A Study on Large Language Models' Limitations in Multiple-Choice Question Answering

0
💬
Sign in to get full access
Overview
- The widespread adoption of Large Language Models (LLMs) has become commonplace, particularly with the emergence of open-source models.
- Smaller models are well-suited for integration into consumer devices and are frequently used as standalone solutions or as subroutines in various AI tasks.
- Despite their ubiquitous use, there is no systematic analysis of their specific capabilities and limitations.
Plain English Explanation
Large Language Models (LLMs) are a type of artificial intelligence that can understand and generate human-like language. These models have become very popular, especially as open-source versions have become available. Smaller versions of these models are also being used in consumer products and as part of other AI systems.
However, even though these models are used widely, there hasn't been a detailed study of what they can and cannot do. In this research, the authors looked at one of the most common tasks these models are used for - answering multiple-choice questions (MCQs).
Technical Explanation
The researchers analyzed 26 small, open-source LLMs to see how well they could perform on MCQ tasks. They found that:
- 65% of the models did not understand the task at all and could not select a proper answer from the choices provided.
- Only 4 models were able to correctly select an answer from the given options.
- Only 5 of the models were able to provide the correct answer regardless of the order the choices were presented in.
These results are quite concerning, given how widely MCQ tests are used to evaluate the capabilities of LLMs in various fields. The researchers recommend caution and thorough testing of a model's task understanding before using MCQ evaluations.
Critical Analysis
The findings of this study raise serious doubts about the reliability of using MCQ tests to assess the capabilities of LLMs. The fact that the majority of the models tested did not even understand the task is a significant limitation that should be considered when employing these models, especially in high-stakes applications.
While the study provides a comprehensive analysis, it would be valuable to understand the specific reasons why most of the models struggled with the MCQ task. Exploring the model architectures, training data, or other factors that contribute to this limitation could help develop more robust and reliable LLMs for MCQ-based evaluations.
Additionally, further research could investigate the performance of these models on other common language tasks to gain a more holistic understanding of their strengths and weaknesses. Comparing the results across different tasks may reveal patterns or tradeoffs that could guide the development and deployment of LLMs.
Conclusion
This study highlights the importance of thoroughly testing the capabilities of LLMs before relying on them for critical applications, such as educational assessments or decision-making processes. The findings suggest that using MCQ tests to evaluate these models may not be a reliable approach, and more comprehensive evaluations are needed to ensure the models are truly understanding the task at hand. As the adoption of LLMs continues to grow, it is crucial to maintain a critical and cautious approach to their use, ensuring that their limitations are well understood and addressed.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
A Study on Large Language Models' Limitations in Multiple-Choice Question Answering
Aisha Khatun, Daniel G. Brown
The widespread adoption of Large Language Models (LLMs) has become commonplace, particularly with the emergence of open-source models. More importantly, smaller models are well-suited for integration into consumer devices and are frequently employed either as standalone solutions or as subroutines in various AI tasks. Despite their ubiquitous use, there is no systematic analysis of their specific capabilities and limitations. In this study, we tackle one of the most widely used tasks - answering Multiple Choice Question (MCQ). We analyze 26 small open-source models and find that 65% of the models do not understand the task, only 4 models properly select an answer from the given choices, and only 5 of these models are choice order independent. These results are rather alarming given the extensive use of MCQ tests with these models. We recommend exercising caution and testing task understanding before using MCQ to evaluate LLMs in any field whatsoever.
Read more8/16/2024

0
Beyond the Answers: Reviewing the Rationality of Multiple Choice Question Answering for the Evaluation of Large Language Models
Haochun Wang, Sendong Zhao, Zewen Qiang, Nuwa Xi, Bing Qin, Ting Liu
In the field of natural language processing (NLP), Large Language Models (LLMs) have precipitated a paradigm shift, markedly enhancing performance in natural language generation tasks. Despite these advancements, the comprehensive evaluation of LLMs remains an inevitable challenge for the community. Recently, the utilization of Multiple Choice Question Answering (MCQA) as a benchmark for LLMs has gained considerable traction. This study first investigates the limitations of MCQA as an evaluation method for LLMs and then analyzes the fundamental reason for the limitations of MCQA, that while LLMs may select the correct answers, it is possible that they also recognize other wrong options as correct. Finally, we propose a dataset augmenting method for Multiple-Choice Questions (MCQs), MCQA+, that can more accurately reflect the performance of the model, which underscores the need for more robust evaluation mechanisms in assessing the performance of LLMs.
