Subjective and Objective Quality Assessment of Rendered Human Avatar Videos in Virtual Reality

0

Sign in to get full access
Overview
- Researchers conducted a study to evaluate the subjective and objective quality of rendered human avatar videos in virtual reality (VR)
- They assessed various aspects of the avatar videos, including realism, smoothness, and visual fidelity
- The study involved both subjective user evaluations and objective measurements using established video quality assessment methods
Plain English Explanation
The researchers looked at how realistic and high-quality human avatar videos appear in virtual reality (VR) environments. They wanted to understand both how users perceive the quality subjectively, as well as measure it objectively using standard video quality assessment techniques.
The goal was to provide insights into what makes for a compelling and immersive avatar experience in VR. This is an important consideration as virtual avatars become more prevalent in areas like gaming, social VR, and even remote work.
By combining subjective user feedback with objective quality metrics, the researchers hoped to paint a comprehensive picture of avatar video quality in VR. This could help guide the development of more realistic and engaging 3D human avatars and facial animation techniques for virtual environments.
Technical Explanation
The study used both subjective and objective methods to assess the quality of rendered human avatar videos in virtual reality. For the subjective evaluation, participants were asked to rate videos of avatars on factors like realism, smoothness, and overall visual quality using a multi-dimensional scale.
Objectively, the researchers leveraged established video quality assessment methods like PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and VQM (Video Quality Metric) to measure different aspects of the avatar video fidelity. These metrics provided quantitative assessments of attributes like sharpness, color accuracy, and temporal stability.
The avatar videos were rendered at varying levels of complexity, with differences in factors like polygon count, texture resolution, and animation quality. This allowed the researchers to explore how these technical parameters impacted the perceived and measured quality of the avatars in the VR setting.
Critical Analysis
The study provides a valuable framework for evaluating avatar video quality from both subjective and objective perspectives. However, some limitations are worth noting. The participant pool was relatively small, which may limit the generalizability of the subjective findings. Additionally, the objective metrics used, while well-established, may not fully capture the nuances of how users experience avatar realism and immersion in VR.
Further research could explore a wider range of avatar rendering techniques, as well as investigate how factors like user characteristics, virtual environment design, and task context influence perceptions of avatar quality. Longitudinal studies tracking user responses over extended VR sessions could also yield additional insights.
Conclusion
This research represents an important step in understanding how to create high-quality, photorealistic human avatars for VR applications. By combining subjective user evaluations and objective quality assessments, the study provides a comprehensive view of the key factors that contribute to a compelling avatar experience.
As virtual avatars become more prevalent in social, gaming, and professional contexts, this work can inform the development of more immersive and engaging 3D avatars and facial animation techniques. Continued research in this area will be crucial for enhancing the overall user experience in virtual reality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Subjective and Objective Quality Assessment of Rendered Human Avatar Videos in Virtual Reality
Yu-Chih Chen, Avinab Saha, Alexandre Chapiro, Christian Hane, Jean-Charles Bazin, Bo Qiu, Stefano Zanetti, Ioannis Katsavounidis, Alan C. Bovik
We study the visual quality judgments of human subjects on digital human avatars (sometimes referred to as holograms in the parlance of virtual reality [VR] and augmented reality [AR] systems) that have been subjected to distortions. We also study the ability of video quality models to predict human judgments. As streaming human avatar videos in VR or AR become increasingly common, the need for more advanced human avatar video compression protocols will be required to address the tradeoffs between faithfully transmitting high-quality visual representations while adjusting to changeable bandwidth scenarios. During transmission over the internet, the perceived quality of compressed human avatar videos can be severely impaired by visual artifacts. To optimize trade-offs between perceptual quality and data volume in practical workflows, video quality assessment (VQA) models are essential tools. However, there are very few VQA algorithms developed specifically to analyze human body avatar videos, due, at least in part, to the dearth of appropriate and comprehensive datasets of adequate size. Towards filling this gap, we introduce the LIVE-Meta Rendered Human Avatar VQA Database, which contains 720 human avatar videos processed using 20 different combinations of encoding parameters, labeled by corresponding human perceptual quality judgments that were collected in six degrees of freedom VR headsets. To demonstrate the usefulness of this new and unique video resource, we use it to study and compare the performances of a variety of state-of-the-art Full Reference and No Reference video quality prediction models, including a new model called HoloQA. As a service to the research community, we will be publicly releasing the metadata of the new database at https://live.ece.utexas.edu/research/LIVE-Meta-rendered-human-avatar/index.html.
Read more8/14/2024

