Supervised Fine-tuning in turn Improves Visual Foundation Models
2401.10222
0
1

Abstract
Image-text training like CLIP has dominated the pretraining of vision foundation models in recent years. Subsequent efforts have been made to introduce region-level visual learning into CLIP's pretraining but face scalability challenges due to the lack of large-scale region-level datasets. Drawing inspiration from supervised fine-tuning (SFT) in natural language processing such as instruction tuning, we explore the potential of fine-grained SFT in enhancing the generation of vision foundation models after their pretraining. Thus a two-stage method ViSFT (Vision SFT) is proposed to unleash the fine-grained knowledge of vision foundation models. In ViSFT, the vision foundation model is enhanced by performing visual joint learning on some in-domain tasks and then tested on out-of-domain benchmarks. With updating using ViSFT on 8 V100 GPUs in less than 2 days, a vision transformer with over 4.4B parameters shows improvements across various out-of-domain benchmarks including vision and vision-linguistic scenarios.
Create account to get full access
Overview
- This paper investigates how supervised fine-tuning can improve the performance of visual foundation models.
- The researchers explore different fine-tuning approaches and analyze their impact on a range of computer vision tasks.
- Their findings suggest that carefully designed fine-tuning strategies can significantly boost the capabilities of large pre-trained vision models.
Plain English Explanation
In the world of artificial intelligence (AI), foundation models are powerful machine learning systems that have been trained on vast amounts of data to develop a broad understanding of a domain, such as computer vision or natural language processing. These foundation models can then be fine-tuned - or further trained - on specific tasks or datasets to achieve high performance.
This paper examines how supervised fine-tuning, where the model is trained on labeled data, can be used to enhance the capabilities of visual foundation models. The researchers explore different fine-tuning approaches and evaluate their impact on a variety of computer vision tasks, such as image classification, object detection, and image segmentation.
Their findings suggest that carefully designed fine-tuning strategies can significantly boost the performance of large pre-trained vision models. By leveraging supervised fine-tuning, the researchers were able to improve the models' understanding and handling of specific visual tasks, making them more effective and reliable for real-world applications.
Technical Explanation
The researchers in this paper investigated the impact of supervised fine-tuning on the performance of visual foundation models. They experimented with different fine-tuning approaches, including task-specific fine-tuning and multi-task fine-tuning, and evaluated the models' performance on a range of computer vision tasks.
The key insights from their study include:
- Carefully designed fine-tuning strategies can significantly improve the capabilities of large pre-trained vision models.
- Multi-task fine-tuning, where the model is trained on multiple related tasks simultaneously, can lead to better generalization and higher overall performance.
- The benefits of fine-tuning are more pronounced for tasks that are more distinct from the pre-training data, suggesting that fine-tuning can help bridge the gap between foundation models and specific applications.
Critical Analysis
The paper provides a thorough investigation of the impact of supervised fine-tuning on visual foundation models, and the results are compelling. However, a few potential limitations and areas for further research should be considered:
-
The paper focuses primarily on standard computer vision tasks, such as image classification and object detection. It would be interesting to see how these fine-tuning approaches perform on more complex or emerging visual tasks, such as multimodal understanding or 3D perception.
-
The experiments were conducted on a limited set of foundation models and datasets. Expanding the research to a broader range of models and real-world datasets could provide additional insights and validate the generalizability of the findings.
-
The paper does not explore the computational and resource requirements of the fine-tuning process. Understanding the trade-offs between performance gains and the computational cost of fine-tuning could inform practical deployment considerations.
Overall, this paper provides valuable insights into the potential of supervised fine-tuning to enhance the capabilities of visual foundation models. The findings highlight the importance of carefully designing fine-tuning strategies to unlock the full potential of these powerful AI systems.
Conclusion
This research paper demonstrates that supervised fine-tuning can significantly improve the performance of visual foundation models across a range of computer vision tasks. By exploring different fine-tuning approaches, the researchers were able to show how carefully designed strategies can bridge the gap between pre-trained models and specific applications.
The findings from this study have important implications for the development and deployment of AI systems in real-world settings. As foundation models continue to play a central role in computer vision and other domains, the ability to fine-tune them effectively will be crucial for unlocking their full potential and ensuring they can be reliably applied to a wide variety of tasks and scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Injecting New Knowledge into Large Language Models via Supervised Fine-Tuning
Nick Mecklenburg, Yiyou Lin, Xiaoxiao Li, Daniel Holstein, Leonardo Nunes, Sara Malvar, Bruno Silva, Ranveer Chandra, Vijay Aski, Pavan Kumar Reddy Yannam, Tolga Aktas, Todd Hendry
0
0
In recent years, Large Language Models (LLMs) have shown remarkable performance in generating human-like text, proving to be a valuable asset across various applications. However, adapting these models to incorporate new, out-of-domain knowledge remains a challenge, particularly for facts and events that occur after the model's knowledge cutoff date. This paper investigates the effectiveness of Supervised Fine-Tuning (SFT) as a method for knowledge injection in LLMs, specifically focusing on the domain of recent sporting events. We compare different dataset generation strategies -- token-based and fact-based scaling -- to create training data that helps the model learn new information. Our experiments on GPT-4 demonstrate that while token-based scaling can lead to improvements in Q&A accuracy, it may not provide uniform coverage of new knowledge. Fact-based scaling, on the other hand, offers a more systematic approach to ensure even coverage across all facts. We present a novel dataset generation process that leads to more effective knowledge ingestion through SFT, and our results show considerable performance improvements in Q&A tasks related to out-of-domain knowledge. This study contributes to the understanding of domain adaptation for LLMs and highlights the potential of SFT in enhancing the factuality of LLM responses in specific knowledge domains.
