Super-High-Fidelity Image Compression via Hierarchical-ROI and Adaptive Quantization
2403.13030
0
0
Abstract
Learned Image Compression (LIC) has achieved dramatic progress regarding objective and subjective metrics. MSE-based models aim to improve objective metrics while generative models are leveraged to improve visual quality measured by subjective metrics. However, they all suffer from blurring or deformation at low bit rates, especially at below $0.2bpp$. Besides, deformation on human faces and text is unacceptable for visual quality assessment, and the problem becomes more prominent on small faces and text. To solve this problem, we combine the advantage of MSE-based models and generative models by utilizing region of interest (ROI). We propose Hierarchical-ROI (H-ROI), to split images into several foreground regions and one background region to improve the reconstruction of regions containing faces, text, and complex textures. Further, we propose adaptive quantization by non-linear mapping within the channel dimension to constrain the bit rate while maintaining the visual quality. Exhaustive experiments demonstrate that our methods achieve better visual quality on small faces and text with lower bit rates, e.g., $0.7X$ bits of HiFiC and $0.5X$ bits of BPG.
Create account to get full access
Overview
- The paper introduces a novel image compression technique that combines a hierarchical region-of-interest (ROI) approach with adaptive quantization.
- The proposed method aims to achieve super-high-fidelity image compression, prioritizing the most important regions while maintaining overall image quality.
- The paper includes details on the dataset used, qualitative results, and technical explanations of the object codec and adaptive quantization components.
Plain English Explanation
The researchers have developed a new way to compress images very efficiently without losing a lot of quality. The key idea is to focus on the most important parts of the image and compress those areas less, while compressing the less important parts more. This hierarchical-ROI and adaptive quantization approach allows them to maintain high-fidelity in the regions that matter most, while still achieving substantial overall file size reduction.
The paper provides examples showing how this technique can preserve fine details and sharp edges in critical image regions, while compressing the background and less-important areas more aggressively. This could be especially useful for optimizing traffic signs and lights visibility for teleoperation and autonomous systems, or enhancing the quality of remote sensing images where certain areas are more crucial than others.
Technical Explanation
The paper introduces a novel image and video compression technique using generative sparse representation that combines a hierarchical region-of-interest (ROI) approach with adaptive quantization.
The key components are:
- Hierarchical-ROI: The authors divide the image into a hierarchy of regions, with the most important areas receiving the highest priority for preserving quality. This allows them to focus compression efforts on the critical parts of the image.
- Adaptive Quantization: The quantization step in the compression pipeline is adapted based on the region's priority, with higher-priority areas undergoing less aggressive quantization to maintain fidelity.
The paper evaluates this approach on a custom high-quality image dataset and presents qualitative results demonstrating the ability to preserve fine details and sharp edges in the most important image regions while heavily compressing the less critical areas.
Critical Analysis
The paper provides a thorough technical explanation of the proposed hierarchical-ROI and adaptive quantization approach, and the qualitative results are impressive, showing the method's ability to maintain super-high-fidelity in critical image regions.
However, the paper does not include any quantitative evaluation or comparison to other state-of-the-art compression techniques. While the qualitative results are compelling, it would be helpful to see how this approach performs in terms of objective metrics like rate-distortion classification for lossy image compression or image quality assessment using compressive sampling.
Additionally, the paper does not discuss the computational complexity or runtime performance of the proposed method, which could be important factors for real-world deployment, especially in latency-sensitive applications like autonomous driving or remote teleoperation.
Conclusion
The paper presents a promising approach to achieving super-high-fidelity image compression by combining a hierarchical-ROI strategy with adaptive quantization. This technique has the potential to significantly improve the quality of compressed images in applications where certain regions are more important than others, such as autonomous vehicles, remote sensing, and medical imaging.
