Image and Video Compression using Generative Sparse Representation with Fidelity Controls
2404.06076
0
0

Abstract
We propose a framework for learned image and video compression using the generative sparse visual representation (SVR) guided by fidelity-preserving controls. By embedding inputs into a discrete latent space spanned by learned visual codebooks, SVR-based compression transmits integer codeword indices, which is efficient and cross-platform robust. However, high-quality (HQ) reconstruction in the decoder relies on intermediate feature inputs from the encoder via direct connections. Due to the prohibitively high transmission costs, previous SVR-based compression methods remove such feature links, resulting in largely degraded reconstruction quality. In this work, we treat the intermediate features as fidelity-preserving control signals that guide the conditioned generative reconstruction in the decoder. Instead of discarding or directly transferring such signals, we draw them from a low-quality (LQ) fidelity-preserving alternative input that is sent to the decoder with very low bitrate. These control signals provide complementary fidelity cues to improve reconstruction, and their quality is determined by the compression rate of the LQ alternative, which can be tuned to trade off bitrate, fidelity and perceptual quality. Our framework can be conveniently used for both learned image compression (LIC) and learned video compression (LVC). Since SVR is robust against input perturbations, a large portion of codeword indices between adjacent frames can be the same. By only transferring different indices, SVR-based LIC and LVC can share a similar processing pipeline. Experiments over standard image and video compression benchmarks demonstrate the effectiveness of our approach.
Create account to get full access
Overview
- Proposes a new method for image and video compression using generative sparse representation with fidelity controls
- Aims to improve upon existing compression techniques by leveraging generative models and sparse representation
- Introduces a framework that allows for tuning the balance between compression efficiency and visual fidelity
Plain English Explanation
This paper presents a novel approach to compressing images and videos more efficiently while still maintaining high visual quality. The key idea is to use a generative model, which is a type of machine learning algorithm that can create new data that looks similar to the original.
By representing the image or video as a sparse set of parameters, the researchers were able to achieve higher compression rates compared to traditional methods. Sparse representation means that only the most important features are encoded, reducing the overall file size.
Importantly, the framework they developed also allows users to control the trade-off between compression efficiency and visual fidelity. This means you can choose to prioritize smaller file sizes or better image/video quality depending on your needs.
The paper builds on related work in areas like convolutional variational autoencoders for secure lossy image compression, stylizing sparse view 3D scenes, and sparse controlled video to 4D generation. By combining generative models, sparse representation, and fidelity controls, the authors aim to advance the state-of-the-art in image and video compression.
Technical Explanation
The core technical contribution is a framework that leverages generative sparse representation to enable efficient image and video compression with fidelity controls.
At a high level, the approach works as follows:
- A generative model is trained to learn a compact, sparse representation of the input image or video frames.
- This sparse representation is then encoded and transmitted, rather than the raw pixel data.
- On the decoding side, the generative model is used to reconstruct the original image or video from the compressed representation.
- Importantly, the framework includes parameters that allow users to adjust the trade-off between compression efficiency and visual fidelity, enabling NERFCodec-style flexible compression.
The authors evaluate their method on standard image and video datasets, demonstrating significant improvements in compression rates over existing techniques while maintaining high visual quality. They also show that the fidelity controls allow for space-time video super-resolution capabilities.
Critical Analysis
The paper presents a compelling approach to image and video compression that leverages the power of generative models and sparse representation. The ability to control the fidelity-efficiency trade-off is a particularly useful feature that allows users to optimize for their specific needs.
However, the authors acknowledge several limitations and areas for future work. For example, the current framework is limited to compressing individual frames or short video clips, and does not yet handle long-form video. Additionally, the generative model training can be computationally expensive, which may limit its practical application in some scenarios.
It would also be interesting to see how this method compares to other state-of-the-art compression techniques, both in terms of quantitative metrics and subjective visual quality assessments. The paper could benefit from a more thorough discussion of the potential drawbacks and challenges of the proposed approach.
Overall, this research represents an exciting step forward in the field of image and video compression, and the authors' focus on fidelity controls is a valuable contribution. Further improvements and real-world evaluations will be important to fully assess the practical impact of this work.