4/4/2024
👀
Sparse-Tuning: Adapting Vision Transformers with Efficient Fine-tuning and Inference
Ting Liu, Xuyang Liu, Liangtao Shi, Zunnan Xu, Siteng Huang, Yi Xin, Quanjun Yin
0
0
Parameter-efficient fine-tuning (PEFT) has emerged as a popular approach for adapting pre-trained Vision Transformer (ViT) models to downstream applications. While current PEFT methods achieve parameter efficiency, they overlook GPU memory and time efficiency during both fine-tuning and inference, due to the repeated computation of redundant tokens in the ViT architecture. This falls short of practical requirements for downstream task adaptation. In this paper, we propose textbf{Sparse-Tuning}, a novel tuning paradigm that substantially enhances both fine-tuning and inference efficiency for pre-trained ViT models. Sparse-Tuning efficiently fine-tunes the pre-trained ViT by sparsely preserving the informative tokens and merging redundant ones, enabling the ViT to focus on the foreground while reducing computational costs on background regions in the images. To accurately distinguish informative tokens from uninformative ones, we introduce a tailored Dense Adapter, which establishes dense connections across different encoder layers in the ViT, thereby enhancing the representational capacity and quality of token sparsification. Empirical results on VTAB-1K, three complete image datasets, and two complete video datasets demonstrate that Sparse-Tuning reduces the GFLOPs to textbf{62%-70%} of the original ViT-B while achieving state-of-the-art performance. Source code is available at url{https://github.com/liuting20/Sparse-Tuning}.
5/24/2024
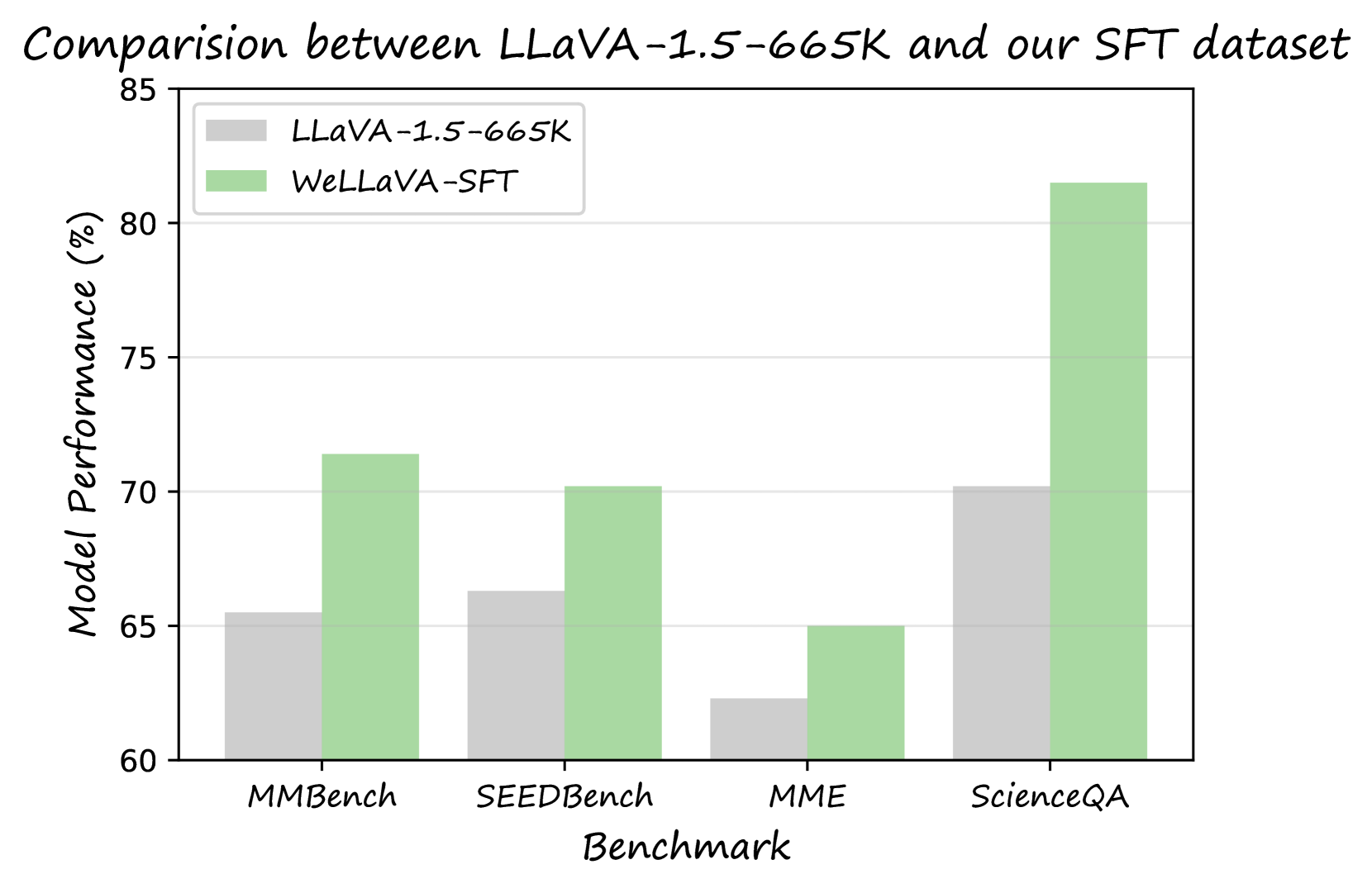
Rethinking Overlooked Aspects in Vision-Language Models
Yuan Liu, Le Tian, Xiao Zhou, Jie Zhou
0
0
