A Superalignment Framework in Autonomous Driving with Large Language Models
2406.05651
0
0
Abstract
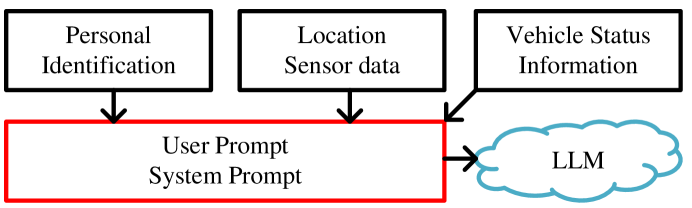
Over the last year, significant advancements have been made in the realms of large language models (LLMs) and multi-modal large language models (MLLMs), particularly in their application to autonomous driving. These models have showcased remarkable abilities in processing and interacting with complex information. In autonomous driving, LLMs and MLLMs are extensively used, requiring access to sensitive vehicle data such as precise locations, images, and road conditions. These data are transmitted to an LLM-based inference cloud for advanced analysis. However, concerns arise regarding data security, as the protection against data and privacy breaches primarily depends on the LLM's inherent security measures, without additional scrutiny or evaluation of the LLM's inference outputs. Despite its importance, the security aspect of LLMs in autonomous driving remains underexplored. Addressing this gap, our research introduces a novel security framework for autonomous vehicles, utilizing a multi-agent LLM approach. This framework is designed to safeguard sensitive information associated with autonomous vehicles from potential leaks, while also ensuring that LLM outputs adhere to driving regulations and align with human values. It includes mechanisms to filter out irrelevant queries and verify the safety and reliability of LLM outputs. Utilizing this framework, we evaluated the security, privacy, and cost aspects of eleven large language model-driven autonomous driving cues. Additionally, we performed QA tests on these driving prompts, which successfully demonstrated the framework's efficacy.
Create account to get full access
Overview
- This paper proposes a "superalignment" framework to improve the safety and performance of autonomous driving systems using large language models (LLMs).
- The authors argue that existing approaches to aligning autonomous agents with human values and preferences are insufficient, and that a more comprehensive framework is needed.
- The proposed framework aims to align the agent's behavior with human preferences across a wide range of situations, not just specific tasks.
Plain English Explanation
The paper presents a new way to make self-driving cars and other autonomous systems better aligned with human values and preferences. Existing approaches often focus on specific tasks, but the researchers believe a more comprehensive "superalignment" framework is needed.
The key idea is to use large language models (LLMs) - powerful AI systems trained on vast amounts of text data - to imbue autonomous agents with a deeper understanding of human preferences and values. This goes beyond just optimizing for specific objectives, and instead tries to ensure the agent behaves in a way that is truly aligned with what humans want, across a wide range of situations.
For example, a self-driving car equipped with this framework wouldn't just try to reach the destination quickly and efficiently. It would also consider other factors like safety, passenger comfort, and environmental impact - and make decisions that balance all of these priorities in a way that aligns with human values. [Link to <a href="https://aimodels.fyi/papers/arxiv/personalized-autonomous-driving-large-language-models-field">personalized autonomous driving with LLMs</a>]
The researchers believe this kind of broad, value-aligned autonomy is crucial as AI systems become more capable and influential in our lives. By deeply embedding human preferences into the core decision-making of these systems, we can work towards AI that truly serves and benefits humanity. [Link to <a href="https://aimodels.fyi/papers/arxiv/probing-multimodal-llms-as-world-models-driving">probing multimodal LLMs as world models for driving</a>]
Technical Explanation
The paper introduces a "superalignment" framework that aims to align autonomous agents, such as self-driving cars, with human preferences and values across a wide range of situations. This extends beyond traditional approaches that focus on optimizing for specific objectives.