Conclusion
This paper introduces a novel framework for image and video compression that leverages generative sparse representation and allows for tuning the balance between compression efficiency and visual fidelity. By combining advances in generative models, sparse coding, and compression controls, the authors have developed a promising approach to improving upon traditional compression techniques.
While the current implementation has some limitations, the core ideas presented in this work have the potential to significantly impact the field of media compression, with applications ranging from mobile video streaming to medical imaging. As the authors continue to refine and expand their methods, it will be interesting to see how this research evolves and influences future developments in this important area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
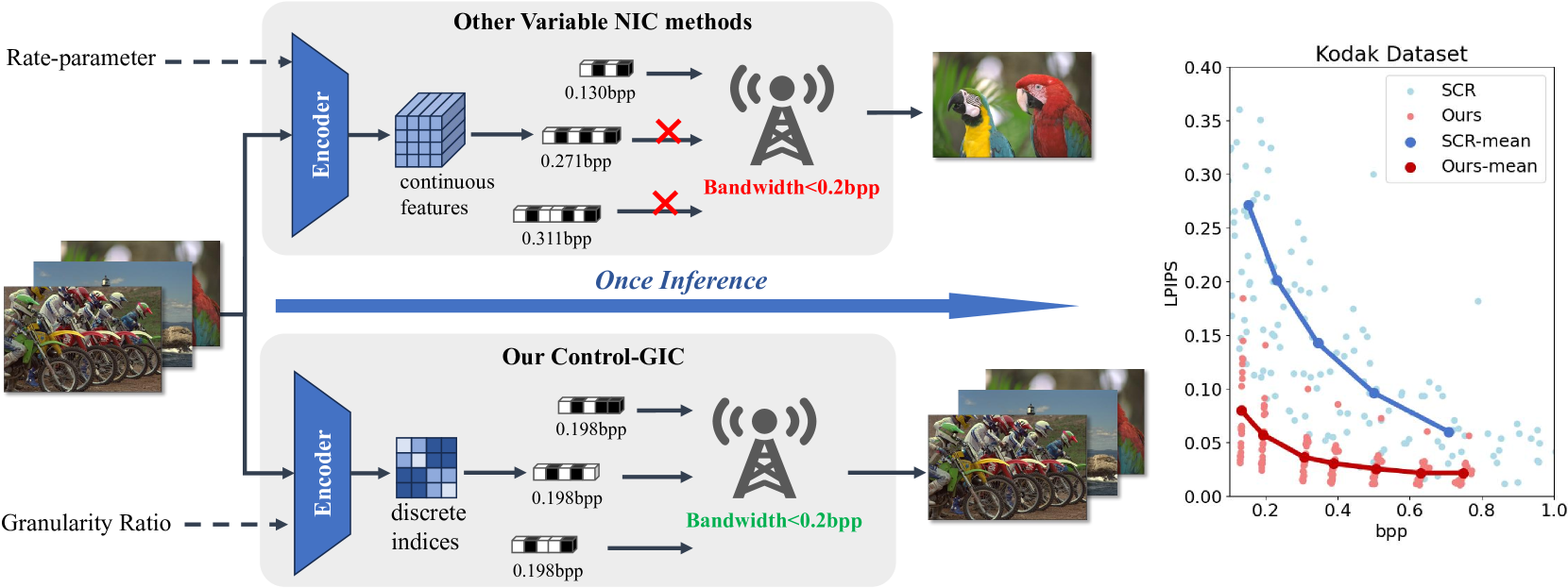
Once-for-All: Controllable Generative Image Compression with Dynamic Granularity Adaption
Anqi Li, Yuxi Liu, Huihui Bai, Feng Li, Runmin Cong, Meng Wang, Yao Zhao
0
0
Although recent generative image compression methods have demonstrated impressive potential in optimizing the rate-distortion-perception trade-off, they still face the critical challenge of flexible rate adaption to diverse compression necessities and scenarios. To overcome this challenge, this paper proposes a Controllable Generative Image Compression framework, Control-GIC, the first capable of fine-grained bitrate adaption across a broad spectrum while ensuring high-fidelity and generality compression. We base Control-GIC on a VQGAN framework representing an image as a sequence of variable-length codes (i.e. VQ-indices), which can be losslessly compressed and exhibits a direct positive correlation with the bitrates. Therefore, drawing inspiration from the classical coding principle, we naturally correlate the information density of local image patches with their granular representations, to achieve dynamic adjustment of the code quantity following different granularity decisions. This implies we can flexibly determine a proper allocation of granularity for the patches to acquire desirable compression rates. We further develop a probabilistic conditional decoder that can trace back to historic encoded multi-granularity representations according to transmitted codes, and then reconstruct hierarchical granular features in the formalization of conditional probability, enabling more informative aggregation to improve reconstruction realism. Our experiments show that Control-GIC allows highly flexible and controllable bitrate adaption and even once compression on an entire dataset to fulfill constrained bitrate conditions. Experimental results demonstrate its superior performance over recent state-of-the-art methods.
