end, this article introduces the recently emerged Masked Image Modeling (MIM) self-supervised learning method into person ReID, and effectively extracts high-quality global and local features through large-scale unsupervised pre-training by combining masked image modeling and discriminative contrastive learning, and then conducts supervised fine-tuning training in the person ReID task. This person feature extraction method based on ViT with masked image modeling (PersonViT) has the good characteristics of unsupervised, scalable, and strong generalization capabilities, overcoming the problem of difficult annotation in supervised person ReID, and achieves state-of-the-art results on publicly available benchmark datasets, including MSMT17, Market1501, DukeMTMC-reID, and Occluded-Duke. The code and pre-trained models of the PersonViT method are released at url{https://github.com/hustvl/PersonViT} to promote further research in the person ReID field.
Read more8/21/2024
0
Liveness Detection in Computer Vision: Transformer-based Self-Supervised Learning for Face Anti-Spoofing
Arman Keresh, Pakizar Shamoi
Face recognition systems are increasingly used in biometric security for convenience and effectiveness. However, they remain vulnerable to spoofing attacks, where attackers use photos, videos, or masks to impersonate legitimate users. This research addresses these vulnerabilities by exploring the Vision Transformer (ViT) architecture, fine-tuned with the DINO framework. The DINO framework facilitates self-supervised learning, enabling the model to learn distinguishing features from unlabeled data. We compared the performance of the proposed fine-tuned ViT model using the DINO framework against a traditional CNN model, EfficientNet b2, on the face anti-spoofing task. Numerous tests on standard datasets show that the ViT model performs better than the CNN model in terms of accuracy and resistance to different spoofing methods. Additionally, we collected our own dataset from a biometric application to validate our findings further. This study highlights the superior performance of transformer-based architecture in identifying complex spoofing cues, leading to significant advancements in biometric security.
Read more6/21/2024
👀
0
Centroid-centered Modeling for Efficient Vision Transformer Pre-training
Xin Yan, Zuchao Li, Lefei Zhang
Masked Image Modeling (MIM) is a new self-supervised vision pre-training paradigm using a Vision Transformer (ViT). Previous works can be pixel-based or token-based, using original pixels or discrete visual tokens from parametric tokenizer models, respectively. Our proposed centroid-based approach, CCViT, leverages k-means clustering to obtain centroids for image modeling without supervised training of the tokenizer model, which only takes seconds to create. This non-parametric centroid tokenizer only takes seconds to create and is faster for token inference. The centroids can represent both patch pixels and index tokens with the property of local invariance. Specifically, we adopt patch masking and centroid replacing strategies to construct corrupted inputs, and two stacked encoder blocks to predict corrupted patch tokens and reconstruct original patch pixels. Experiments show that our CCViT achieves 84.4% top-1 accuracy on ImageNet-1K classification with ViT-B and 86.0% with ViT-L. We also transfer our pre-trained model to other downstream tasks. Our approach achieves competitive results with recent baselines without external supervision and distillation training from other models.
Read more8/2/2024

0
Learning Commonality, Divergence and Variety for Unsupervised Visible-Infrared Person Re-identification
Jiangming Shi, Xiangbo Yin, Yaoxing Wang, Xiaofeng Liu, Yuan Xie, Yanyun Qu
Unsupervised visible-infrared person re-identification (USVI-ReID) aims to match specified people in infrared images to visible images without annotation, and vice versa. USVI-ReID is a challenging yet under-explored task. Most existing methods address the USVI-ReID problem using cluster-based contrastive learning, which simply employs the cluster center as a representation of a person. However, the cluster center primarily focuses on shared information, overlooking disparity. To address the problem, we propose a Progressive Contrastive Learning with Multi-Prototype (PCLMP) method for USVI-ReID. In brief, we first generate the hard prototype by selecting the sample with the maximum distance from the cluster center. This hard prototype is used in the contrastive loss to emphasize disparity. Additionally, instead of rigidly aligning query images to a specific prototype, we generate the dynamic prototype by randomly picking samples within a cluster. This dynamic prototype is used to retain the natural variety of features while reducing instability in the simultaneous learning of both common and disparate information. Finally, we introduce a progressive learning strategy to gradually shift the model's attention towards hard samples, avoiding cluster deterioration. Extensive experiments conducted on the publicly available SYSU-MM01 and RegDB datasets validate the effectiveness of the proposed method. PCLMP outperforms the existing state-of-the-art method with an average mAP improvement of 3.9%. The source codes will be released.
Read more5/28/2024