At the core of the framework is the use of large language models (LLMs) - powerful AI systems trained on vast amounts of text data. The researchers propose using LLMs to imbue autonomous agents with a deeper understanding of human preferences, ethics, and values. This allows the agents to make decisions that balance multiple priorities, such as safety, comfort, and environmental impact, in a way that aligns with human values. [Link to <a href="https://aimodels.fyi/papers/arxiv/prompting-multi-modal-tokens-to-enhance-end">prompting multimodal tokens to enhance end-to-end learning</a>]
The framework consists of several key components:
- Value Modeling: Using LLMs to build a rich, nuanced model of human values and preferences.
- Preference Learning: Continuously updating the agent's understanding of human preferences through interaction and feedback.
- Constrained Optimization: Ensuring the agent's actions optimize for multiple, potentially conflicting objectives in a way that respects human values.
- Ethical Reasoning: Enabling the agent to reason about the ethical implications of its decisions and act accordingly.
The authors demonstrate the effectiveness of this approach through simulations and real-world experiments, showcasing improved safety, efficiency, and user satisfaction compared to traditional autonomous driving systems. [Link to <a href="https://aimodels.fyi/papers/arxiv/survey-large-language-model-based-autonomous-agents">survey of LLM-based autonomous agents</a>]
Critical Analysis
The proposed superalignment framework represents a significant advancement in the field of autonomous systems, particularly in the context of autonomous driving. By leveraging the power of large language models, the framework aims to imbue autonomous agents with a deeper understanding of human preferences and values, going beyond narrow optimization for specific objectives.
One key strength of the approach is its emphasis on ethical reasoning and the consideration of multiple, potentially conflicting priorities. This aligns with the growing recognition that autonomous systems need to be designed with a strong ethical foundation to ensure they serve humanity's best interests. [Link to <a href="https://aimodels.fyi/papers/arxiv/exploring-autonomous-agents-through-lens-large-language">exploring autonomous agents through the lens of LLMs</a>]