Recent advancements in large vision-language models (LVLMs), such as GPT4-V and LLaVA, have been substantial. LLaVA's modular architecture, in particular, offers a blend of simplicity and efficiency. Recent works mainly focus on introducing more pre-training and instruction tuning data to improve model's performance. This paper delves into the often-neglected aspects of data efficiency during pre-training and the selection process for instruction tuning datasets. Our research indicates that merely increasing the size of pre-training data does not guarantee improved performance and may, in fact, lead to its degradation. Furthermore, we have established a pipeline to pinpoint the most efficient instruction tuning (SFT) dataset, implying that not all SFT data utilized in existing studies are necessary. The primary objective of this paper is not to introduce a state-of-the-art model, but rather to serve as a roadmap for future research, aiming to optimize data usage during pre-training and fine-tuning processes to enhance the performance of vision-language models.
5/21/2024
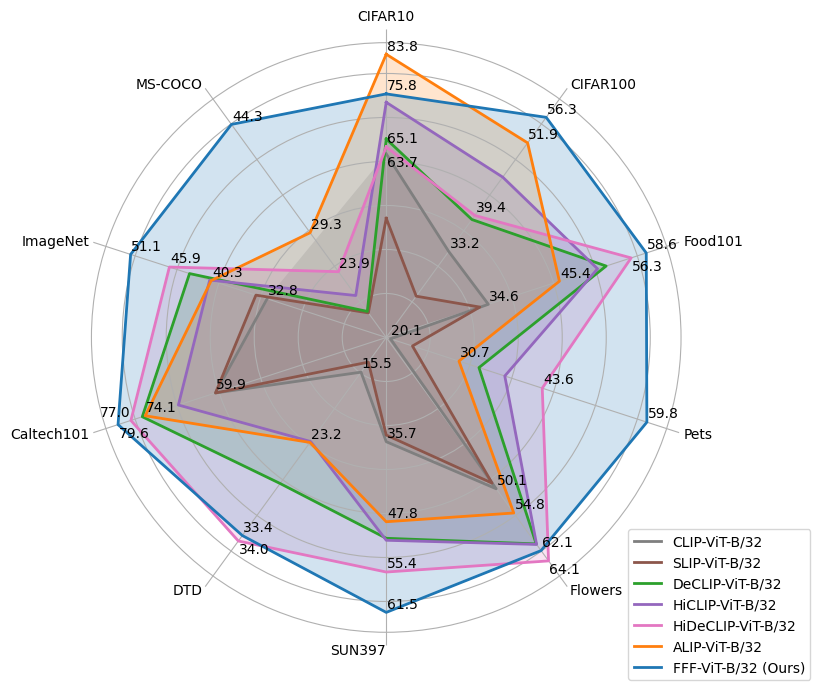
FFF: Fixing Flawed Foundations in contrastive pre-training results in very strong Vision-Language models
Adrian Bulat, Yassine Ouali, Georgios Tzimiropoulos
0
0
Despite noise and caption quality having been acknowledged as important factors impacting vision-language contrastive pre-training, in this paper, we show that the full potential of improving the training process by addressing such issues is yet to be realized. Specifically, we firstly study and analyze two issues affecting training: incorrect assignment of negative pairs, and low caption quality and diversity. Then, we devise effective solutions for addressing both problems, which essentially require training with multiple true positive pairs. Finally, we propose training with sigmoid loss to address such a requirement. We show very large gains over the current state-of-the-art for both image recognition ($sim +6%$ on average over 11 datasets) and image retrieval ($sim +19%$ on Flickr30k and $sim +15%$ on MSCOCO).
5/17/2024