6/6/2024
Super-High-Fidelity Image Compression via Hierarchical-ROI and Adaptive Quantization
Jixiang Luo, Yan Wang, Hongwei Qin
0
0
Learned Image Compression (LIC) has achieved dramatic progress regarding objective and subjective metrics. MSE-based models aim to improve objective metrics while generative models are leveraged to improve visual quality measured by subjective metrics. However, they all suffer from blurring or deformation at low bit rates, especially at below $0.2bpp$. Besides, deformation on human faces and text is unacceptable for visual quality assessment, and the problem becomes more prominent on small faces and text. To solve this problem, we combine the advantage of MSE-based models and generative models by utilizing region of interest (ROI). We propose Hierarchical-ROI (H-ROI), to split images into several foreground regions and one background region to improve the reconstruction of regions containing faces, text, and complex textures. Further, we propose adaptive quantization by non-linear mapping within the channel dimension to constrain the bit rate while maintaining the visual quality. Exhaustive experiments demonstrate that our methods achieve better visual quality on small faces and text with lower bit rates, e.g., $0.7X$ bits of HiFiC and $0.5X$ bits of BPG.
5/24/2024
Towards Extreme Image Compression with Latent Feature Guidance and Diffusion Prior
Zhiyuan Li, Yanhui Zhou, Hao Wei, Chenyang Ge, Jingwen Jiang
0
0
Image compression at extremely low bitrates (below 0.1 bits per pixel (bpp)) is a significant challenge due to substantial information loss. In this work, we propose a novel two-stage extreme image compression framework that exploits the powerful generative capability of pre-trained diffusion models to achieve realistic image reconstruction at extremely low bitrates. In the first stage, we treat the latent representation of images in the diffusion space as guidance, employing a VAE-based compression approach to compress images and initially decode the compressed information into content variables. The second stage leverages pre-trained stable diffusion to reconstruct images under the guidance of content variables. Specifically, we introduce a small control module to inject content information while keeping the stable diffusion model fixed to maintain its generative capability. Furthermore, we design a space alignment loss to force the content variables to align with the diffusion space and provide the necessary constraints for optimization. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art approaches in terms of visual performance at extremely low bitrates.
6/14/2024

Towards Task-Compatible Compressible Representations
Anderson de Andrade, Ivan Baji'c
0
0
We identify an issue in multi-task learnable compression, in which a representation learned for one task does not positively contribute to the rate-distortion performance of a different task as much as expected, given the estimated amount of information available in it. We interpret this issue using the predictive $mathcal{V}$-information framework. In learnable scalable coding, previous work increased the utilization of side-information for input reconstruction by also rewarding input reconstruction when learning this shared representation. We evaluate the impact of this idea in the context of input reconstruction more rigorously and extended it to other computer vision tasks. We perform experiments using representations trained for object detection on COCO 2017 and depth estimation on the Cityscapes dataset, and use them to assist in image reconstruction and semantic segmentation tasks. The results show considerable improvements in the rate-distortion performance of the assisted tasks. Moreover, using the proposed representations, the performance of the base tasks are also improved. Results suggest that the proposed method induces simpler representations that are more compatible with downstream processes.
6/27/2024