However, the framework also faces some potential challenges and limitations. Accurately modeling and representing the rich tapestry of human values and preferences is an inherently complex and subjective task, and the reliability and consistency of the LLM-based value modeling approach remains an open question. Additionally, the framework's ability to handle edge cases and unexpected situations may require further exploration and refinement.
It will also be important to consider the potential societal implications of such a powerful alignment framework, and to ensure that it is developed and deployed in a responsible and equitable manner, with appropriate safeguards and oversight.
Conclusion
The "superalignment" framework proposed in this paper represents a significant step forward in the quest to create autonomous systems that are truly aligned with human values and preferences. By leveraging the power of large language models, the framework aims to imbue autonomous agents, such as self-driving cars, with a deeper understanding of human ethics and priorities, enabling them to make decisions that balance multiple, potentially conflicting objectives in a way that serves humanity's best interests.
As AI systems become increasingly capable and influential in our lives, the development of robust, value-aligned autonomy frameworks like this one will be crucial. By embedding human preferences and values into the core decision-making of these systems, we can work towards a future where AI truly enhances and empowers human flourishing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Personalized Autonomous Driving with Large Language Models: Field Experiments
Can Cui, Zichong Yang, Yupeng Zhou, Yunsheng Ma, Juanwu Lu, Lingxi Li, Yaobin Chen, Jitesh Panchal, Ziran Wang
0
0
Integrating large language models (LLMs) in autonomous vehicles enables conversation with AI systems to drive the vehicle. However, it also emphasizes the requirement for such systems to comprehend commands accurately and achieve higher-level personalization to adapt to the preferences of drivers or passengers over a more extended period. In this paper, we introduce an LLM-based framework, Talk2Drive, capable