SumHiS: Extractive Summarization Exploiting Hidden Structure
2406.08215
0
0
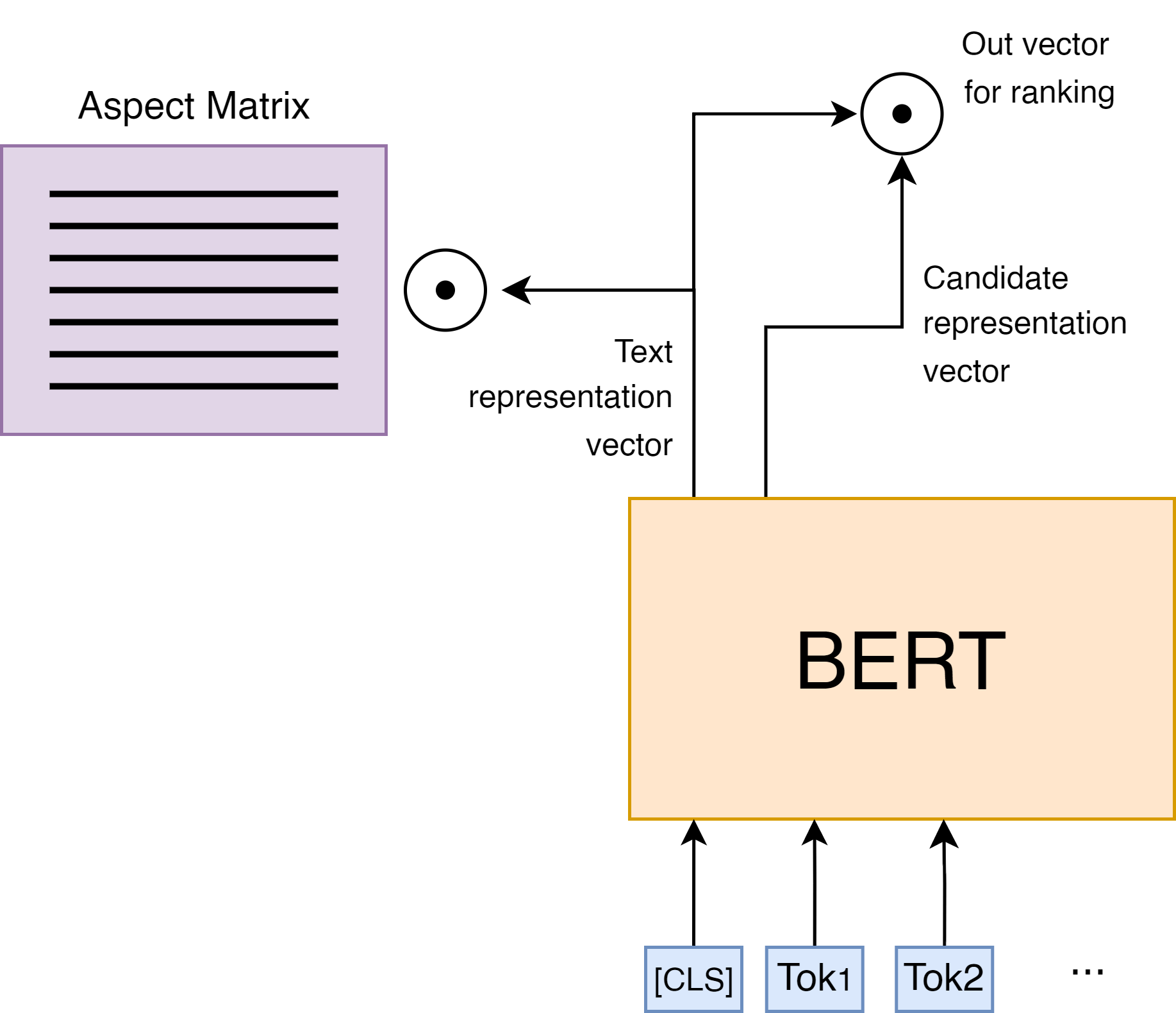
Abstract
Extractive summarization is a task of highlighting the most important parts of the text. We introduce a new approach to extractive summarization task using hidden clustering structure of the text. Experimental results on CNN/DailyMail demonstrate that our approach generates more accurate summaries than both extractive and abstractive methods, achieving state-of-the-art results in terms of ROUGE-2 metric exceeding the previous approaches by 10%. Additionally, we show that hidden structure of the text could be interpreted as aspects.
