Unsupervised Extractive Dialogue Summarization in Hyperdimensional Space
2405.09765
0
0
Abstract
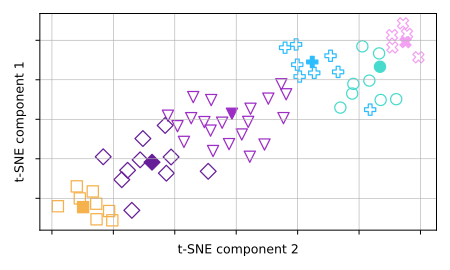
We present HyperSum, an extractive summarization framework that captures both the efficiency of traditional lexical summarization and the accuracy of contemporary neural approaches. HyperSum exploits the pseudo-orthogonality that emerges when randomly initializing vectors at extremely high dimensions (blessing of dimensionality) to construct representative and efficient sentence embeddings. Simply clustering the obtained embeddings and extracting their medoids yields competitive summaries. HyperSum often outperforms state-of-the-art summarizers -- in terms of both summary accuracy and faithfulness -- while being 10 to 100 times faster. We open-source HyperSum as a strong baseline for unsupervised extractive summarization.
Create account to get full access
Overview
- This paper proposes an unsupervised approach for extractive dialogue summarization using hyperdimensional computing.
- The method aims to identify the most salient utterances in a dialogue and generate a concise summary without the need for human-annotated training data.
- The authors leverage the inherent structure and semantics of dialogue to learn effective representations in a high-dimensional space.
Plain English Explanation
The researchers have developed a new way to automatically summarize dialogues, such as conversations, without requiring any manually-created training data. Instead, their approach relies on the natural structure and meaning of the dialogue itself to identify the most important parts and generate a concise summary.
The key idea is to represent each utterance (or sentence) in the dialogue as a point in a high-dimensional space, where similar utterances are close together. [This is similar to how we can represent words in a way that captures their semantic relationships, as explored in the paper on Hierarchical Attention Graphs for Scientific Document Summarization.] By analyzing the relationships between these utterance representations, the system can determine which parts of the dialogue are the most essential and should be included in the summary.
This unsupervised approach, meaning it doesn't require any manually-labeled training data, is advantageous because it can be applied to a wide range of dialogues without the need for costly human annotation. It also has the potential to capture the nuances and context-specific importance of different parts of the conversation, which can be challenging for more traditional summarization methods.
Technical Explanation
The paper presents an unsupervised extractive dialogue summarization method that operates in a high-dimensional semantic space. The key steps of the approach are:
-
Utterance Encoding: Each utterance in the dialogue is represented as a high-dimensional vector using a pre-trained language model, such as BERT. This encodes the semantic and syntactic content of the utterance.
-
Utterance Similarity: The similarity between pairs of utterance vectors is computed using cosine similarity. This captures the semantic relatedness between different parts of the dialogue.
-
Importance Scoring: Based on the utterance similarity matrix, the system computes an importance score for each utterance. Utterances that are more similar to their neighboring utterances are considered more important and should be included in the summary.
-
Extractive Summarization: The top-ranked utterances according to the importance scores are extracted to form the final summary. The authors experiment with different strategies for selecting the most salient utterances.
The authors evaluate their method on several dialogue summarization benchmarks and show that it outperforms various unsupervised baselines, as well as some supervised approaches. The results demonstrate the effectiveness of leveraging the inherent structure of dialogues to perform extractive summarization in a data-efficient manner.
Critical Analysis
The paper presents a novel and promising approach to unsupervised dialogue summarization. By representing utterances in a high-dimensional semantic space and analyzing their relationships, the method can capture the contextual importance of different parts of the conversation without relying on manually-annotated training data.
However, the authors acknowledge that their method has some limitations. For example, the quality of the summaries may be affected by the performance of the pre-trained language model used for utterance encoding. Additionally, the extractive nature of the summarization means that the method may not be able to capture the overall flow and cohesion of the dialogue as effectively as abstractive summarization techniques.
[Further research could explore ways to integrate the strengths of this unsupervised extractive approach with more sophisticated abstractive summarization models, as demonstrated in the paper on Incremental Extractive Opinion Summarization Using Cover Trees.] This could potentially lead to even more effective and comprehensive dialogue summarization systems.
