CycleMix: Mixing Source Domains for Domain Generalization in Style-Dependent Data

0

Sign in to get full access
Overview
- Presents a novel approach called "CycleMix" for improving domain generalization in style-dependent data
- Focuses on the challenge of training a model to perform well on data from unseen domains, even when the data has distinct visual styles
- Introduces a mixing-based data augmentation technique that can effectively combine multiple source domains to enhance generalization
Plain English Explanation
CycleMix is a new method that helps machine learning models perform well on data from different domains, even when those domains have distinct visual styles. This is an important problem because real-world data often comes from a variety of sources with different characteristics, and we want models to work well across all of them.
The key idea behind CycleMix is to mix together data from multiple source domains in a smart way during training. This helps the model learn features that are robust to the specific visual styles of each domain, allowing it to generalize better to new, unseen domains. By combining information from multiple sources, the model can become more adaptable and less reliant on the idiosyncrasies of any single dataset.
The authors show that CycleMix outperforms other techniques for domain generalization and single-domain stylization on a range of benchmarks. This suggests CycleMix is a promising approach for building more robust and versatile machine learning models that can handle the diverse data encountered in real-world applications.
Technical Explanation
The key innovation of CycleMix is a novel data augmentation technique that combines multiple source domains in a principled way during training. First, the model learns to transform the style of an input image from one source domain to another. It then mixes the transformed image with a randomly sampled image from a third source domain.
This "mixing" process encourages the model to learn features that are invariant to the specific visual style of each domain, as it must learn to classify objects correctly regardless of the combined style. The authors show this approach is more effective than simply training on a union of the source domains or applying generic style transfer techniques.
Extensive experiments on several domain generalization benchmarks demonstrate the advantages of CycleMix. The method significantly outperforms previous state-of-the-art techniques, especially when the target domain has a very different visual style from the source domains used during training.
Critical Analysis
The authors acknowledge that CycleMix relies on having access to multiple source domains during training, which may not always be the case in real-world scenarios. They suggest exploring unsupervised or self-supervised approaches to domain discovery and mixing as an area for future work.
Additionally, the current implementation of CycleMix is computationally intensive, as it requires training separate style transfer models for each pair of source domains. Developing more efficient architectures or optimization techniques could help make the method more practical for large-scale applications.
While the paper demonstrates impressive results on standard benchmarks, it would be valuable to see how CycleMix performs on more diverse and challenging real-world datasets, particularly those with complex, multimodal data distributions.
Conclusion
CycleMix is a promising new approach for improving the domain generalization capabilities of machine learning models, particularly when the target data has a distinct visual style compared to the training data. By mixing information from multiple source domains in a principled way, the method helps models learn more robust and transferable features, leading to significant performance gains on a range of benchmarks.
As machine learning systems become more ubiquitous in real-world applications, the ability to generalize across diverse data sources will be crucial. Techniques like CycleMix represent an important step towards building more adaptable and reliable AI systems that can handle the complexity and variability of the natural world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CycleMix: Mixing Source Domains for Domain Generalization in Style-Dependent Data
Aristotelis Ballas, Christos Diou
As deep learning-based systems have become an integral part of everyday life, limitations in their generalization ability have begun to emerge. Machine learning algorithms typically rely on the i.i.d. assumption, meaning that their training and validation data are expected to follow the same distribution, which does not necessarily hold in practice. In the case of image classification, one frequent reason that algorithms fail to generalize is that they rely on spurious correlations present in training data, such as associating image styles with target classes. These associations may not be present in the unseen test data, leading to significant degradation of their effectiveness. In this work, we attempt to mitigate this Domain Generalization (DG) problem by training a robust feature extractor which disregards features attributed to image-style but infers based on style-invariant image representations. To achieve this, we train CycleGAN models to learn the different styles present in the training data and randomly mix them together to create samples with novel style attributes to improve generalization. Experimental results on the PACS DG benchmark validate the proposed method.
Read more7/25/2024
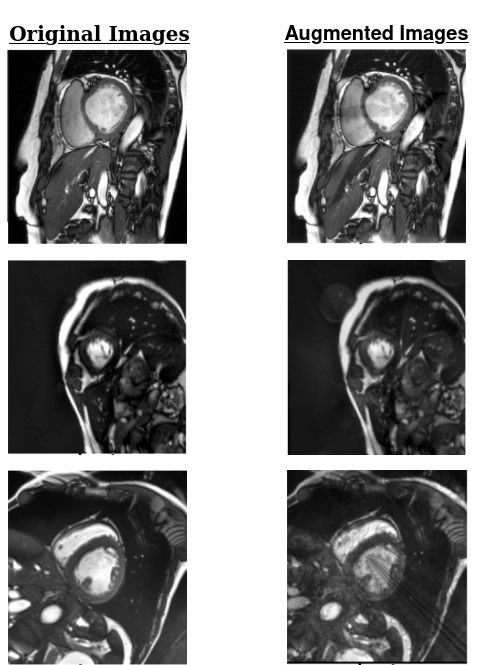
0
Complex Style Image Transformations for Domain Generalization in Medical Images
Nikolaos Spanos, Anastasios Arsenos, Paraskevi-Antonia Theofilou, Paraskevi Tzouveli, Athanasios Voulodimos, Stefanos Kollias
The absence of well-structured large datasets in medical computer vision results in decreased performance of automated systems and, especially, of deep learning models. Domain generalization techniques aim to approach unknown domains from a single data source. In this paper we introduce a novel framework, named CompStyle, which leverages style transfer and adversarial training, along with high-level input complexity augmentation to effectively expand the domain space and address unknown distributions. State-of-the-art style transfer methods depend on the existence of subdomains within the source dataset. However, this can lead to an inherent dataset bias in the image creation. Input-level augmentation can provide a solution to this problem by widening the domain space in the source dataset and boost performance on out-of-domain distributions. We provide results from experiments on semantic segmentation on prostate data and corruption robustness on cardiac data which demonstrate the effectiveness of our approach. Our method increases performance in both tasks, without added cost to training time or resources.
Read more6/4/2024

