StyleMaster: Towards Flexible Stylized Image Generation with Diffusion Models

0

Sign in to get full access
Overview
• This research paper introduces a new approach called "StyleMaster" for generating stylized images using diffusion models.
• Diffusion models are a type of machine learning model that can generate new images by gradually adding noise to a clean image and then learning to reverse the process.
• StyleMaster aims to make the process of applying artistic styles to images more flexible and customizable compared to previous approaches.
Plain English Explanation
• Imagine you're an artist who wants to create a painting in a particular style, like impressionism or cubism. Traditionally, this would involve manually editing an image to apply the desired artistic style.
• With StyleMaster, the process becomes more automated. You can provide a reference image in the style you want, and the model will learn to apply that style to any new image you give it.
• This is done using a diffusion model, which starts with a noisy version of the input image and gradually refines it, step-by-step, to match the desired artistic style. The model learns to reverse the "noising" process in a way that preserves the content of the image while applying the style.
• The key advantage of StyleMaster is its flexibility. Rather than being limited to a predefined set of artistic styles, you can use any reference image to define the style you want to apply. This opens up a wide range of creative possibilities for artists and designers.
Technical Explanation
• StyleMaster is based on a diffusion model architecture, which consists of an encoder that transforms the input image into a latent representation, and a decoder that generates the stylized output image.
• The model is trained on a dataset of images paired with corresponding style reference images. During training, the model learns to predict the sequence of noise-adding and noise-removing steps that transform the input image into the desired stylized output.
• To apply a new style, the user provides a reference image, and the trained model uses this to guide the diffusion process and generate a stylized version of the input image.
• The paper introduces several technical innovations, such as a multi-scale architecture and a new strategy for incorporating style information, which help improve the quality and diversity of the generated stylized images.
Critical Analysis
• One potential limitation of StyleMaster is that it relies on having a suitable reference image to define the desired style. In some cases, it may be challenging to find a reference that perfectly captures the artistic style you want to apply.
• Additionally, while the paper demonstrates impressive results, the quality of the generated images may still fall short of what a skilled human artist could produce, especially for highly complex or abstract styles.
• Further research could explore ways to make the style specification process even more flexible, such as allowing users to define styles through textual descriptions or interactive editing tools, rather than just reference images.
Conclusion
• Overall, the StyleMaster approach represents an important step forward in making stylized image generation more accessible and customizable for both artists and casual users.
• By leveraging the power of diffusion models, the researchers have developed a system that can apply a wide range of artistic styles to images, opening up new creative possibilities in fields like illustration, graphic design, and digital art.
• As diffusion models continue to advance, we can expect to see more innovative applications like StyleMaster that push the boundaries of what's possible in image generation and manipulation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
StyleMaster: Towards Flexible Stylized Image Generation with Diffusion Models
Chengming Xu, Kai Hu, Donghao Luo, Jiangning Zhang, Wei Li, Yanhao Ge, Chengjie Wang
Stylized Text-to-Image Generation (STIG) aims to generate images based on text prompts and style reference images. We in this paper propose a novel framework dubbed as StyleMaster for this task by leveraging pretrained Stable Diffusion (SD), which tries to solve the previous problems such as insufficient style and inconsistent semantics. The enhancement lies in two novel module, namely multi-source style embedder and dynamic attention adapter. In order to provide SD with better style embeddings, we propose the multi-source style embedder considers both global and local level visual information along with textual one, which provide both complementary style-related and semantic-related knowledge. Additionally, aiming for better balance between the adaptor capacity and semantic control, the proposed dynamic attention adapter is applied to the diffusion UNet in which adaptation weights are dynamically calculated based on the style embeddings. Two objective functions are introduced to optimize the model together with denoising loss, which can further enhance semantic and style consistency. Extensive experiments demonstrate the superiority of StyleMaster over existing methods, rendering images with variable target styles while successfully maintaining the semantic information from the text prompts.
Read more5/27/2024

0
FreeStyle: Free Lunch for Text-guided Style Transfer using Diffusion Models
Feihong He, Gang Li, Mengyuan Zhang, Leilei Yan, Lingyu Si, Fanzhang Li, Li Shen
The rapid development of generative diffusion models has significantly advanced the field of style transfer. However, most current style transfer methods based on diffusion models typically involve a slow iterative optimization process, e.g., model fine-tuning and textual inversion of style concept. In this paper, we introduce FreeStyle, an innovative style transfer method built upon a pre-trained large diffusion model, requiring no further optimization. Besides, our method enables style transfer only through a text description of the desired style, eliminating the necessity of style images. Specifically, we propose a dual-stream encoder and single-stream decoder architecture, replacing the conventional U-Net in diffusion models. In the dual-stream encoder, two distinct branches take the content image and style text prompt as inputs, achieving content and style decoupling. In the decoder, we further modulate features from the dual streams based on a given content image and the corresponding style text prompt for precise style transfer. Our experimental results demonstrate high-quality synthesis and fidelity of our method across various content images and style text prompts. Compared with state-of-the-art methods that require training, our FreeStyle approach notably reduces the computational burden by thousands of iterations, while achieving comparable or superior performance across multiple evaluation metrics including CLIP Aesthetic Score, CLIP Score, and Preference. We have released the code anonymously at: href{https://anonymous.4open.science/r/FreeStyleAnonymous-0F9B}
Read more7/19/2024