Conclusion
This paper presents a novel unsupervised approach for extractive dialogue summarization that leverages the inherent structure and semantics of the dialogue. By representing utterances in a high-dimensional space and analyzing their relationships, the method can identify the most salient parts of the conversation and generate concise summaries without the need for human-annotated training data.
The results demonstrate the effectiveness of this data-efficient approach, which has the potential to be applied to a wide range of dialogue scenarios. While the method has some limitations, the authors' work provides a valuable contribution to the field of dialogue summarization and highlights the potential of using high-dimensional representations to capture the nuances of language interactions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
SumHiS: Extractive Summarization Exploiting Hidden Structure
Tikhonov Pavel, Anastasiya Ianina, Valentin Malykh
0
0
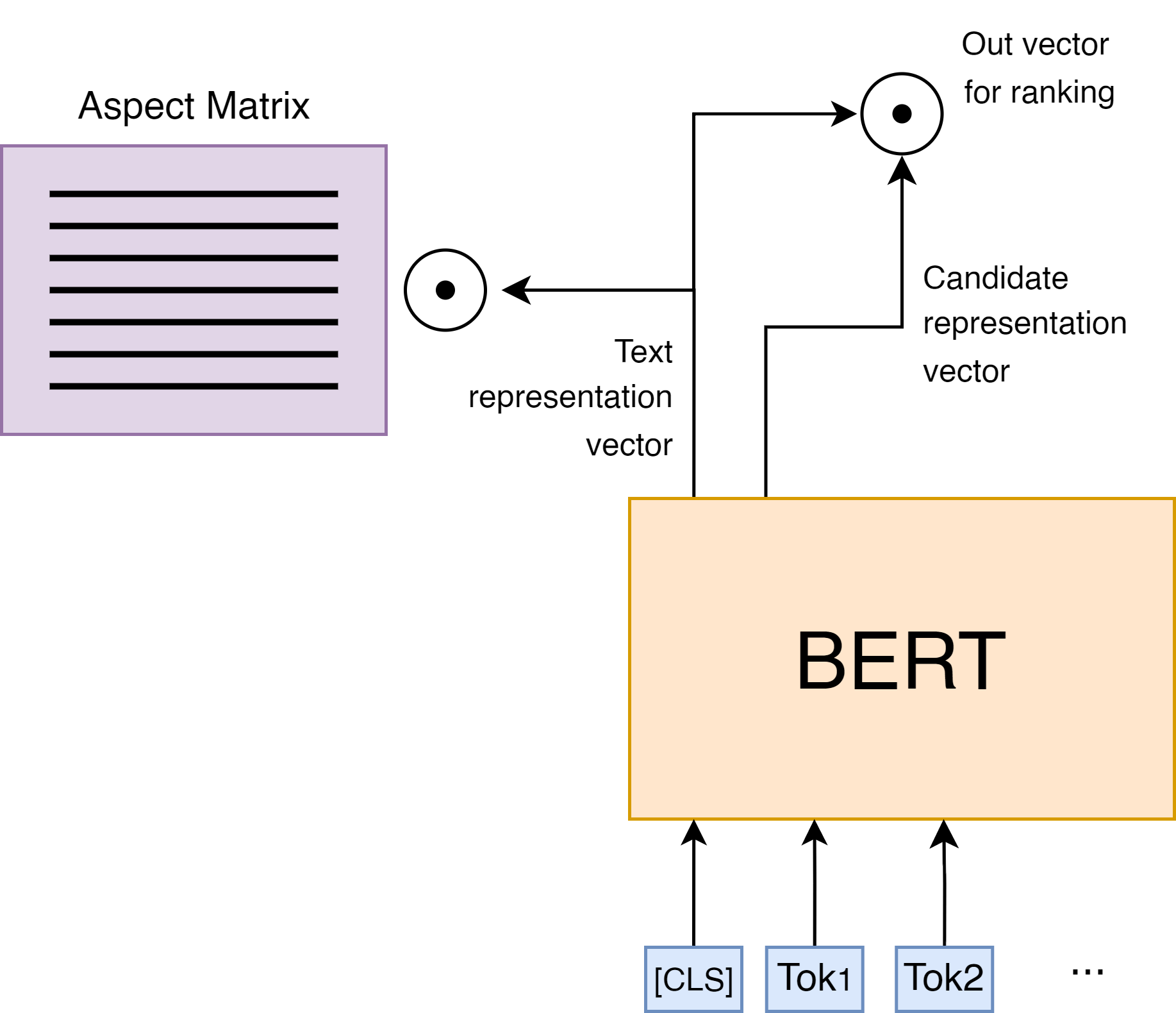
Extractive summarization is a task of highlighting the most important parts of the text. We introduce a new approach to extractive summarization task using hidden clustering structure of the text. Experimental results on CNN/DailyMail demonstrate that our approach generates more accurate summaries than both extractive and abstractive methods, achieving state-of-the-art results in terms of ROUGE-2 metric exceeding the previous approaches by 10%. Additionally, we show that hidden structure of the text could be interpreted as aspects.