0
Fast Registration of Photorealistic Avatars for VR Facial Animation
Chaitanya Patel, Shaojie Bai, Te-Li Wang, Jason Saragih, Shih-En Wei
Virtual Reality (VR) bares promise of social interactions that can feel more immersive than other media. Key to this is the ability to accurately animate a personalized photorealistic avatar, and hence the acquisition of the labels for headset-mounted camera (HMC) images need to be efficient and accurate, while wearing a VR headset. This is challenging due to oblique camera views and differences in image modality. In this work, we first show that the domain gap between the avatar and HMC images is one of the primary sources of difficulty, where a transformer-based architecture achieves high accuracy on domain-consistent data, but degrades when the domain-gap is re-introduced. Building on this finding, we propose a system split into two parts: an iterative refinement module that takes in-domain inputs, and a generic avatar-guided image-to-image domain transfer module conditioned on current estimates. These two modules reinforce each other: domain transfer becomes easier when close-to-groundtruth examples are shown, and better domain-gap removal in turn improves the registration. Our system obviates the need for costly offline optimization, and produces online registration of higher quality than direct regression method. We validate the accuracy and efficiency of our approach through extensive experiments on a commodity headset, demonstrating significant improvements over these baselines. To stimulate further research in this direction, we make our large-scale dataset and code publicly available.
Read more7/22/2024

0
Perception in Pixels: Understanding Avatar Representation in Video-Mediated Collaborative Interactions
Pitch Sinlapanuntakul, Mark Zachry
Despite the abundance of research concerning virtual reality (VR) avatars, the impact of screen-based or augmented reality (AR) avatars for real-world applications remain relatively unexplored. Notably, there is a lack of research examining video-mediated collaborative interaction experiences using AR avatars for goal-directed group activities. This study bridges this gap with a mixed-methods, quasi-experimental user study that investigates video-based small-group interactions when employing AR avatars as opposed to traditional video for user representation. We found that the use of avatars positively influenced self-esteem and video-based collaboration satisfaction. In addition, our group interview findings highlight experiences and perceptions regarding the dynamic use of avatars in video-mediated collaborative interactions, including benefits, challenges, and factors that would influence a decision to use avatars. This study contributes an empirical understanding of avatar representation in mediating video-based collaborative interactions, implications and perceptions surrounding the adoption of AR avatars, and a comprehensive comparison of key characteristics between user representations.
Read more5/8/2024
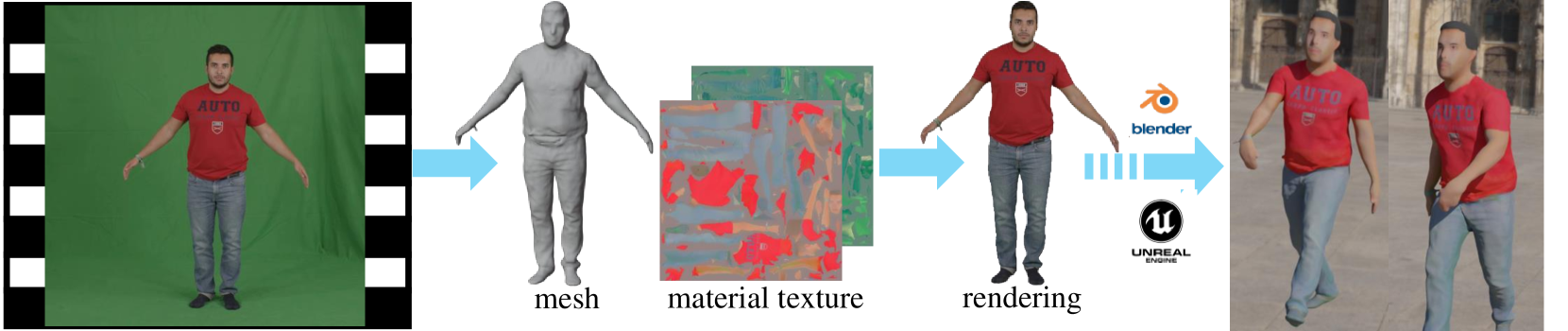
0
HR Human: Modeling Human Avatars with Triangular Mesh and High-Resolution Textures from Videos
Qifeng Chen, Rengan Xie, Kai Huang, Qi Wang, Wenting Zheng, Rong Li, Yuchi Huo
Recently, implicit neural representation has been widely used to generate animatable human avatars. However, the materials and geometry of those representations are coupled in the neural network and hard to edit, which hinders their application in traditional graphics engines. We present a framework for acquiring human avatars that are attached with high-resolution physically-based material textures and triangular mesh from monocular video. Our method introduces a novel information fusion strategy to combine the information from the monocular video and synthesize virtual multi-view images to tackle the sparsity of the input view. We reconstruct humans as deformable neural implicit surfaces and extract triangle mesh in a well-behaved pose as the initial mesh of the next stage. In addition, we introduce an approach to correct the bias for the boundary and size of the coarse mesh extracted. Finally, we adapt prior knowledge of the latent diffusion model at super-resolution in multi-view to distill the decomposed texture. Experiments show that our approach outperforms previous representations in terms of high fidelity, and this explicit result supports deployment on common renderers.
Read more5/21/2024