Once-for-All: Controllable Generative Image Compression with Dynamic Granularity Adaption
2406.00758
0
0
Abstract
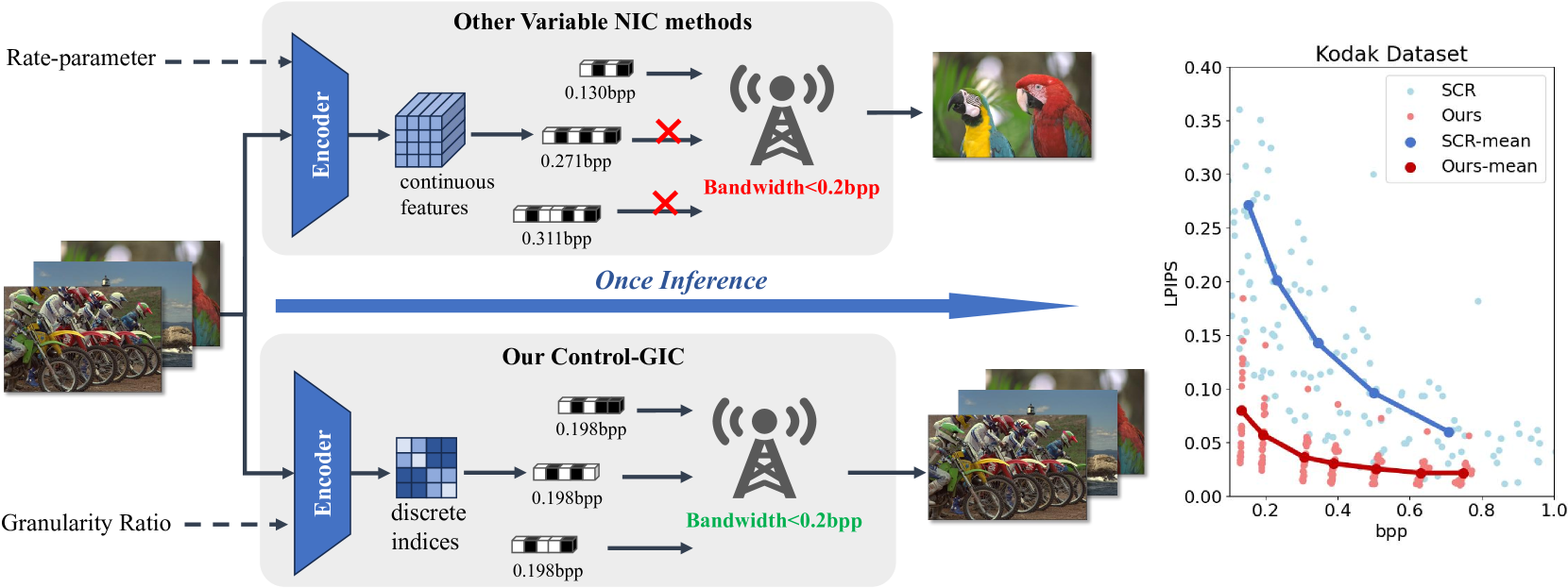
Although recent generative image compression methods have demonstrated impressive potential in optimizing the rate-distortion-perception trade-off, they still face the critical challenge of flexible rate adaption to diverse compression necessities and scenarios. To overcome this challenge, this paper proposes a Controllable Generative Image Compression framework, Control-GIC, the first capable of fine-grained bitrate adaption across a broad spectrum while ensuring high-fidelity and generality compression. We base Control-GIC on a VQGAN framework representing an image as a sequence of variable-length codes (i.e. VQ-indices), which can be losslessly compressed and exhibits a direct positive correlation with the bitrates. Therefore, drawing inspiration from the classical coding principle, we naturally correlate the information density of local image patches with their granular representations, to achieve dynamic adjustment of the code quantity following different granularity decisions. This implies we can flexibly determine a proper allocation of granularity for the patches to acquire desirable compression rates. We further develop a probabilistic conditional decoder that can trace back to historic encoded multi-granularity representations according to transmitted codes, and then reconstruct hierarchical granular features in the formalization of conditional probability, enabling more informative aggregation to improve reconstruction realism. Our experiments show that Control-GIC allows highly flexible and controllable bitrate adaption and even once compression on an entire dataset to fulfill constrained bitrate conditions. Experimental results demonstrate its superior performance over recent state-of-the-art methods.
Create account to get full access
Overview
- This paper introduces a novel generative image compression method called "Once-for-All" (OFA) that can dynamically adapt the compression granularity to the user's target bit rate.