6/13/2024
Converging Dimensions: Information Extraction and Summarization through Multisource, Multimodal, and Multilingual Fusion
Pranav Janjani, Mayank Palan, Sarvesh Shirude, Ninad Shegokar, Sunny Kumar, Faruk Kazi
0
0
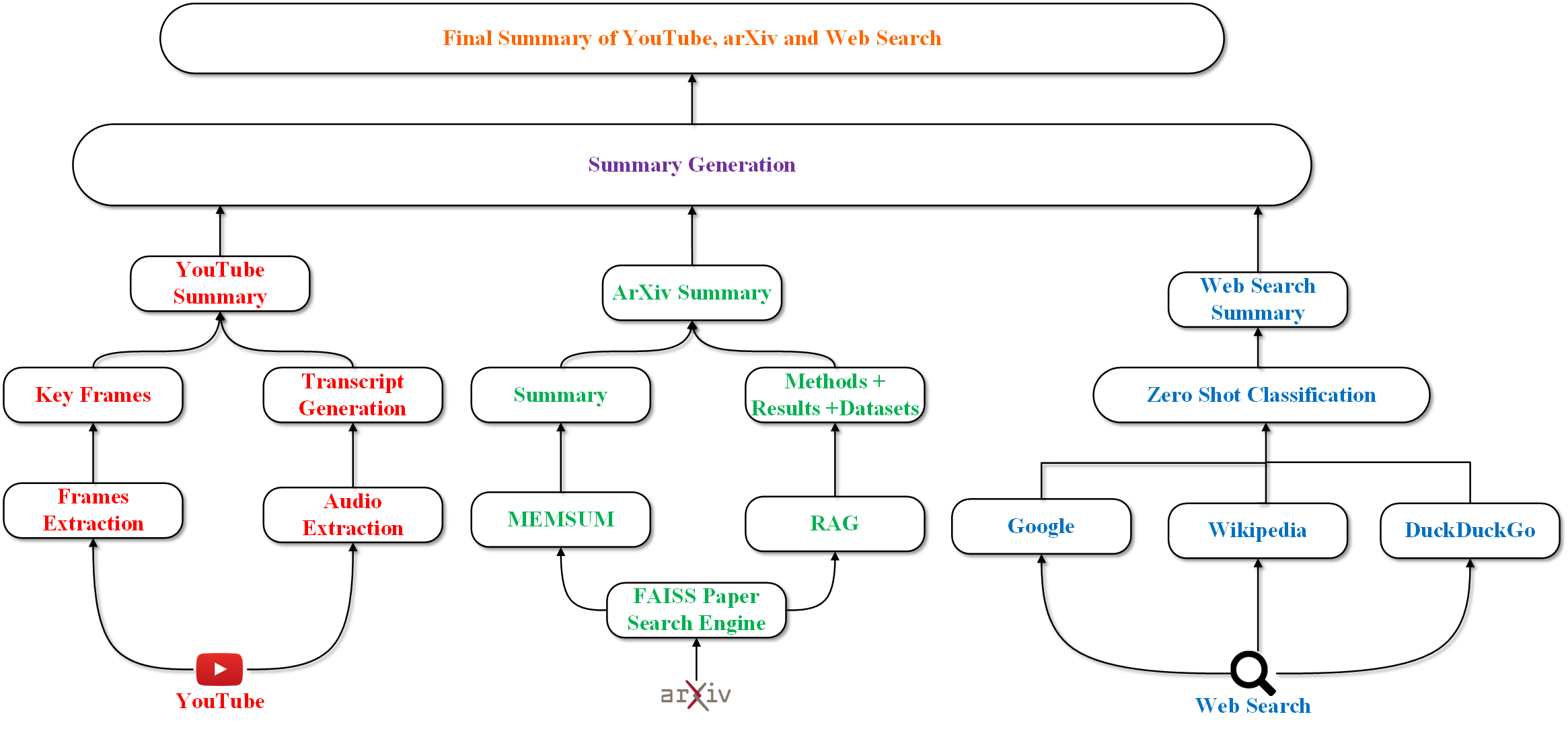
Recent advances in large language models (LLMs) have led to new summarization strategies, offering an extensive toolkit for extracting important information. However, these approaches are frequently limited by their reliance on isolated sources of data. The amount of information that can be gathered is limited and covers a smaller range of themes, which introduces the possibility of falsified content and limited support for multilingual and multimodal data. The paper proposes a novel approach to summarization that tackles such challenges by utilizing the strength of multiple sources to deliver a more exhaustive and informative understanding of intricate topics. The research progresses beyond conventional, unimodal sources such as text documents and integrates a more diverse range of data, including YouTube playlists, pre-prints, and Wikipedia pages. The aforementioned varied sources are then converted into a unified textual representation, enabling a more holistic analysis. This multifaceted approach to summary generation empowers us to extract pertinent information from a wider array of sources. The primary tenet of this approach is to maximize information gain while minimizing information overlap and maintaining a high level of informativeness, which encourages the generation of highly coherent summaries.
6/21/2024

Hierarchical Attention Graph for Scientific Document Summarization in Global and Local Level
Chenlong Zhao, Xiwen Zhou, Xiaopeng Xie, Yong Zhang
0
0
Scientific document summarization has been a challenging task due to the long structure of the input text. The long input hinders the simultaneous effective modeling of both global high-order relations between sentences and local intra-sentence relations which is the most critical step in extractive summarization. However, existing methods mostly focus on one type of relation, neglecting the simultaneous effective modeling of both relations, which can lead to insufficient learning of semantic representations. In this paper, we propose HAESum, a novel approach utilizing graph neural networks to locally and globally model documents based on their hierarchical discourse structure. First, intra-sentence relations are