While the qualitative results are compelling, future work should include a more comprehensive quantitative evaluation and analysis of the method's computational efficiency. Overall, this research represents an interesting advancement in the field of image compression and could lead to practical applications that enhance the performance and user experience in a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

S-IQA Image Quality Assessment With Compressive Sampling
Ronghua Liao, Chen Hui, Lang Yuan, Feng Jiang
0
0
No-Reference Image Quality Assessment (IQA) aims at estimating image quality in accordance with subjective human perception. However, most existing NR-IQA methods focus on exploring increasingly complex networks or components to improve the final performance. Such practice imposes great limitations and complexity on IQA methods, especially when they are applied to high-resolution (HR) images in the real world. Actually, most images own high spatial redundancy, especially for those HR data. To further exploit the characteristic and alleviate the issue above, we propose a new framework for Image Quality Assessment with compressive Sampling (dubbed S-IQA), which consists of three components: (1) The Flexible Sampling Module (FSM) samples the image to obtain measurements at an arbitrary ratio. (2) Vision Transformer with the Adaptive Embedding Module (AEM) makes measurements of uniform size and extracts deep features (3) Dual Branch (DB) allocates weight for every patch and predicts the final quality score. Experiments show that our proposed S-IQA achieves state-of-the-art result on various datasets with less data usage.
4/29/2024
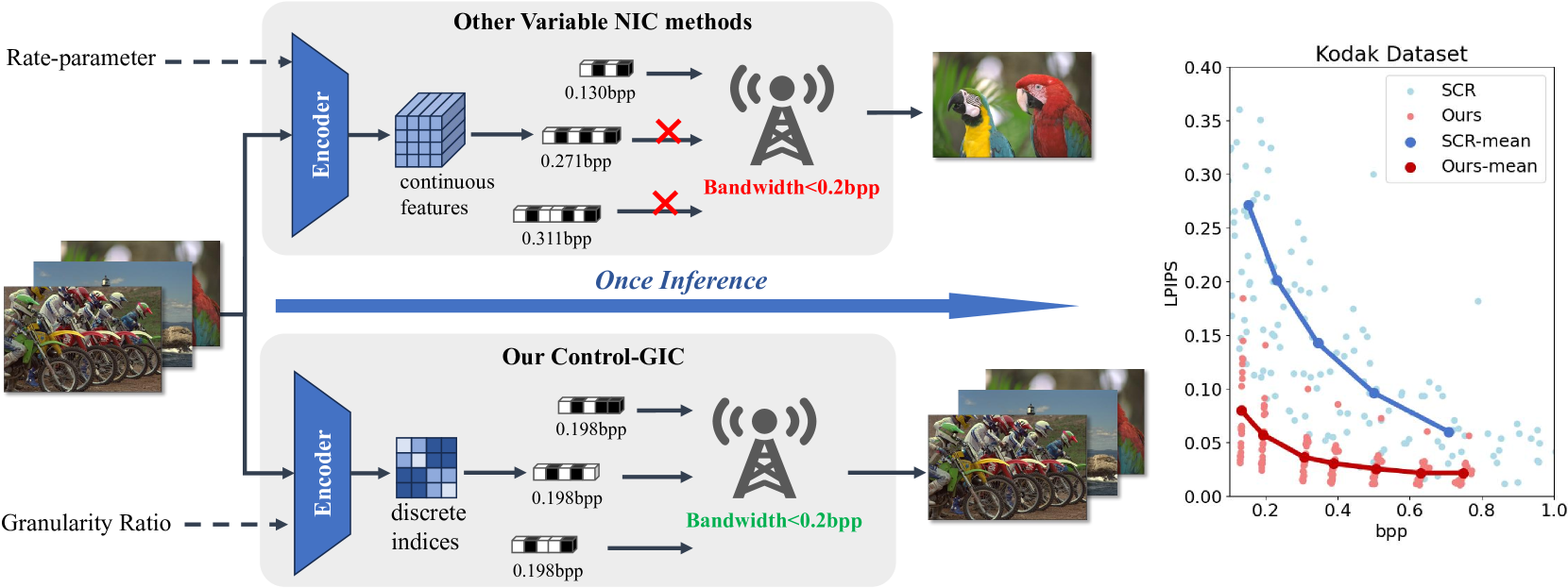
Once-for-All: Controllable Generative Image Compression with Dynamic Granularity Adaption
Anqi Li, Yuxi Liu, Huihui Bai, Feng Li, Runmin Cong, Meng Wang, Yao Zhao
0
0
Although recent generative image compression methods have demonstrated impressive potential in optimizing the rate-distortion-perception trade-off, they still face the critical challenge of flexible rate adaption to diverse compression necessities and scenarios. To overcome this challenge, this paper proposes a Controllable Generative Image Compression framework, Control-GIC, the first capable of fine-grained bitrate adaption across a broad spectrum while ensuring high-fidelity and generality compression. We base Control-GIC on a VQGAN framework representing an image as a sequence of variable-length codes (i.e. VQ-indices), which can be losslessly compressed and exhibits a direct positive correlation with the bitrates. Therefore, drawing inspiration from the classical coding principle, we naturally correlate the information density of local image patches with their granular representations, to achieve dynamic adjustment of the code quantity following different granularity decisions. This implies we can flexibly determine a proper allocation of granularity for the patches to acquire desirable compression rates. We further develop a probabilistic conditional decoder that can trace back to historic encoded multi-granularity representations according to transmitted codes, and then reconstruct hierarchical granular features in the formalization of conditional probability, enabling more informative aggregation to improve reconstruction realism. Our experiments show that Control-GIC allows highly flexible and controllable bitrate adaption and even once compression on an entire dataset to fulfill constrained bitrate conditions. Experimental results demonstrate its superior performance over recent state-of-the-art methods.