of translating natural verbal commands into executable controls and learning to satisfy personal preferences for safety, efficiency, and comfort with a proposed memory module. This is the first-of-its-kind multi-scenario field experiment that deploys LLMs on a real-world autonomous vehicle. Experiments showcase that the proposed system can comprehend human intentions at different intuition levels, ranging from direct commands like can you drive faster to indirect commands like I am really in a hurry now. Additionally, we use the takeover rate to quantify the trust of human drivers in the LLM-based autonomous driving system, where Talk2Drive significantly reduces the takeover rate in highway, intersection, and parking scenarios. We also validate that the proposed memory module considers personalized preferences and further reduces the takeover rate by up to 65.2% compared with those without a memory module. The experiment video can be watched at https://www.youtube.com/watch?v=4BWsfPaq1Ro
5/9/2024
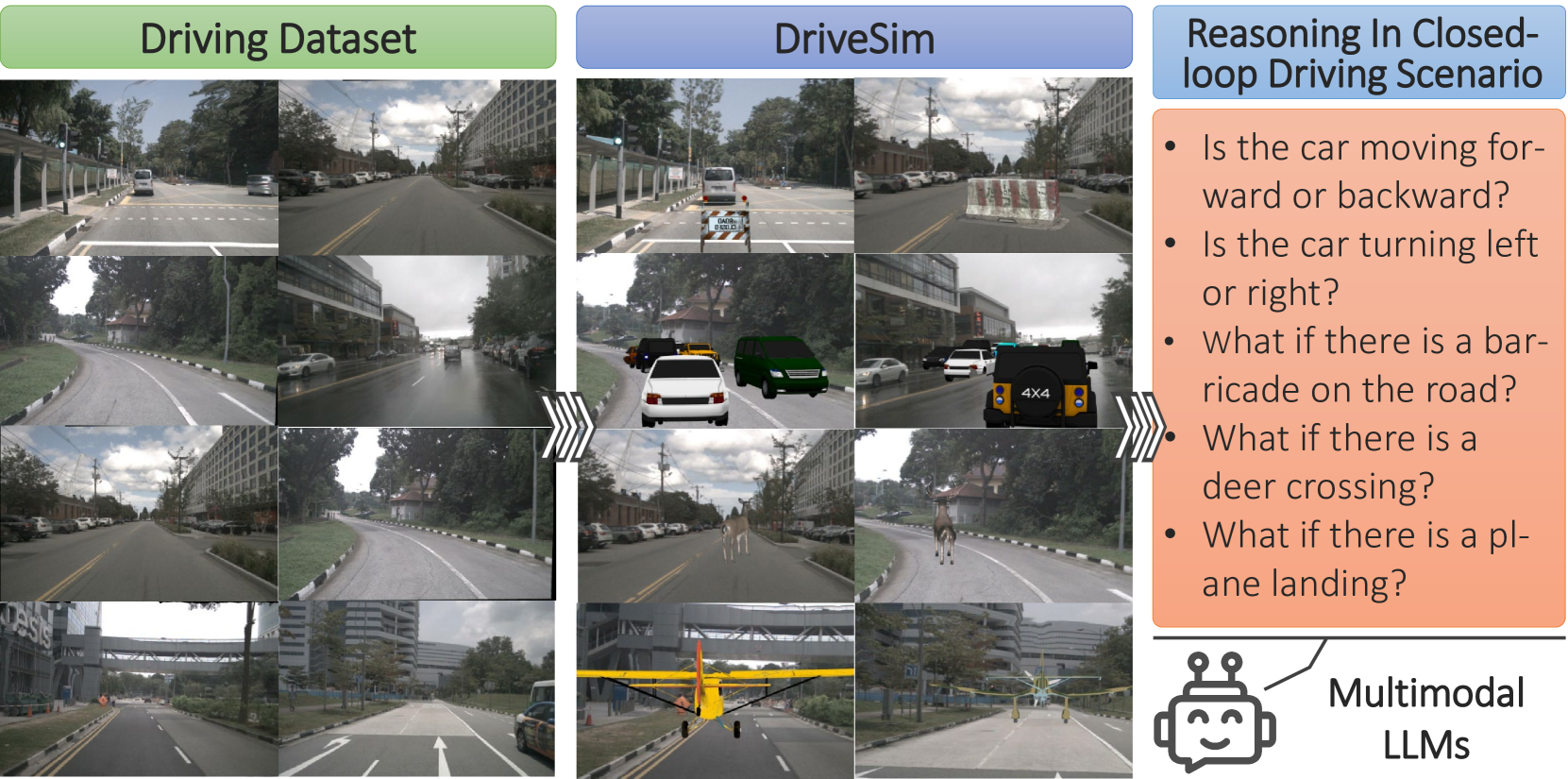
Probing Multimodal LLMs as World Models for Driving
Shiva Sreeram, Tsun-Hsuan Wang, Alaa Maalouf, Guy Rosman, Sertac Karaman, Daniela Rus
0
0
We provide a sober look at the application of Multimodal Large Language Models (MLLMs) within the domain of autonomous driving and challenge/verify some common assumptions, focusing on their ability to reason and interpret dynamic driving scenarios through sequences of images/frames in a closed-loop control environment. Despite the significant advancements in MLLMs like GPT-4V, their performance in complex, dynamic driving environments remains largely untested and presents a wide area of exploration. We conduct a comprehensive experimental study to evaluate the capability of various MLLMs as world models for driving from the perspective of a fixed in-car camera. Our findings reveal that, while these models proficiently interpret individual images, they struggle significantly with synthesizing coherent narratives or logical sequences across frames depicting dynamic behavior. The experiments demonstrate considerable inaccuracies in predicting (i) basic vehicle dynamics (forward/backward, acceleration/deceleration, turning right or left), (ii) interactions with other road actors (e.g., identifying speeding cars or heavy traffic), (iii) trajectory planning, and (iv) open-set dynamic scene reasoning, suggesting biases in the models' training data. To enable this experimental study we introduce a specialized simulator, DriveSim, designed to generate diverse driving scenarios, providing a platform for evaluating MLLMs in the realms of driving. Additionally, we contribute the full open-source code and a new dataset, Eval-LLM-Drive, for evaluating MLLMs in driving. Our results highlight a critical gap in the current capabilities of state-of-the-art MLLMs, underscoring the need for enhanced foundation models to improve their applicability in real-world dynamic environments.
5/10/2024
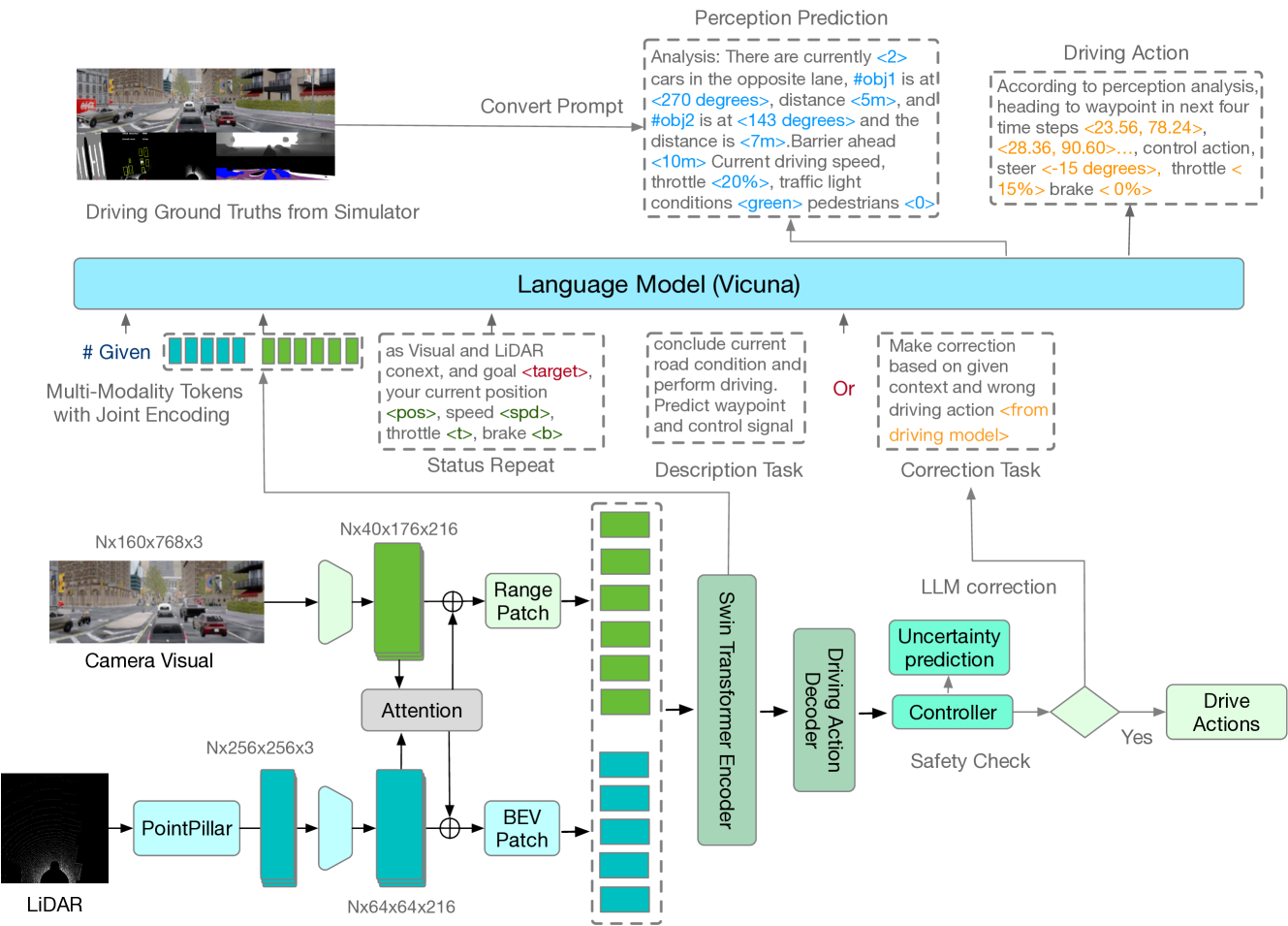
Prompting Multi-Modal Tokens to Enhance End-to-End Autonomous Driving Imitation Learning with LLMs
Yiqun Duan, Qiang Zhang, Renjing Xu
0
0
The utilization of Large Language Models (LLMs) within the realm of reinforcement learning, particularly as planners, has garnered a significant degree of attention in recent scholarly literature. However, a substantial proportion of existing research predominantly focuses on planning models for robotics that transmute the outputs derived from perception models into linguistic forms, thus adopting a `pure-language' strategy. In this research, we propose a hybrid End-to-End learning framework for autonomous driving by combining basic driving imitation learning with LLMs based on multi-modality prompt tokens. Instead of simply converting perception results from the separated train model into pure language input, our novelty lies in two aspects. 1) The end-to-end integration of visual and LiDAR sensory input into learnable multi-modality tokens, thereby intrinsically alleviating description bias by separated pre-trained perception models. 2) Instead of directly letting LLMs drive, this paper explores a hybrid setting of letting LLMs help the driving model correct mistakes and complicated scenarios. The results of our experiments suggest that the proposed methodology can attain driving scores of 49.21%, coupled with an impressive route completion rate of 91.34% in the offline evaluation conducted via CARLA. These performance metrics are comparable to the most advanced driving models.