learned using a local heterogeneous graph. Subsequently, a novel hypergraph self-attention layer is introduced to further enhance the characterization of high-order inter-sentence relations. We validate our approach on two benchmark datasets, and the experimental results demonstrate the effectiveness of HAESum and the importance of considering hierarchical structures in modeling long scientific documents. Our code will be available at url{https://github.com/MoLICHENXI/HAESum}
5/17/2024
👀
Incremental Extractive Opinion Summarization Using Cover Trees
Somnath Basu Roy Chowdhury, Nicholas Monath, Avinava Dubey, Manzil Zaheer, Andrew McCallum, Amr Ahmed, Snigdha Chaturvedi
0
0
Extractive opinion summarization involves automatically producing a summary of text about an entity (e.g., a product's reviews) by extracting representative sentences that capture prevalent opinions in the review set. Typically, in online marketplaces user reviews accumulate over time, and opinion summaries need to be updated periodically to provide customers with up-to-date information. In this work, we study the task of extractive opinion summarization in an incremental setting, where the underlying review set evolves over time. Many of the state-of-the-art extractive opinion summarization approaches are centrality-based, such as CentroidRank (Radev et al., 2004; Chowdhury et al., 2022). CentroidRank performs extractive summarization by selecting a subset of review sentences closest to the centroid in the representation space as the summary. However, these methods are not capable of operating efficiently in an incremental setting, where reviews arrive one at a time. In this paper, we present an efficient algorithm for accurately computing the CentroidRank summaries in an incremental setting. Our approach, CoverSumm, relies on indexing review representations in a cover tree and maintaining a reservoir of candidate summary review sentences. CoverSumm's efficacy is supported by a theoretical and empirical analysis of running time. Empirically, on a diverse collection of data (both real and synthetically created to illustrate scaling considerations), we demonstrate that CoverSumm is up to 36x faster than baseline methods, and capable of adapting to nuanced changes in data distribution. We also conduct human evaluations of the generated summaries and find that CoverSumm is capable of producing informative summaries consistent with the underlying review set.
4/15/2024