Self-Avatar Animation in Virtual Reality: Impact of Motion Signals Artifacts on the Full-Body Pose Reconstruction
2404.18628
0
0
Abstract
Virtual Reality (VR) applications have revolutionized user experiences by immersing individuals in interactive 3D environments. These environments find applications in numerous fields, including healthcare, education, or architecture. A significant aspect of VR is the inclusion of self-avatars, representing users within the virtual world, which enhances interaction and embodiment. However, generating lifelike full-body self-avatar animations remains challenging, particularly in consumer-grade VR systems, where lower-body tracking is often absent. One method to tackle this problem is by providing an external source of motion information that includes lower body information such as full Cartesian positions estimated from RGB(D) cameras. Nevertheless, the limitations of these systems are multiples: the desynchronization between the two motion sources and occlusions are examples of significant issues that hinder the implementations of such systems. In this paper, we aim to measure the impact on the reconstruction of the articulated self-avatar's full-body pose of (1) the latency between the VR motion features and estimated positions, (2) the data acquisition rate, (3) occlusions, and (4) the inaccuracy of the position estimation algorithm. In addition, we analyze the motion reconstruction errors using ground truth and 3D Cartesian coordinates estimated from textit{YOLOv8} pose estimation. These analyzes show that the studied methods are significantly sensitive to any degradation tested, especially regarding the velocity reconstruction error.
Create account to get full access
Overview
- This paper investigates the impact of motion signal artifacts on the reconstruction of full-body poses in virtual reality (VR) self-avatar animation.
- The researchers explore how errors or distortions in the motion capture data used to drive the self-avatar can affect the fidelity and realism of the avatar's movements.
- The study aims to provide insights into the challenges and trade-offs involved in creating high-quality VR avatars that accurately reflect the user's real-world movements.
Plain English Explanation
In virtual reality (VR) experiences, users are often represented by digital avatars that mirror their movements in real-time. These self-avatars are meant to provide a sense of embodiment and enhance the immersive experience. However, the motion data used to animate these avatars can sometimes be imperfect or noisy, leading to artifacts or distortions in the avatar's movements.
The researchers in this study wanted to understand how these motion signal artifacts, such as noise or inaccuracies, can impact the realism and fidelity of the full-body pose reconstruction for VR self-avatars. By exploring the effects of different types of motion data errors, they aim to provide insights that can help developers create more convincing and natural-looking VR avatars that better reflect the user's actual movements.
This research is important because the quality and responsiveness of self-avatars are crucial for maintaining a strong sense of presence and embodiment in VR environments. Realistic avatar animation is a key component of creating immersive virtual experiences.
Technical Explanation
The researchers conducted a series of experiments to investigate the impact of various motion signal artifacts on the reconstruction of full-body poses for VR self-avatars. They simulated different types of motion data errors, such as noise, missing data, and delays, and then evaluated how these artifacts affected the accuracy and fidelity of the reconstructed avatar poses.
The researchers used a deep learning-based approach to perform the full-body pose reconstruction, building on existing methods for hybrid 3D human pose estimation and efficient 3D head reconstruction. They also incorporated insights from related research on physics-based avatar modeling and efficient animatable human modeling to enhance the avatar's realism and responsiveness.
The study's findings provide valuable insights into the trade-offs and challenges involved in creating high-quality VR self-avatars. The researchers identified specific types of motion signal artifacts that have the most significant impact on the fidelity of the reconstructed full-body poses, highlighting areas for further refinement and improvement in avatar animation technologies.
Critical Analysis
The paper provides a comprehensive and rigorous investigation of the impact of motion signal artifacts on VR self-avatar animation. However, the researchers acknowledge that their study is limited to simulated motion data errors and does not directly address the performance of their approach in real-world VR systems.
Additionally, the researchers note that the quality and accuracy of the full-body pose reconstruction are still constrained by the inherent limitations of the underlying deep learning models and the available motion capture data. Further advancements in these areas could lead to even more realistic and responsive VR avatars.
It would be interesting to see the researchers extend their work to explore the perceptual and experiential impacts of motion signal artifacts on users' sense of embodiment and presence in VR environments. Understanding how different types of artifacts affect the user's subjective experience could provide valuable insights for optimizing avatar animation for enhanced immersion.
Conclusion
This study provides valuable insights into the challenges and trade-offs involved in creating high-quality VR self-avatars that accurately reflect the user's real-world movements. By investigating the impact of motion signal artifacts on full-body pose reconstruction, the researchers have highlighted key areas for improvement in avatar animation technologies.