0
StylePrompter: Enhancing Domain Generalization with Test-Time Style Priors
Jiao Zhang, Jian Xu, Xu-Yao Zhang, Cheng-Lin Liu
In real-world applications, the sample distribution at the inference stage often differs from the one at the training stage, causing performance degradation of trained deep models. The research on domain generalization (DG) aims to develop robust algorithms that can improve the generalized performance in unseen domains by training on a few domains. However, the domain-agnostic vision model, trained on a limited number of domains using traditional domain generalization methods, cannot guarantee its effectiveness in dealing with unseen domains. The introduction of language can break the closed cognition space of the vision model, providing additional semantic information that cannot be inferred from vision-only datasets. In this paper, we propose to overcome the challenge in previous DG methods by introducing the style prompt in the language modality to adapt the trained model dynamically. In particular, we train a style prompter to extract style information of the current image into an embedding in the token embedding space and place it in front of the candidate category words as prior knowledge to prompt the model. Our open space partition of the style token embedding space and the hand-crafted style regularization enable the trained style prompter to handle data from unknown domains effectively. Extensive experiments verify the effectiveness of our method and demonstrate state-of-the-art performances on multiple public datasets. Codes will be available after the acceptance of this paper.
Read more8/20/2024

0
Causality-inspired Latent Feature Augmentation for Single Domain Generalization
Jian Xu, Chaojie Ji, Yankai Cao, Ye Li, Ruxin Wang
Single domain generalization (Single-DG) intends to develop a generalizable model with only one single training domain to perform well on other unknown target domains. Under the domain-hungry configuration, how to expand the coverage of source domain and find intrinsic causal features across different distributions is the key to enhancing the models' generalization ability. Existing methods mainly depend on the meticulous design of finite image-level transformation techniques and learning invariant features across domains based on statistical correlation between samples and labels in source domain. This makes it difficult to capture stable semantics between source and target domains, which hinders the improvement of the model's generalization performance. In this paper, we propose a novel causality-inspired latent feature augmentation method for Single-DG by learning the meta-knowledge of feature-level transformation based on causal learning and interventions. Instead of strongly relying on the finite image-level transformation, with the learned meta-knowledge, we can generate diverse implicit feature-level transformations in latent space based on the consistency of causal features and diversity of non-causal features, which can better compensate for the domain-hungry defect and reduce the strong reliance on initial finite image-level transformations and capture more stable domain-invariant causal features for generalization. Extensive experiments on several open-access benchmarks demonstrate the outstanding performance of our model over other state-of-the-art single domain generalization and also multi-source domain generalization methods.
Read more6/11/2024