Read more5/31/2024
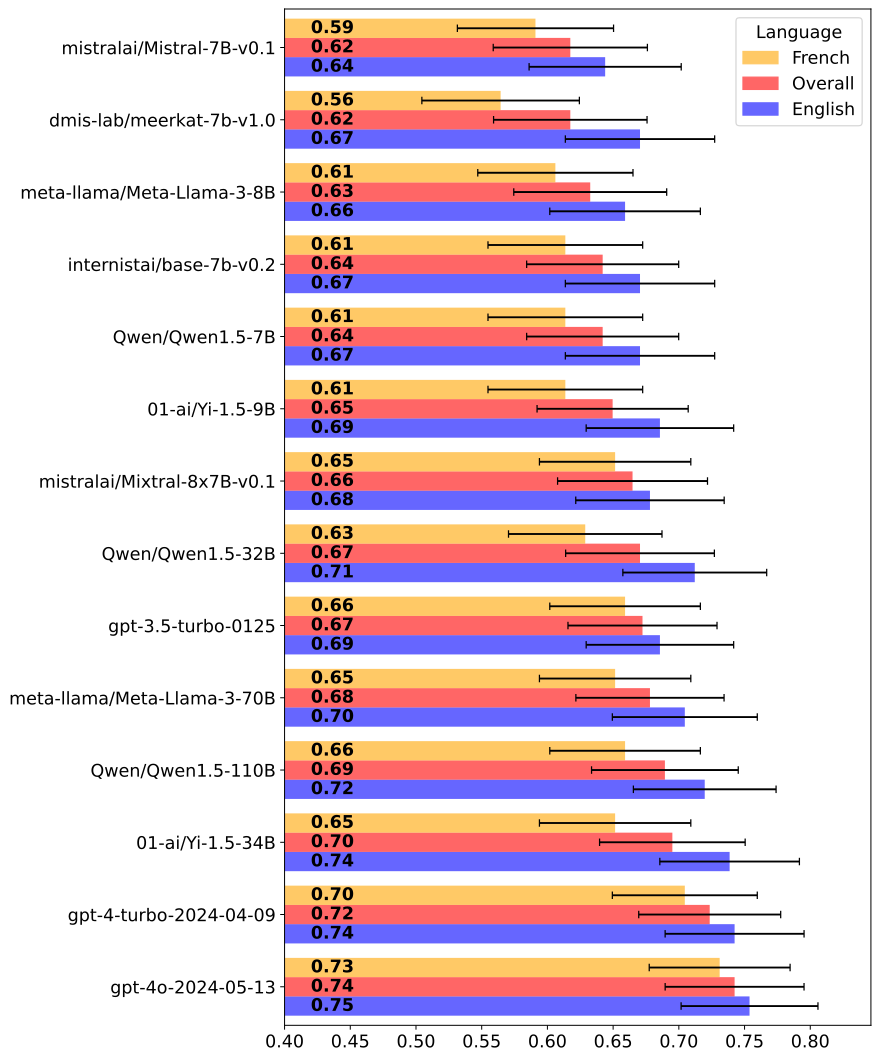
0
Multiple Choice Questions and Large Languages Models: A Case Study with Fictional Medical Data
Maxime Griot, Jean Vanderdonckt, Demet Yuksel, Coralie Hemptinne
Large Language Models (LLMs) like ChatGPT demonstrate significant potential in the medical field, often evaluated using multiple-choice questions (MCQs) similar to those found on the USMLE. Despite their prevalence in medical education, MCQs have limitations that might be exacerbated when assessing LLMs. To evaluate the effectiveness of MCQs in assessing the performance of LLMs, we developed a fictional medical benchmark focused on a non-existent gland, the Glianorex. This approach allowed us to isolate the knowledge of the LLM from its test-taking abilities. We used GPT-4 to generate a comprehensive textbook on the Glianorex in both English and French and developed corresponding multiple-choice questions in both languages. We evaluated various open-source, proprietary, and domain-specific LLMs using these questions in a zero-shot setting. The models achieved average scores around 67%, with minor performance differences between larger and smaller models. Performance was slightly higher in English than in French. Fine-tuned medical models showed some improvement over their base versions in English but not in French. The uniformly high performance across models suggests that traditional MCQ-based benchmarks may not accurately measure LLMs' clinical knowledge and reasoning abilities, instead highlighting their pattern recognition skills. This study underscores the need for more robust evaluation methods to better assess the true capabilities of LLMs in medical contexts.
Read more6/5/2024
0
Can multiple-choice questions really be useful in detecting the abilities of LLMs?
Wangyue Li, Liangzhi Li, Tong Xiang, Xiao Liu, Wei Deng, Noa Garcia
Multiple-choice questions (MCQs) are widely used in the evaluation of large language models (LLMs) due to their simplicity and efficiency. However, there are concerns about whether MCQs can truly measure LLM's capabilities, particularly in knowledge-intensive scenarios where long-form generation (LFG) answers are required. The misalignment between the task and the evaluation method demands a thoughtful analysis of MCQ's efficacy, which we undertake in this paper by evaluating nine LLMs on four question-answering (QA) datasets in two languages: Chinese and English. We identify a significant issue: LLMs exhibit an order sensitivity in bilingual MCQs, favoring answers located at specific positions, i.e., the first position. We further quantify the gap between MCQs and long-form generation questions (LFGQs) by comparing their direct outputs, token logits, and embeddings. Our results reveal a relatively low correlation between answers from MCQs and LFGQs for identical questions. Additionally, we propose two methods to quantify the consistency and confidence of LLMs' output, which can be generalized to other QA evaluation benchmarks. Notably, our analysis challenges the idea that the higher the consistency, the greater the accuracy. We also find MCQs to be less reliable than LFGQs in terms of expected calibration error. Finally, the misalignment between MCQs and LFGQs is not only reflected in the evaluation performance but also in the embedding space. Our code and models can be accessed at https://github.com/Meetyou-AI-Lab/Can-MC-Evaluate-LLMs.
Read more5/24/2024