StylePrompter: Enhancing Domain Generalization with Test-Time Style Priors

0

Sign in to get full access
Overview
- The paper proposes a method called "StylePrompter" to enhance domain generalization in machine learning models
- It aims to improve model performance on data from unseen domains by leveraging test-time style priors
- The key idea is to generate a style prompt that can be used to adaptively adjust the model's predictions at inference time
Plain English Explanation
The researchers developed a technique called StylePrompter to help machine learning models perform better on data from new, unseen domains. The core concept is to use information about the "style" of the test data to dynamically adjust the model's predictions.
Typically, machine learning models are trained on data from a certain set of domains, and then expected to perform well on data from new, previously unseen domains. However, this is often challenging, as the model may struggle to adapt to the different styles or characteristics of the new data.
The StylePrompter approach tries to address this by generating a "style prompt" that can be used to guide the model's predictions at test time. This style prompt is based on analyzing the statistical properties of the test data, and is used to adaptively adjust the model's outputs to better match the style of the new domain.
The key insight is that by incorporating this test-time style information, the model can better generalize to unseen domains, rather than relying solely on the training data it was exposed to. This can lead to significant performance improvements on real-world applications where the test data may come from a wide variety of sources.
Technical Explanation
The StylePrompter model consists of two main components:
- A Style Encoder: This module analyzes the statistical properties of the test data, such as the distribution of pixel values, to generate a style prompt.
- A Style-Aware Prediction Head: This component takes the style prompt and the model's initial predictions, and uses them to adaptively adjust the final output.
During training, the model is exposed to data from multiple source domains. It learns to generate style prompts that capture the unique characteristics of each domain, and to use these prompts to improve its predictions.
At test time, the StylePrompter model first generates a style prompt based on the current test data. It then uses this prompt, along with the model's initial predictions, to produce the final output. This allows the model to dynamically adapt to the style of the new, unseen domain.
The researchers evaluate StylePrompter on a range of domain generalization benchmarks, and show that it outperforms previous state-of-the-art methods. The improvements are particularly pronounced on datasets with high diversity in the test domains.
Critical Analysis
The StylePrompter approach is a promising technique for enhancing domain generalization, but it does have some potential limitations and areas for further research:
-
The effectiveness of the style prompt may depend on the complexity and diversity of the test domains. More research is needed to understand the types of domains and data distributions where this approach works best.
-
The paper does not explore the interpretability of the style prompts generated by the model. Understanding the specific style characteristics captured by the prompts could provide insights into the model's behavior and potential biases.
-
The experiments focus on image classification tasks, but the StylePrompter approach could potentially be extended to other domains, such as natural language processing or speech recognition. Exploring these extensions could broaden the impact of the research.
Overall, the StylePrompter method is a valuable contribution to the field of domain generalization, offering a novel way to leverage test-time information to improve model performance on unseen data.
Conclusion
The StylePrompter paper presents an effective technique for enhancing domain generalization in machine learning models. By generating a style prompt based on the test data, the model can adaptively adjust its predictions to better match the characteristics of the new domain.
This approach has the potential to significantly improve the real-world performance of AI systems, as it allows them to generalize more effectively to diverse data sources. The StylePrompter method could be particularly valuable in applications where models need to work reliably across a wide range of environments or settings.
