Subspace-Configurable Networks

0
🏅
Sign in to get full access
Overview
- Deep learning models deployed on edge devices often lack robustness when faced with dynamic changes in sensor data
- This can be due to sensor drift or variations in data compared to offline training, caused by factors like sensor placement or changing sensing conditions
- Achieving robustness requires invariant architectures, specialized training like data augmentation, or post-deployment model adaptation
Plain English Explanation
Deep learning models are becoming more common in devices at the "edge" of a network, like smartphones or smart home sensors. However, these models can struggle to maintain their performance when the data they receive changes over time. This could happen if the sensors in the device gradually change or drift, or if the environment around the device changes, leading to different sensor readings than what the model was originally trained on.
To solve this problem, researchers have explored a few different approaches. One is to design the neural network architecture in a way that makes it invariant to certain types of changes in the input data. Another is to use specialized training techniques, like data augmentation, to expose the model to a wider range of potential sensor inputs during the training process.
Alternatively, the researchers in this paper propose treating the problem as one of "domain shift" - where the distribution of the input data changes between the training and deployment phases. They train a parameterized subspace of neural network configurations, which allows them to efficiently adapt the model to the new sensor data after deployment, without requiring a lot of extra storage or computation.
Technical Explanation
The key technical contribution of this paper is the training of a "subspace of configurable networks" (SCNs), where each point in the subspace represents a different neural network configuration that is optimal for a particular set of input transformations. The researchers show that this subspace has a surprisingly simple and low-dimensional structure, even for complex, non-invertible transformations of the input.
This allows the SCN model to efficiently adapt to changes in the sensor data after deployment, by selecting the appropriate network configuration from the pre-trained subspace. The researchers demonstrate the effectiveness of this approach on a range of computer vision tasks, showing that SCNs can maintain high performance in the face of significant input variations, while requiring much less storage and computation than alternative fine-tuning or adaptation methods.
The insights from this work build on existing research into equivariant neural networks, node pruning, and self-supervised learning of nonlinear modes - demonstrating how these principles can be leveraged to create highly efficient and adaptable deep learning models for edge deployment.
Critical Analysis
The researchers acknowledge several limitations of their approach. First, the effectiveness of the SCN model is dependent on the specific types of input transformations that are present in the deployment environment. If the actual changes in sensor data do not match the transformations represented in the pre-trained subspace, the model's adaptation capabilities will be limited.
Additionally, the training process for the SCN subspace can be computationally intensive, potentially limiting its practical applicability for certain resource-constrained edge devices. The researchers suggest that further research into more efficient subspace training algorithms could help address this.
Another area for potential improvement is the integration of the SCN approach with other robustness-enhancing techniques, such as data augmentation or equivariant network design. Combining these methods could lead to even more robust and adaptable deep learning models for edge deployment.
Conclusion
This paper presents an innovative approach to improving the robustness of deep learning models deployed on edge devices. By training a parameterized subspace of configurable neural networks, the researchers have demonstrated a highly efficient way to adapt models to dynamic changes in sensor data, without requiring significant additional resources.
While the current approach has some limitations, the insights from this work could have important implications for the development of reliable and adaptable AI systems at the edge of the network. As edge computing continues to grow in importance, techniques like the one described in this paper will become increasingly crucial for ensuring the real-world performance and longevity of deep learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Subspace-Configurable Networks
Dong Wang, Olga Saukh, Xiaoxi He, Lothar Thiele
While the deployment of deep learning models on edge devices is increasing, these models often lack robustness when faced with dynamic changes in sensed data. This can be attributed to sensor drift, or variations in the data compared to what was used during offline training due to factors such as specific sensor placement or naturally changing sensing conditions. Hence, achieving the desired robustness necessitates the utilization of either an invariant architecture or specialized training approaches, like data augmentation techniques. Alternatively, input transformations can be treated as a domain shift problem, and solved by post-deployment model adaptation. In this paper, we train a parameterized subspace of configurable networks, where an optimal network for a particular parameter setting is part of this subspace. The obtained subspace is low-dimensional and has a surprisingly simple structure even for complex, non-invertible transformations of the input, leading to an exceptionally high efficiency of subspace-configurable networks (SCNs) when limited storage and computing resources are at stake.
Read more5/29/2024

0
Invariant multiscale neural networks for data-scarce scientific applications
I. Schurov, D. Alforov, M. Katsnelson, A. Bagrov, A. Itin
Success of machine learning (ML) in the modern world is largely determined by abundance of data. However at many industrial and scientific problems, amount of data is limited. Application of ML methods to data-scarce scientific problems can be made more effective via several routes, one of them is equivariant neural networks possessing knowledge of symmetries. Here we suggest that combination of symmetry-aware invariant architectures and stacks of dilated convolutions is a very effective and easy to implement receipt allowing sizable improvements in accuracy over standard approaches. We apply it to representative physical problems from different realms: prediction of bandgaps of photonic crystals, and network approximations of magnetic ground states. The suggested invariant multiscale architectures increase expressibility of networks, which allow them to perform better in all considered cases.