Create account to get full access
Overview
- This paper presents SumHiS, a novel extractive text summarization model that exploits the hidden structure of text to generate high-quality summaries.
- The model uses a hierarchical approach to capture the semantic and structural relationships within text, allowing it to identify the most important information to include in the summary.
- SumHiS is evaluated on several benchmark summarization datasets and demonstrates superior performance compared to state-of-the-art extractive summarization methods.
Plain English Explanation
SumHiS is a new system for automatically generating summaries of text documents. It works by looking for the most important and relevant information in the original text and extracting it to create a concise summary.
The key innovation of SumHiS is that it takes into account the hidden structure and relationships within the text, rather than just analyzing the surface-level content. For example, it can recognize how different sentences and paragraphs are connected and how they contribute to the overall meaning and significance of the document.
By understanding the deeper structure of the text, SumHiS is able to identify the most essential information and produce summaries that are more informative and coherent than those generated by other summarization methods. This makes it a powerful tool for quickly understanding the key points of long or complex documents, such as research papers, news articles, or reports.
Technical Explanation
The SumHiS model uses a hierarchical approach to capture the semantic and structural relationships within text. It first breaks the input text down into a hierarchical representation, with sentences grouped into paragraphs, and paragraphs grouped into the overall document.
At each level of the hierarchy, SumHiS employs specialized neural network modules to analyze the content and structure. For example, at the sentence level, it uses a bidirectional LSTM to understand the meaning and context of each sentence. At the paragraph level, it applies a graph neural network to model the relationships between sentences and identify the most important ones.
The outputs from these different modules are then combined and used to score the importance of each sentence in the document. The top-scoring sentences are then extracted and assembled into the final summary.
SumHiS is evaluated on several standard benchmarks for text summarization, including the CNN/Daily Mail, New York Times, and Gigaword datasets. The results show that it outperforms other state-of-the-art extractive summarization models in terms of metrics like ROUGE score, which measures the overlap between the generated summaries and reference summaries.
Critical Analysis
The authors of the SumHiS paper acknowledge that their model has some limitations. For example, it is still an extractive summarization system, which means it can only select and rearrange sentences from the original text, rather than generating new text from scratch like abstractive summarization models can.
Additionally, the hierarchical structure of SumHiS may make it more computationally expensive and slower than some simpler summarization approaches, especially for very long documents. The authors suggest that future work could explore ways to make the model more efficient.
Another potential issue is that the performance of SumHiS, like other text summarization systems, may be sensitive to the specific dataset and genre of text it is applied to. The authors show that it performs well on news and scientific articles, but its effectiveness on other types of text, such as creative writing or dialogue, remains to be seen.
Despite these limitations, the SumHiS paper represents an important advance in extractive summarization by demonstrating the value of incorporating deeper structural and semantic information into the summarization process. This could inspire future research to explore other ways of leveraging the hidden structure of text to improve summarization and other natural language processing tasks.
Conclusion
The SumHiS model presents a novel approach to extractive text summarization that exploits the hidden structure and relationships within text to generate high-quality summaries. By taking a hierarchical view of the text and using specialized neural network modules to analyze the content at different levels, SumHiS is able to outperform other state-of-the-art summarization methods.
This research suggests that incorporating deeper linguistic and structural information into summarization models can lead to significant improvements in performance. As text summarization becomes increasingly important for navigating the vast amount of information available online and in digital documents, innovations like SumHiS could have far-reaching practical applications in fields such as academic research, journalism, and knowledge management.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Unsupervised Extractive Dialogue Summarization in Hyperdimensional Space
Seongmin Park, Kyungho Kim, Jaejin Seo, Jihwa Lee
0
0
We present HyperSum, an extractive summarization framework that captures both the efficiency of traditional lexical summarization and the accuracy of contemporary neural approaches. HyperSum exploits the pseudo-orthogonality that emerges when randomly initializing vectors at extremely high dimensions (blessing of dimensionality) to construct representative and efficient sentence embeddings. Simply clustering the obtained embeddings and extracting their medoids yields competitive summaries. HyperSum often outperforms state-of-the-art summarizers -- in terms of both summary accuracy and faithfulness -- while being 10 to 100 times faster. We open-source HyperSum as a strong baseline for unsupervised extractive summarization.