Further research is needed to fully understand the limitations and potential extensions of this technique, but the core idea of leveraging test-time style information is a promising direction for advancing the field of domain generalization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
StylePrompter: Enhancing Domain Generalization with Test-Time Style Priors
Jiao Zhang, Jian Xu, Xu-Yao Zhang, Cheng-Lin Liu
In real-world applications, the sample distribution at the inference stage often differs from the one at the training stage, causing performance degradation of trained deep models. The research on domain generalization (DG) aims to develop robust algorithms that can improve the generalized performance in unseen domains by training on a few domains. However, the domain-agnostic vision model, trained on a limited number of domains using traditional domain generalization methods, cannot guarantee its effectiveness in dealing with unseen domains. The introduction of language can break the closed cognition space of the vision model, providing additional semantic information that cannot be inferred from vision-only datasets. In this paper, we propose to overcome the challenge in previous DG methods by introducing the style prompt in the language modality to adapt the trained model dynamically. In particular, we train a style prompter to extract style information of the current image into an embedding in the token embedding space and place it in front of the candidate category words as prior knowledge to prompt the model. Our open space partition of the style token embedding space and the hand-crafted style regularization enable the trained style prompter to handle data from unknown domains effectively. Extensive experiments verify the effectiveness of our method and demonstrate state-of-the-art performances on multiple public datasets. Codes will be available after the acceptance of this paper.
Read more8/20/2024
0
Transitive Vision-Language Prompt Learning for Domain Generalization
Liyuan Wang, Yan Jin, Zhen Chen, Jinlin Wu, Mengke Li, Yang Lu, Hanzi Wang
The vision-language pre-training has enabled deep models to make a huge step forward in generalizing across unseen domains. The recent learning method based on the vision-language pre-training model is a great tool for domain generalization and can solve this problem to a large extent. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. However, there are still some issues that an advancement still suffers from trading-off between domain invariance and class separability, which are crucial in current DG problems. In this paper, we introduce a novel prompt learning strategy that leverages deep vision prompts to address domain invariance while utilizing language prompts to ensure class separability, coupled with adaptive weighting mechanisms to balance domain invariance and class separability. Extensive experiments demonstrate that deep vision prompts effectively extract domain-invariant features, significantly improving the generalization ability of deep models and achieving state-of-the-art performance on three datasets.
Read more4/30/2024
0
DPStyler: Dynamic PromptStyler for Source-Free Domain Generalization
Yunlong Tang, Yuxuan Wan, Lei Qi, Xin Geng
Source-Free Domain Generalization (SFDG) aims to develop a model that works for unseen target domains without relying on any source domain. Research in SFDG primarily bulids upon the existing knowledge of large-scale vision-language models and utilizes the pre-trained model's joint vision-language space to simulate style transfer across domains, thus eliminating the dependency on source domain images. However, how to efficiently simulate rich and diverse styles using text prompts, and how to extract domain-invariant information useful for classification from features that contain both semantic and style information after the encoder, are directions that merit improvement. In this paper, we introduce Dynamic PromptStyler (DPStyler), comprising Style Generation and Style Removal modules to address these issues. The Style Generation module refreshes all styles at every training epoch, while the Style Removal module eliminates variations in the encoder's output features caused by input styles. Moreover, since the Style Generation module, responsible for generating style word vectors using random sampling or style mixing, makes the model sensitive to input text prompts, we introduce a model ensemble method to mitigate this sensitivity. Extensive experiments demonstrate that our framework outperforms state-of-the-art methods on benchmark datasets.