6/6/2024

Neural Image Compression with Text-guided Encoding for both Pixel-level and Perceptual Fidelity
Hagyeong Lee, Minkyu Kim, Jun-Hyuk Kim, Seungeon Kim, Dokwan Oh, Jaeho Lee
0
0
Recent advances in text-guided image compression have shown great potential to enhance the perceptual quality of reconstructed images. These methods, however, tend to have significantly degraded pixel-wise fidelity, limiting their practicality. To fill this gap, we develop a new text-guided image compression algorithm that achieves both high perceptual and pixel-wise fidelity. In particular, we propose a compression framework that leverages text information mainly by text-adaptive encoding and training with joint image-text loss. By doing so, we avoid decoding based on text-guided generative models -- known for high generative diversity -- and effectively utilize the semantic information of text at a global level. Experimental results on various datasets show that our method can achieve high pixel-level and perceptual quality, with either human- or machine-generated captions. In particular, our method outperforms all baselines in terms of LPIPS, with some room for even more improvements when we use more carefully generated captions.
5/24/2024

Region of Interest Loss for Anonymizing Learned Image Compression
Christoph Liebender, Ranulfo Bezerra, Kazunori Ohno, Satoshi Tadokoro
0
0
The use of AI in public spaces continually raises concerns about privacy and the protection of sensitive data. An example is the deployment of detection and recognition methods on humans, where images are provided by surveillance cameras. This results in the acquisition of great amounts of sensitive data, since the capture and transmission of images taken by such cameras happens unaltered, for them to be received by a server on the network. However, many applications do not explicitly require the identity of a given person in a scene; An anonymized representation containing information of the person's position while preserving the context of them in the scene suffices. We show how using a customized loss function on region of interests (ROI) can achieve sufficient anonymization such that human faces become unrecognizable while persons are kept detectable, by training an end-to-end optimized autoencoder for learned image compression that utilizes the flexibility of the learned analysis and reconstruction transforms for the task of mutating parts of the compression result. This approach enables compression and anonymization in one step on the capture device, instead of transmitting sensitive, nonanonymized data over the network. Additionally, we evaluate how this anonymization impacts the average precision of pre-trained foundation models on detecting faces (MTCNN) and humans (YOLOv8) in comparison to non-ANN based methods, while considering compression rate and latency.
6/11/2024