- OFA uses a single neural network that can generate compressed images at a wide range of bit rates, without the need to train separate models for each target bit rate.
- The system allows users to control the trade-off between image quality and file size, enabling more flexibility in image compression compared to traditional methods.
Plain English Explanation
Controlling Rate-Distortion-Realism Towards Single Comprehensive and Towards Extreme Image Compression via Latent Feature Guidance are two previous works that have explored generative image compression. However, these methods require training separate models for different target bit rates, which can be time-consuming and inefficient.
The "Once-for-All" (OFA) method introduced in this paper aims to address this limitation. OFA uses a single neural network that can generate compressed images at a wide range of bit rates, without the need to train separate models. This means that users can control the balance between image quality and file size by adjusting the target bit rate, without having to retrain the model.
The key innovation in OFA is its ability to dynamically adapt the compression granularity, which determines the level of detail preserved in the compressed image. By adjusting the granularity, OFA can generate compressed images that meet the user's specific requirements in terms of file size and image quality.
This flexibility and control over the compression process can be particularly useful in applications where the required image quality and file size may vary, such as in web design, social media, or mobile applications. Users can choose the optimal balance between image quality and file size based on their specific needs, without compromising the overall image fidelity.
Technical Explanation
Image-Video Compression using Generative Sparse Representation and Super High-Fidelity Image Compression via Hierarchical Latent Representation are two examples of previous work that have explored generative approaches to image compression. These methods have demonstrated the potential of using deep learning to achieve high-quality image compression at low bit rates.
The "Once-for-All" (OFA) method introduced in this paper builds on these previous works by introducing a novel architecture and training strategy that allows for dynamic granularity adaptation. The key components of the OFA system are:
-
Granularity Adaptation Module: This module is responsible for dynamically adjusting the compression granularity based on the target bit rate. It determines the level of detail that should be preserved in the compressed image.
-
Single Generative Network: The OFA system uses a single neural network to generate compressed images across a wide range of bit rates. This is a departure from previous methods that required training separate models for each target bit rate.
-
Adaptive Coding: OFA employs an adaptive coding strategy that allocates more bits to important image regions and fewer bits to less important regions, further improving the compression efficiency.
The authors conducted extensive experiments to evaluate the performance of the OFA system, comparing it to both traditional and deep learning-based image compression methods. The results demonstrate that OFA can achieve high-quality compressed images at a wide range of bit rates, with the ability to dynamically adapt the compression granularity to meet the user's requirements.
Critical Analysis
The "Once-for-All" (OFA) method presents a promising approach to generative image compression, with several key advantages over previous methods. The ability to dynamically adapt the compression granularity and the use of a single neural network to generate compressed images across a wide range of bit rates are particularly noteworthy innovations.
However, the paper does not address several potential limitations and areas for further research. For example, the performance of OFA on diverse image datasets and real-world applications is not extensively explored. Additionally, the computational complexity and inference time of the system are not thoroughly analyzed, which could be crucial considerations for practical deployments.
Controllable Image Generation through Composed Parallel Token Prediction is a related work that explores a different approach to controllable image generation, which could potentially be integrated with the OFA framework to further enhance its flexibility and applicability.
Overall, the OFA method represents a significant advancement in generative image compression, but continued research and development will be necessary to fully realize its potential and address any remaining challenges.
Conclusion
The "Once-for-All" (OFA) method introduced in this paper offers a novel approach to generative image compression that allows for dynamic granularity adaptation. By using a single neural network to generate compressed images across a wide range of bit rates, OFA provides users with greater flexibility and control over the trade-off between image quality and file size.
The key innovations in OFA, such as the granularity adaptation module and the adaptive coding strategy, demonstrate the potential of deep learning-based approaches to improve the efficiency and versatility of image compression. As the demand for high-quality, flexible image compression continues to grow, the OFA method could have significant implications for a wide range of applications, from web design and social media to mobile apps and beyond.