Read more6/13/2024
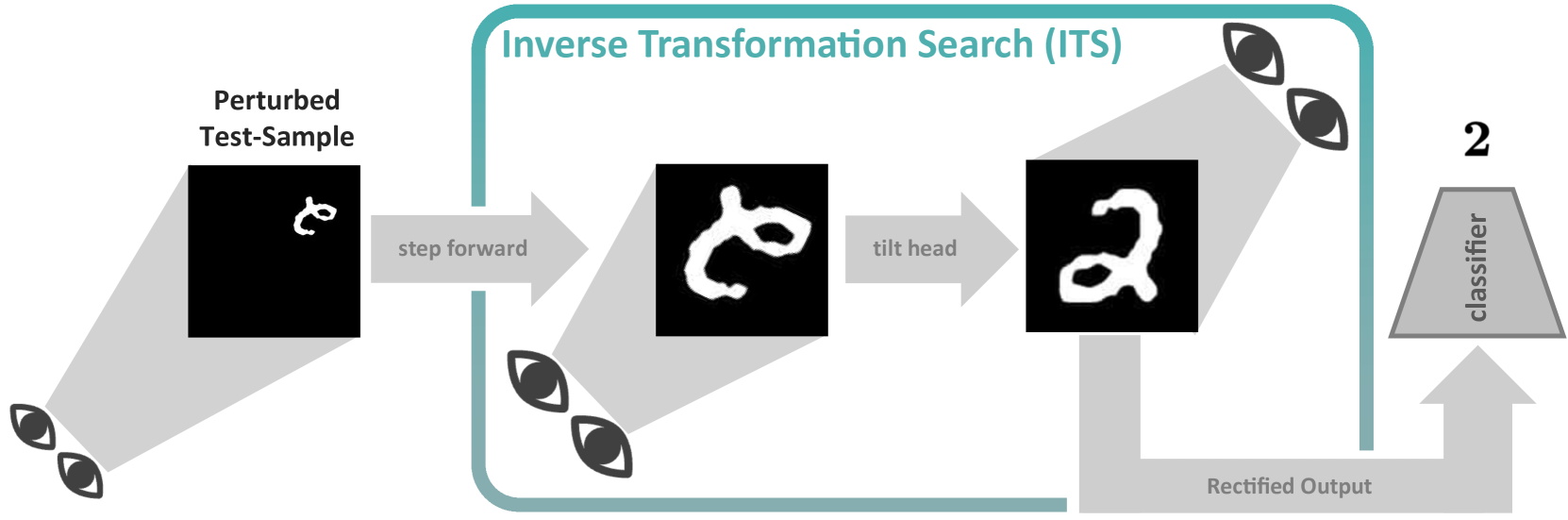
0
Tilt your Head: Activating the Hidden Spatial-Invariance of Classifiers
Johann Schmidt, Sebastian Stober
Deep neural networks are applied in more and more areas of everyday life. However, they still lack essential abilities, such as robustly dealing with spatially transformed input signals. Approaches to mitigate this severe robustness issue are limited to two pathways: Either models are implicitly regularised by increased sample variability (data augmentation) or explicitly constrained by hard-coded inductive biases. The limiting factor of the former is the size of the data space, which renders sufficient sample coverage intractable. The latter is limited by the engineering effort required to develop such inductive biases for every possible scenario. Instead, we take inspiration from human behaviour, where percepts are modified by mental or physical actions during inference. We propose a novel technique to emulate such an inference process for neural nets. This is achieved by traversing a sparsified inverse transformation tree during inference using parallel energy-based evaluations. Our proposed inference algorithm, called Inverse Transformation Search (ITS), is model-agnostic and equips the model with zero-shot pseudo-invariance to spatially transformed inputs. We evaluated our method on several benchmark datasets, including a synthesised ImageNet test set. ITS outperforms the utilised baselines on all zero-shot test scenarios.
Read more5/28/2024
🤿
0
Subspace Representation Learning for Sparse Linear Arrays to Localize More Sources than Sensors: A Deep Learning Methodology
Kuan-Lin Chen, Bhaskar D. Rao
Localizing more sources than sensors with a sparse linear array (SLA) has long relied on minimizing a distance between two covariance matrices and recent algorithms often utilize semidefinite programming (SDP). Although deep neural network (DNN)-based methods offer new alternatives, they still depend on covariance matrix fitting. In this paper, we develop a novel methodology that estimates the co-array subspaces from a sample covariance for SLAs. Our methodology trains a DNN to learn signal and noise subspace representations that are invariant to the selection of bases. To learn such representations, we propose loss functions that gauge the separation between the desired and the estimated subspace. In particular, we propose losses that measure the length of the shortest path between subspaces viewed on a union of Grassmannians, and prove that it is possible for a DNN to approximate signal subspaces. The computation of learning subspaces of different dimensions is accelerated by a new batch sampling strategy called consistent rank sampling. The methodology is robust to array imperfections due to its geometry-agnostic and data-driven nature. In addition, we propose a fully end-to-end gridless approach that directly learns angles to study the possibility of bypassing subspace methods. Numerical results show that learning such subspace representations is more beneficial than learning covariances or angles. It outperforms conventional SDP-based methods such as the sparse and parametric approach (SPA) and existing DNN-based covariance reconstruction methods for a wide range of signal-to-noise ratios (SNRs), snapshots, and source numbers for both perfect and imperfect arrays.
Read more8/30/2024