0
Text-to-Image Synthesis for Any Artistic Styles: Advancements in Personalized Artistic Image Generation via Subdivision and Dual Binding
Junseo Park, Beomseok Ko, Hyeryung Jang
Recent advancements in text-to-image models, such as Stable Diffusion, have showcased their ability to create visual images from natural language prompts. However, existing methods like DreamBooth struggle with capturing arbitrary art styles due to the abstract and multifaceted nature of stylistic attributes. We introduce Single-StyleForge, a novel approach for personalized text-to-image synthesis across diverse artistic styles. Using approximately 15 to 20 images of the target style, Single-StyleForge establishes a foundational binding of a unique token identifier with a broad range of attributes of the target style. Additionally, auxiliary images are incorporated for dual binding that guides the consistent representation of crucial elements such as people within the target style. Furthermore, we present Multi-StyleForge, which enhances image quality and text alignment by binding multiple tokens to partial style attributes. Experimental evaluations across six distinct artistic styles demonstrate significant improvements in image quality and perceptual fidelity, as measured by FID, KID, and CLIP scores.
Read more7/18/2024
0
DGInStyle: Domain-Generalizable Semantic Segmentation with Image Diffusion Models and Stylized Semantic Control
Yuru Jia, Lukas Hoyer, Shengyu Huang, Tianfu Wang, Luc Van Gool, Konrad Schindler, Anton Obukhov
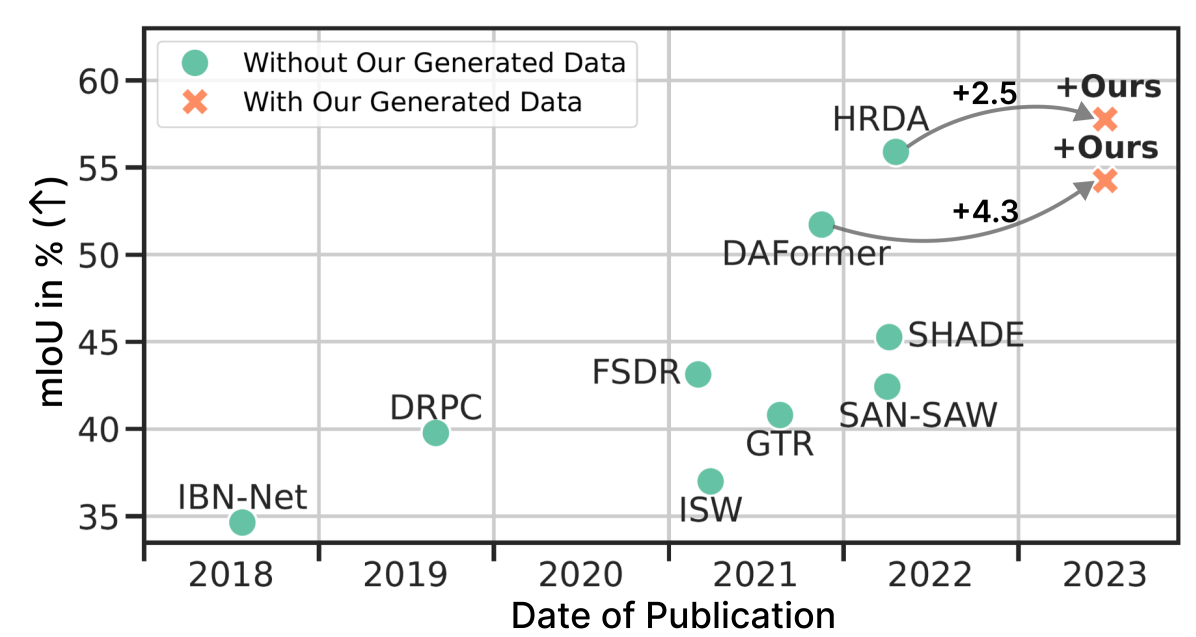
Large, pretrained latent diffusion models (LDMs) have demonstrated an extraordinary ability to generate creative content, specialize to user data through few-shot fine-tuning, and condition their output on other modalities, such as semantic maps. However, are they usable as large-scale data generators, e.g., to improve tasks in the perception stack, like semantic segmentation? We investigate this question in the context of autonomous driving, and answer it with a resounding yes. We propose an efficient data generation pipeline termed DGInStyle. First, we examine the problem of specializing a pretrained LDM to semantically-controlled generation within a narrow domain. Second, we propose a Style Swap technique to endow the rich generative prior with the learned semantic control. Third, we design a Multi-resolution Latent Fusion technique to overcome the bias of LDMs towards dominant objects. Using DGInStyle, we generate a diverse dataset of street scenes, train a domain-agnostic semantic segmentation model on it, and evaluate the model on multiple popular autonomous driving datasets. Our approach consistently increases the performance of several domain generalization methods compared to the previous state-of-the-art methods. The source code and the generated dataset are available at https://dginstyle.github.io.
Read more8/1/2024