TalkCLIP: Talking Head Generation with Text-Guided Expressive Speaking Styles

0
🛸
Sign in to get full access
Overview
- This paper proposes a new framework called TalkCLIP that can generate talking head videos where the facial expressions are specified using natural language descriptions.
- Previous methods for generating talking heads required additional reference videos to provide the desired expressions, which can be difficult to find.
- TalkCLIP uses a text-to-expression mapping model that allows users to describe the expressions they want, making the process more convenient.
Plain English Explanation
The paper describes a new way to create videos of a person's head ("talking heads") where the facial expressions can be controlled using text descriptions. Previous methods often required finding additional videos to use as a reference for the desired expressions, which could be challenging.
The TalkCLIP framework solves this by learning how to translate natural language descriptions of expressions into the corresponding facial movements. The researchers created a dataset of talking head videos with text descriptions of the expressions, and then used this to train a model that can map text to the appropriate facial expressions.
This allows users to simply type what kind of expression they want, such as "a surprised look" or "a gentle smile," and the system will generate a video of the talking head displaying that expression. TalkCLIP can even handle descriptions it hasn't seen before during training, allowing for a lot of flexibility.
The paper shows that TalkCLIP can create very realistic-looking talking head videos with expressive faces that match the text descriptions provided. This could be useful for applications like video game characters, animated videos, or virtual assistants where natural and expressive facial movements are important.
Technical Explanation
The key technical innovation in this work is the TalkCLIP framework, which consists of a CLIP-based style encoder that maps natural language descriptions to representations of facial expressions.
The researchers first constructed a text-video paired dataset, where each talking head video had multiple text descriptions associated with it that captured both coarse-level emotions (e.g. "happy," "sad") and fine-grained facial movements (e.g. "raised eyebrows," "slight smile").
Using this dataset, they trained the CLIP-based style encoder to project the text descriptions into a latent space that corresponds to the facial expression representations. This allows TalkCLIP to generate talking head videos where the expressions are controlled by the provided text.
A notable capability of TalkCLIP is its ability to handle unseen text descriptions during inference, inferring the appropriate facial expressions without requiring those descriptions in the training data. The framework can also be used to modulate the intensity of expressions and edit the expressions in existing talking head videos.
Extensive experiments demonstrated that TalkCLIP is able to generate highly realistic and vivid talking head videos with facial expressions that closely match the input text descriptions. This represents a significant advance over previous methods that relied on reference videos to specify expressions.
Critical Analysis
The researchers acknowledge several limitations and areas for future work in the paper. One key limitation is that the quality of the generated talking head videos, while impressive, may still fall short of human-level realism in certain cases.
Additionally, the text-to-expression mapping learned by TalkCLIP is likely dependent on the specific dataset used for training. The performance may degrade when applied to domains or use cases that differ significantly from the training data.
Further research could explore techniques to improve the generalization capabilities of the model, such as using more diverse training data or incorporating additional modalities beyond just text and video. Exploring the synergies between language and other sensory inputs like gaze could also be a promising direction.
Another area for potential improvement is the ability to fine-tune or adapt the TalkCLIP model to individual users or specific applications, rather than relying solely on the pre-trained model. This could help ensure the generated talking heads match the desired persona or style more closely.
Overall, the TalkCLIP framework represents a significant step forward in the field of audio-driven talking head synthesis, and the researchers have demonstrated its impressive capabilities. As the technology continues to evolve, it will be exciting to see how it can be applied to even more engaging and natural conversational interfaces.
Conclusion
This paper introduces TalkCLIP, a novel framework for generating highly realistic talking head videos where the facial expressions are controlled by natural language descriptions. By leveraging a text-to-expression mapping model, TalkCLIP allows users to easily specify the desired expressions, overcoming the limitations of previous methods that relied on reference videos.
The key technical contribution is the CLIP-based style encoder that can project text descriptions into a latent space corresponding to facial expression representations. Extensive experiments show that TalkCLIP can generate talking head videos with vivid and accurate expressions that match the input text, representing a significant advancement in the field of audio-driven talking head synthesis.
While the technology still has room for improvement, particularly in terms of generalization and user-specific customization, the capabilities demonstrated by TalkCLIP suggest it could have far-reaching implications for applications that require natural and expressive conversational interfaces, such as video games, animated films, and virtual assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
TalkCLIP: Talking Head Generation with Text-Guided Expressive Speaking Styles
Yifeng Ma, Suzhen Wang, Yu Ding, Bowen Ma, Tangjie Lv, Changjie Fan, Zhipeng Hu, Zhidong Deng, Xin Yu
Audio-driven talking head generation has drawn growing attention. To produce talking head videos with desired facial expressions, previous methods rely on extra reference videos to provide expression information, which may be difficult to find and hence limits their usage. In this work, we propose TalkCLIP, a framework that can generate talking heads where the expressions are specified by natural language, hence allowing for specifying expressions more conveniently. To model the mapping from text to expressions, we first construct a text-video paired talking head dataset where each video has diverse text descriptions that depict both coarse-grained emotions and fine-grained facial movements. Leveraging the proposed dataset, we introduce a CLIP-based style encoder that projects natural language-based descriptions to the representations of expressions. TalkCLIP can even infer expressions for descriptions unseen during training. TalkCLIP can also use text to modulate expression intensity and edit expressions. Extensive experiments demonstrate that TalkCLIP achieves the advanced capability of generating photo-realistic talking heads with vivid facial expressions guided by text descriptions.