The findings from this research can inform the development of more realistic and responsive VR avatars, which are essential for maintaining a strong sense of presence and embodiment in immersive virtual experiences. As the field of VR continues to evolve, addressing the technical and perceptual challenges of self-avatar animation will be crucial for enhancing the overall quality and realism of virtual environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Effects of Realism and Representation on Self-Embodied Avatars in Immersive Virtual Environments
Rafael Kuffner dos Anjos, Jo~ao Madeiras Pereira
0
0
Virtual Reality (VR) has recently gained traction with many new and ever more affordable devices being released. The increase in popularity of this paradigm of interaction has given birth to new applications and has attracted casual consumers to experience VR. Providing a self-embodied representation (avatar) of users' full bodies inside shared virtual spaces can improve the VR experience and make it more engaging to both new and experienced users . This is especially important in fully immersive systems, where the equipment completely occludes the real world making self awareness problematic. Indeed, the feeling of presence of the user is highly influenced by their virtual representations, even though small flaws could lead to uncanny valley side-effects. Following previous research, we would like to assess whether using a third-person perspective could also benefit the VR experience, via an improved spatial awareness of the user's virtual surroundings. In this paper we investigate realism and perspective of self-embodied representation in VR setups in natural tasks, such as walking and avoiding obstacles. We compare both First and Third-Person perspectives with three different levels of realism in avatar representation. These range from a stylized abstract avatar, to a realistic mesh-based humanoid representation and a point-cloud rendering. The latter uses data captured via depth-sensors and mapped into a virtual self inside the Virtual Environment. We present a throughout evaluation and comparison of these different representations, describing a series of guidelines for self-embodied VR applications. The effects of the uncanny valley are also discussed in the context of navigation and reflex-based tasks.
5/7/2024

Real-Time Simulated Avatar from Head-Mounted Sensors
Zhengyi Luo, Jinkun Cao, Rawal Khirodkar, Alexander Winkler, Jing Huang, Kris Kitani, Weipeng Xu
0
0
We present SimXR, a method for controlling a simulated avatar from information (headset pose and cameras) obtained from AR / VR headsets. Due to the challenging viewpoint of head-mounted cameras, the human body is often clipped out of view, making traditional image-based egocentric pose estimation challenging. On the other hand, headset poses provide valuable information about overall body motion, but lack fine-grained details about the hands and feet. To synergize headset poses with cameras, we control a humanoid to track headset movement while analyzing input images to decide body movement. When body parts are seen, the movements of hands and feet will be guided by the images; when unseen, the laws of physics guide