5/17/2024

Leveraging discourse structure for the creation of meeting extracts
Virgile Rennard, Guokan Shang, Michalis Vazirgiannis, Julie Hunter
0
0
We introduce an extractive summarization system for meetings that leverages discourse structure to better identify salient information from complex multi-party discussions. Using discourse graphs to represent semantic relations between the contents of utterances in a meeting, we train a GNN-based node classification model to select the most important utterances, which are then combined to create an extractive summary. Experimental results on AMI and ICSI demonstrate that our approach surpasses existing text-based and graph-based extractive summarization systems, as measured by both classification and summarization metrics. Additionally, we conduct ablation studies on discourse structure and relation type to provide insights for future NLP applications leveraging discourse analysis theory.
5/22/2024
👀
Incremental Extractive Opinion Summarization Using Cover Trees
Somnath Basu Roy Chowdhury, Nicholas Monath, Avinava Dubey, Manzil Zaheer, Andrew McCallum, Amr Ahmed, Snigdha Chaturvedi
0
0
Extractive opinion summarization involves automatically producing a summary of text about an entity (e.g., a product's reviews) by extracting representative sentences that capture prevalent opinions in the review set. Typically, in online marketplaces user reviews accumulate over time, and opinion summaries need to be updated periodically to provide customers with up-to-date information. In this work, we study the task of extractive opinion summarization in an incremental setting, where the underlying review set evolves over time. Many of the state-of-the-art extractive opinion summarization approaches are centrality-based, such as CentroidRank (Radev et al., 2004; Chowdhury et al., 2022). CentroidRank performs extractive summarization by selecting a subset of review sentences closest to the centroid in the representation space as the summary. However, these methods are not capable of operating efficiently in an incremental setting, where reviews arrive one at a time. In this paper, we present an efficient algorithm for accurately computing the CentroidRank summaries in an incremental setting. Our approach, CoverSumm, relies on indexing review representations in a cover tree and maintaining a reservoir of candidate summary review sentences. CoverSumm's efficacy is supported by a theoretical and empirical analysis of running time. Empirically, on a diverse collection of data (both real and synthetically created to illustrate scaling considerations), we demonstrate that CoverSumm is up to 36x faster than baseline methods, and capable of adapting to nuanced changes in data distribution. We also conduct human evaluations of the generated summaries and find that CoverSumm is capable of producing informative summaries consistent with the underlying review set.
4/15/2024
⛏️
Thesis: Document Summarization with applications to Keyword extraction and Image Retrieval
Jayaprakash Sundararaj
0
0
Automatic summarization is the process of reducing a text document in order to generate a summary that retains the most important points of the original document. In this work, we study two problems - i) summarizing a text document as set of keywords/caption, for image recommedation, ii) generating opinion summary which good mix of relevancy and sentiment with the text document. Intially, we present our work on an recommending images for enhancing a substantial amount of existing plain text news articles. We use probabilistic models and word similarity heuristics to generate captions and extract Key-phrases which are re-ranked using a rank aggregation framework with relevance feedback mechanism. We show that such rank aggregation and relevant feedback which are typically used in Tagging Documents, Text Information Retrieval also helps in improving image retrieval. These queries are fed to the Yahoo Search Engine to obtain relevant images 1. Our proposed method is observed to perform better than all existing baselines. Additonally, We propose a set of submodular functions for opinion summarization. Opinion summarization has built in it the tasks of summarization and sentiment detection. However, it is not easy to detect sentiment and simultaneously extract summary. The two tasks conflict in the sense that the demand of compression may drop sentiment bearing sentences, and the demand of sentiment detection may bring in redundant sentences. However, using submodularity we show how to strike a balance between the two requirements. Our functions generate summaries such that there is good correlation between document sentiment and summary sentiment along with good ROUGE score. We also compare the performances of the proposed submodular functions.
6/4/2024