Read more8/13/2024
🛸
0
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
Changpeng Cai, Guinan Guo, Jiao Li, Junhao Su, Chenghao He, Jing Xiao, Yuanxu Chen, Lei Dai, Feiyu Zhu
Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E
Read more8/28/2024
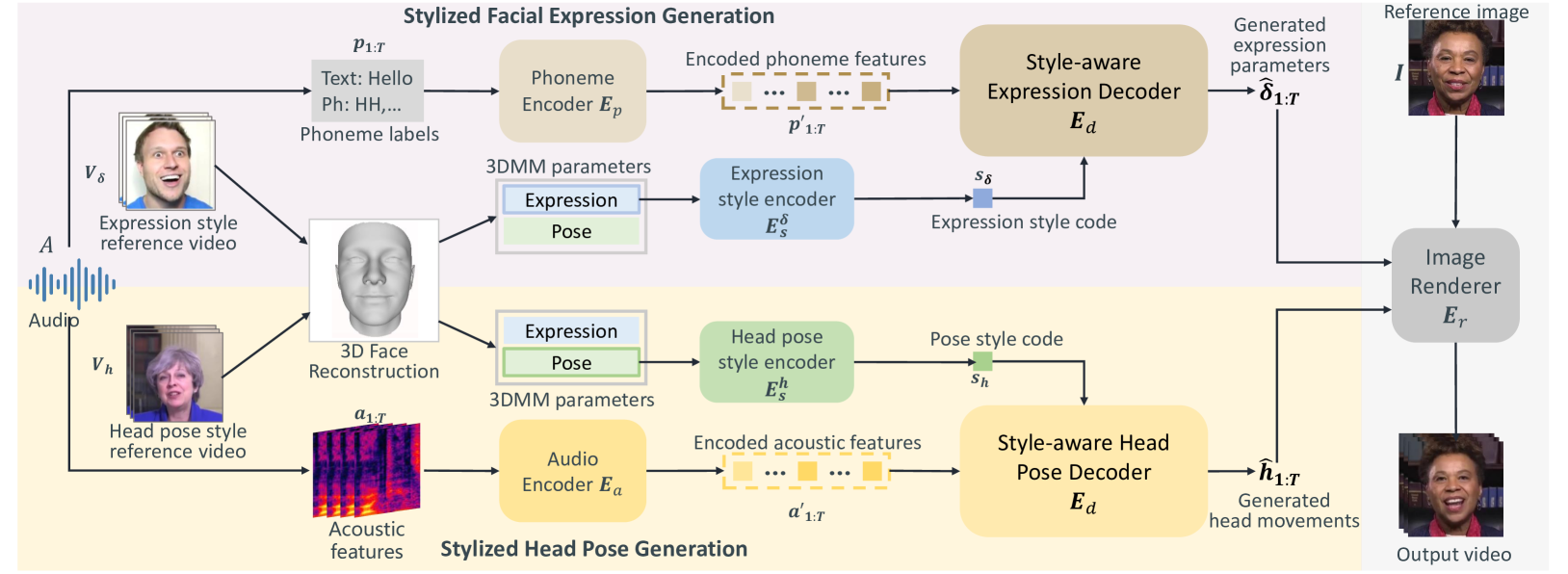
0
StyleTalk++: A Unified Framework for Controlling the Speaking Styles of Talking Heads
Suzhen Wang, Yifeng Ma, Yu Ding, Zhipeng Hu, Changjie Fan, Tangjie Lv, Zhidong Deng, Xin Yu
Individuals have unique facial expression and head pose styles that reflect their personalized speaking styles. Existing one-shot talking head methods cannot capture such personalized characteristics and therefore fail to produce diverse speaking styles in the final videos. To address this challenge, we propose a one-shot style-controllable talking face generation method that can obtain speaking styles from reference speaking videos and drive the one-shot portrait to speak with the reference speaking styles and another piece of audio. Our method aims to synthesize the style-controllable coefficients of a 3D Morphable Model (3DMM), including facial expressions and head movements, in a unified framework. Specifically, the proposed framework first leverages a style encoder to extract the desired speaking styles from the reference videos and transform them into style codes. Then, the framework uses a style-aware decoder to synthesize the coefficients of 3DMM from the audio input and style codes. During decoding, our framework adopts a two-branch architecture, which generates the stylized facial expression coefficients and stylized head movement coefficients, respectively. After obtaining the coefficients of 3DMM, an image renderer renders the expression coefficients into a specific person's talking-head video. Extensive experiments demonstrate that our method generates visually authentic talking head videos with diverse speaking styles from only one portrait image and an audio clip.
Read more9/17/2024

0
Emotional Conversation: Empowering Talking Faces with Cohesive Expression, Gaze and Pose Generation
Jiadong Liang, Feng Lu
Vivid talking face generation holds immense potential applications across diverse multimedia domains, such as film and game production. While existing methods accurately synchronize lip movements with input audio, they typically ignore crucial alignments between emotion and facial cues, which include expression, gaze, and head pose. These alignments are indispensable for synthesizing realistic videos. To address these issues, we propose a two-stage audio-driven talking face generation framework that employs 3D facial landmarks as intermediate variables. This framework achieves collaborative alignment of expression, gaze, and pose with emotions through self-supervised learning. Specifically, we decompose this task into two key steps, namely speech-to-landmarks synthesis and landmarks-to-face generation. The first step focuses on simultaneously synthesizing emotionally aligned facial cues, including normalized landmarks that represent expressions, gaze, and head pose. These cues are subsequently reassembled into relocated facial landmarks. In the second step, these relocated landmarks are mapped to latent key points using self-supervised learning and then input into a pretrained model to create high-quality face images. Extensive experiments on the MEAD dataset demonstrate that our model significantly advances the state-of-the-art performance in both visual quality and emotional alignment.
Read more6/13/2024