the controller to generate plausible motion. We design an end-to-end method that does not rely on any intermediate representations and learns to directly map from images and headset poses to humanoid control signals. To train our method, we also propose a large-scale synthetic dataset created using camera configurations compatible with a commercially available VR headset (Quest 2) and show promising results on real-world captures. To demonstrate the applicability of our framework, we also test it on an AR headset with a forward-facing camera.
4/26/2024
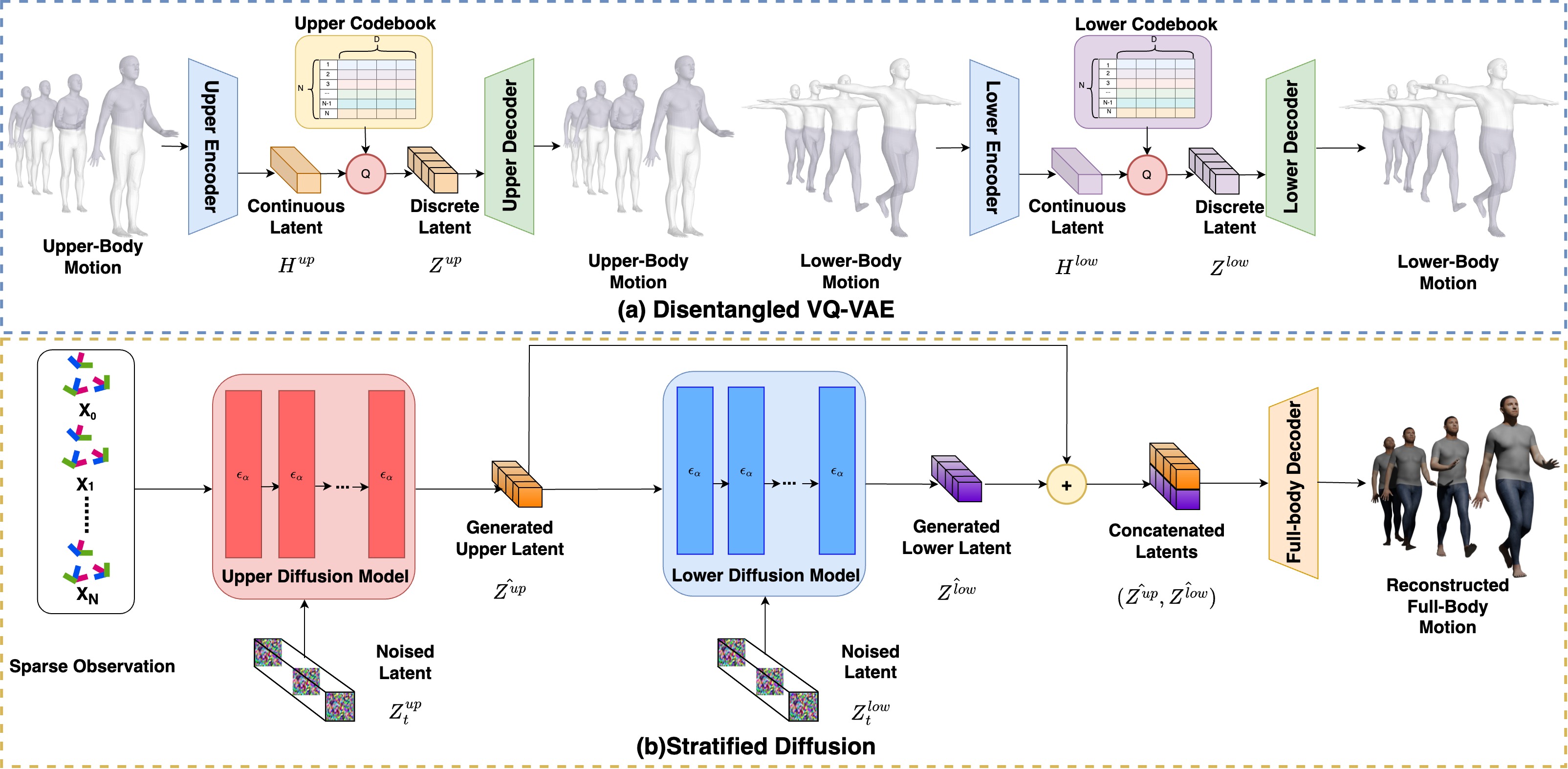
Stratified Avatar Generation from Sparse Observations
Han Feng, Wenchao Ma, Quankai Gao, Xianwei Zheng, Nan Xue, Huijuan Xu
0
0
Estimating 3D full-body avatars from AR/VR devices is essential for creating immersive experiences in AR/VR applications. This task is challenging due to the limited input from Head Mounted Devices, which capture only sparse observations from the head and hands. Predicting the full-body avatars, particularly the lower body, from these sparse observations presents significant difficulties. In this paper, we are inspired by the inherent property of the kinematic tree defined in the Skinned Multi-Person Linear (SMPL) model, where the upper body and lower body share only one common ancestor node, bringing the potential of decoupled reconstruction. We propose a stratified approach to decouple the conventional full-body avatar reconstruction pipeline into two stages, with the reconstruction of the upper body first and a subsequent reconstruction of the lower body conditioned on the previous stage. To implement this straightforward idea, we leverage the latent diffusion model as a powerful probabilistic generator, and train it to follow the latent distribution of decoupled motions explored by a VQ-VAE encoder-decoder model. Extensive experiments on AMASS mocap dataset demonstrate our state-of-the-art performance in the reconstruction of full-body motions.
6/4/2024
💬
SignAvatar: Sign Language 3D Motion Reconstruction and Generation
Lu Dong, Lipisha Chaudhary, Fei Xu, Xiao Wang, Mason Lary, Ifeoma Nwogu
0
0
Achieving expressive 3D motion reconstruction and automatic generation for isolated sign words can be challenging, due to the lack of real-world 3D sign-word data, the complex nuances of signing motions, and the cross-modal understanding of sign language semantics. To address these challenges, we introduce SignAvatar, a framework capable of both word-level sign language reconstruction and generation. SignAvatar employs a transformer-based conditional variational autoencoder architecture, effectively establishing relationships across different semantic modalities. Additionally, this approach incorporates a curriculum learning strategy to enhance the model's robustness and generalization, resulting in more realistic motions. Furthermore, we contribute the ASL3DWord dataset, composed of 3D joint rotation data for the body, hands, and face, for unique sign words. We demonstrate the effectiveness of SignAvatar through extensive experiments, showcasing its superior reconstruction and automatic generation capabilities. The code and dataset are available on the project page.
5/14/2024