4/9/2024
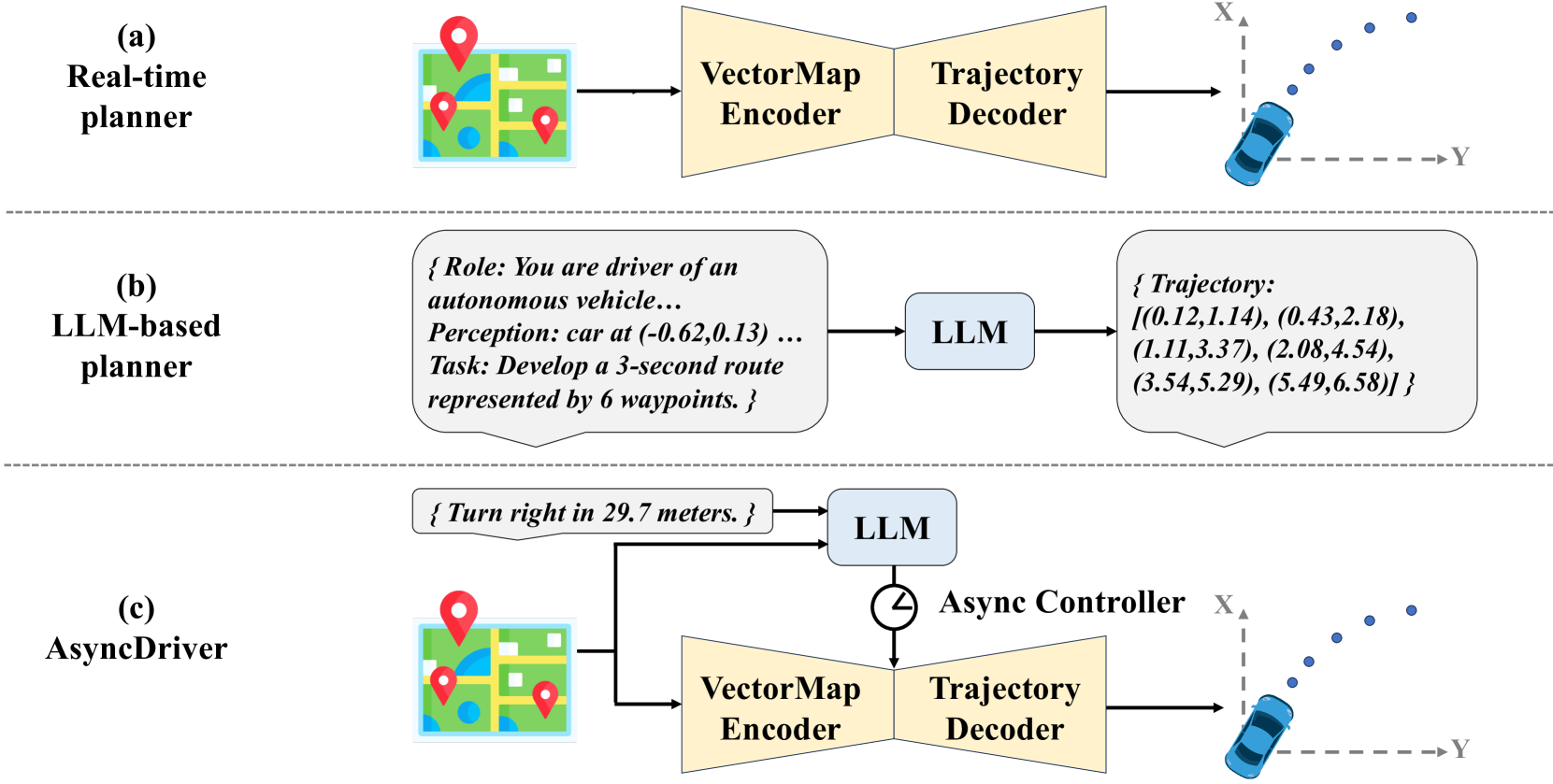
Asynchronous Large Language Model Enhanced Planner for Autonomous Driving
Yuan Chen, Zi-han Ding, Ziqin Wang, Yan Wang, Lijun Zhang, Si Liu
0
0
Despite real-time planners exhibiting remarkable performance in autonomous driving, the growing exploration of Large Language Models (LLMs) has opened avenues for enhancing the interpretability and controllability of motion planning. Nevertheless, LLM-based planners continue to encounter significant challenges, including elevated resource consumption and extended inference times, which pose substantial obstacles to practical deployment. In light of these challenges, we introduce AsyncDriver, a new asynchronous LLM-enhanced closed-loop framework designed to leverage scene-associated instruction features produced by LLM to guide real-time planners in making precise and controllable trajectory predictions. On one hand, our method highlights the prowess of LLMs in comprehending and reasoning with vectorized scene data and a series of routing instructions, demonstrating its effective assistance to real-time planners. On the other hand, the proposed framework decouples the inference processes of the LLM and real-time planners. By capitalizing on the asynchronous nature of their inference frequencies, our approach have successfully reduced the computational cost introduced by LLM, while maintaining comparable performance. Experiments show that our approach achieves superior closed-loop evaluation performance on nuPlan's challenging scenarios.
6/24/2024