Read more7/16/2024
0
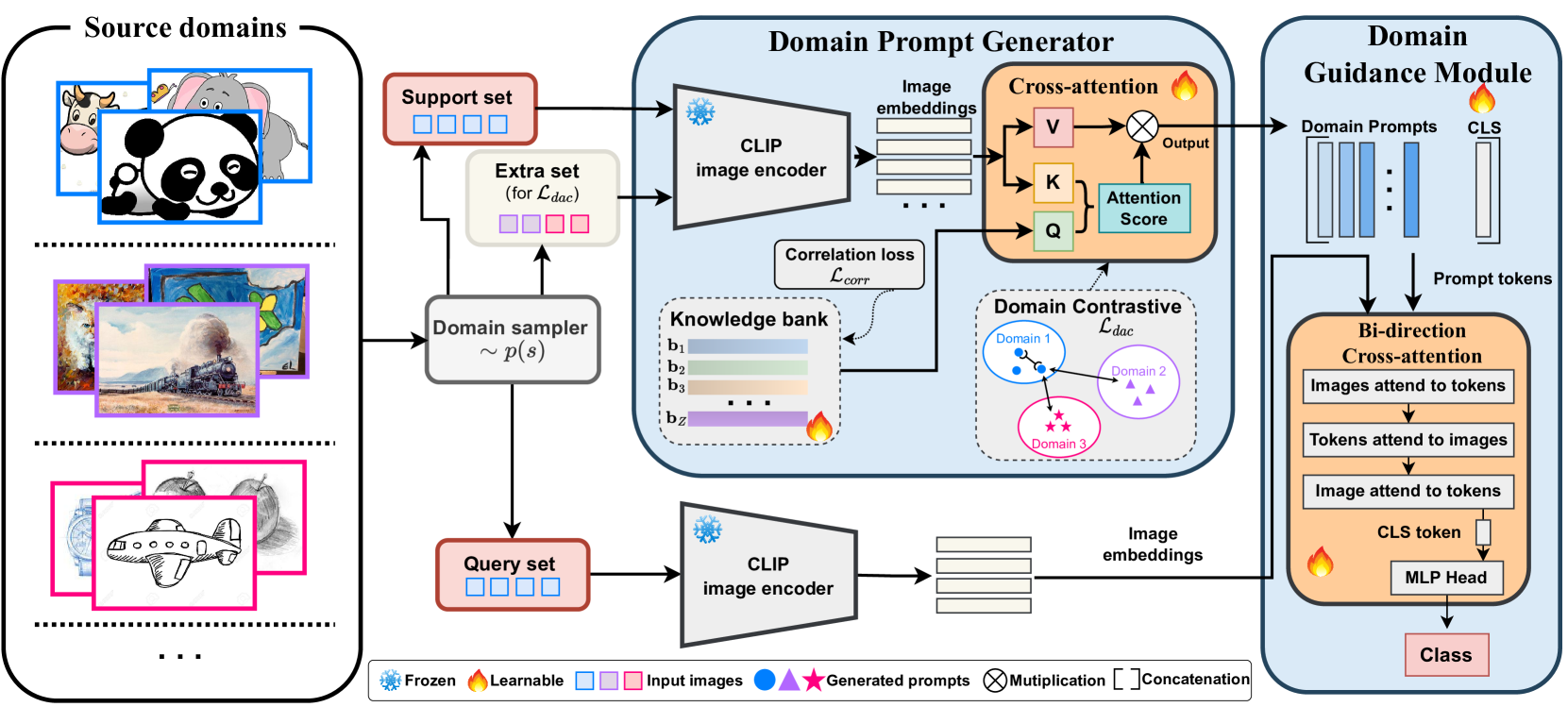
Adapting to Distribution Shift by Visual Domain Prompt Generation
Zhixiang Chi, Li Gu, Tao Zhong, Huan Liu, Yuanhao Yu, Konstantinos N Plataniotis, Yang Wang
In this paper, we aim to adapt a model at test-time using a few unlabeled data to address distribution shifts. To tackle the challenges of extracting domain knowledge from a limited amount of data, it is crucial to utilize correlated information from pre-trained backbones and source domains. Previous studies fail to utilize recent foundation models with strong out-of-distribution generalization. Additionally, domain-centric designs are not flavored in their works. Furthermore, they employ the process of modelling source domains and the process of learning to adapt independently into disjoint training stages. In this work, we propose an approach on top of the pre-computed features of the foundation model. Specifically, we build a knowledge bank to learn the transferable knowledge from source domains. Conditioned on few-shot target data, we introduce a domain prompt generator to condense the knowledge bank into a domain-specific prompt. The domain prompt then directs the visual features towards a particular domain via a guidance module. Moreover, we propose a domain-aware contrastive loss and employ meta-learning to facilitate domain knowledge extraction. Extensive experiments are conducted to validate the domain knowledge extraction. The proposed method outperforms previous work on 5 large-scale benchmarks including WILDS and DomainNet.
Read more5/7/2024