While the paper presents promising results, further research and development will be necessary to fully realize the potential of the OFA system and address any remaining challenges. Integrating OFA with other emerging techniques in controllable image generation and compression could lead to even more powerful and comprehensive solutions in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Controlling Rate, Distortion, and Realism: Towards a Single Comprehensive Neural Image Compression Model
Shoma Iwai, Tomo Miyazaki, Shinichiro Omachi
0
0
In recent years, neural network-driven image compression (NIC) has gained significant attention. Some works adopt deep generative models such as GANs and diffusion models to enhance perceptual quality (realism). A critical obstacle of these generative NIC methods is that each model is optimized for a single bit rate. Consequently, multiple models are required to compress images to different bit rates, which is impractical for real-world applications. To tackle this issue, we propose a variable-rate generative NIC model. Specifically, we explore several discriminator designs tailored for the variable-rate approach and introduce a novel adversarial loss. Moreover, by incorporating the newly proposed multi-realism technique, our method allows the users to adjust the bit rate, distortion, and realism with a single model, achieving ultra-controllability. Unlike existing variable-rate generative NIC models, our method matches or surpasses the performance of state-of-the-art single-rate generative NIC models while covering a wide range of bit rates using just one model. Code will be available at https://github.com/iwa-shi/CRDR
5/28/2024

Image and Video Compression using Generative Sparse Representation with Fidelity Controls
Wei Jiang, Wei Wang
0
0
We propose a framework for learned image and video compression using the generative sparse visual representation (SVR) guided by fidelity-preserving controls. By embedding inputs into a discrete latent space spanned by learned visual codebooks, SVR-based compression transmits integer codeword indices, which is efficient and cross-platform robust. However, high-quality (HQ) reconstruction in the decoder relies on intermediate feature inputs from the encoder via direct connections. Due to the prohibitively high transmission costs, previous SVR-based compression methods remove such feature links, resulting in largely degraded reconstruction quality. In this work, we treat the intermediate features as fidelity-preserving control signals that guide the conditioned generative reconstruction in the decoder. Instead of discarding or directly transferring such signals, we draw them from a low-quality (LQ) fidelity-preserving alternative input that is sent to the decoder with very low bitrate. These control signals provide complementary fidelity cues to improve reconstruction, and their quality is determined by the compression rate of the LQ alternative, which can be tuned to trade off bitrate, fidelity and perceptual quality. Our framework can be conveniently used for both learned image compression (LIC) and learned video compression (LVC). Since SVR is robust against input perturbations, a large portion of codeword indices between adjacent frames can be the same. By only transferring different indices, SVR-based LIC and LVC can share a similar processing pipeline. Experiments over standard image and video compression benchmarks demonstrate the effectiveness of our approach.
4/10/2024
Towards Extreme Image Compression with Latent Feature Guidance and Diffusion Prior
Zhiyuan Li, Yanhui Zhou, Hao Wei, Chenyang Ge, Jingwen Jiang
0
0
Image compression at extremely low bitrates (below 0.1 bits per pixel (bpp)) is a significant challenge due to substantial information loss. In this work, we propose a novel two-stage extreme image compression framework that exploits the powerful generative capability of pre-trained diffusion models to achieve realistic image reconstruction at extremely low bitrates. In the first stage, we treat the latent representation of images in the diffusion space as guidance, employing a VAE-based compression approach to compress images and initially decode the compressed information into content variables. The second stage leverages pre-trained stable diffusion to reconstruct images under the guidance of content variables. Specifically, we introduce a small control module to inject content information while keeping the stable diffusion model fixed to maintain its generative capability. Furthermore, we design a space alignment loss to force the content variables to align with the diffusion space and provide the necessary constraints for optimization. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art approaches in terms of visual performance at extremely low bitrates.
6/14/2024
🖼️
Controllable Image Generation With Composed Parallel Token Prediction
Jamie Stirling, Noura Al-Moubayed
0
0
Compositional image generation requires models to generalise well in situations where two or more input concepts do not necessarily appear together in training (compositional generalisation). Despite recent progress in compositional image generation via composing continuous sampling processes such as diffusion and energy-based models, composing discrete generative processes has remained an open challenge, with the promise of providing improvements in efficiency, interpretability and simplicity. To this end, we propose a formulation for controllable conditional generation of images via composing the log-probability outputs of discrete generative models of the latent space. Our approach, when applied alongside VQ-VAE and VQ-GAN, achieves state-of-the-art generation accuracy in three distinct settings (FFHQ, Positional CLEVR and Relational CLEVR) while attaining competitive Fr'echet Inception Distance (FID) scores. Our method attains an average generation accuracy of $80.71%$ across the studied settings. Our method also outperforms the next-best approach (ranked by accuracy) in terms of FID in seven out of nine experiments, with an average FID of $24.23$ (an average improvement of $-9.58$). Furthermore, our method offers a $2.3times$ to $12times$ speedup over comparable continuous compositional methods on our hardware. We find that our method can generalise to combinations of input conditions that lie outside the training data (e.g. more objects per image) in addition to offering an interpretable dimension of controllability via concept weighting. We further demonstrate that our approach can be readily applied to an open pre-trained discrete text-to-image model without any fine-tuning, allowing for fine-grained control of text-to-image generation.
5/13/2024