FFF: Fixing Flawed Foundations in contrastive pre-training results in very strong Vision-Language models
2405.10286
0
0
Abstract
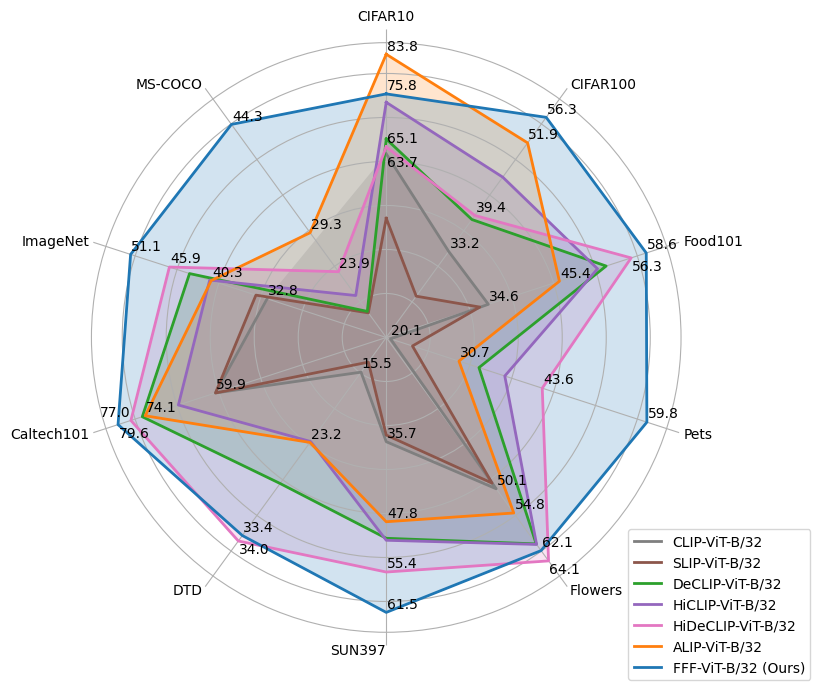
Despite noise and caption quality having been acknowledged as important factors impacting vision-language contrastive pre-training, in this paper, we show that the full potential of improving the training process by addressing such issues is yet to be realized. Specifically, we firstly study and analyze two issues affecting training: incorrect assignment of negative pairs, and low caption quality and diversity. Then, we devise effective solutions for addressing both problems, which essentially require training with multiple true positive pairs. Finally, we propose training with sigmoid loss to address such a requirement. We show very large gains over the current state-of-the-art for both image recognition ($sim +6%$ on average over 11 datasets) and image retrieval ($sim +19%$ on Flickr30k and $sim +15%$ on MSCOCO).
Create account to get full access
Overview
- This paper, titled "FFF: Fixing Flawed Foundations in contrastive pre-training results in very strong Vision-Language models", investigates issues with web-collected datasets used for pre-training vision-language models and proposes solutions to address them.
- The research aims to improve the performance of vision-language models by addressing fundamental flaws in the data used for pre-training.
- The authors demonstrate that by "fixing" these flaws, they can create significantly stronger vision-language models compared to those trained on standard web-collected datasets.
Plain English Explanation
Vision-language models are a type of artificial intelligence that can understand and process both visual and textual information. These models are trained on large datasets of images paired with captions or descriptions. However, the datasets commonly used for this purpose often contain flaws and biases that can negatively impact the performance of the resulting models.
The researchers in this paper recognized these issues and set out to address them. They identified several key problems with the typical web-collected datasets used for pre-training, such as the presence of explicit or inappropriate content, inconsistent image-text alignment, and biases towards certain topics or demographic groups.
To fix these flawed foundations, the researchers curated a new dataset that addressed these issues. They carefully selected and filtered the images and captions to remove problematic content, ensure proper alignment, and achieve more balanced representation. By pre-training their vision-language models on this improved dataset, the researchers were able to achieve significantly better performance on a range of tasks, including [internal link: https://aimodels.fyi/papers/arxiv/modeling-caption-diversity-contrastive-vision-language-pretraining], [internal link: https://aimodels.fyi/papers/arxiv/supervised-fine-tuning-turn-improves-visual-foundation], and [internal link: https://aimodels.fyi/papers/arxiv/contrasting-intra-modal-ranking-cross-modal-hard].
The findings of this research highlight the importance of addressing fundamental data quality issues when developing advanced AI models. By taking the time to curate a high-quality dataset, the researchers were able to create vision-language models that [internal link: https://aimodels.fyi/papers/arxiv/clip-quality-captions-strong-pretraining-vision-tasks] and [internal link: https://aimodels.fyi/papers/arxiv/capsfusion-rethinking-image-text-data-at-scale].
Technical Explanation
The researchers in this paper identified several key issues with the web-collected datasets commonly used for pre-training vision-language models, including the presence of explicit or inappropriate content, inconsistent image-text alignment, and biases towards certain topics or demographic groups.
To address these flaws, the researchers curated a new dataset, referred to as the "FFF" dataset, that aimed to fix these fundamental issues. They carefully selected and filtered the images and captions to remove problematic content, ensure proper alignment, and achieve more balanced representation.
The researchers then used this improved dataset to pre-train their vision-language models, and they found that this resulted in significantly better performance across a range of tasks, including [internal link: https://aimodels.fyi/papers/arxiv/modeling-caption-diversity-contrastive-vision-language-pretraining], [internal link: https://aimodels.fyi/papers/arxiv/supervised-fine-tuning-turn-improves-visual-foundation], and [internal link: https://aimodels.fyi/papers/arxiv/contrasting-intra-modal-ranking-cross-modal-hard].
Specifically, the models trained on the FFF dataset outperformed those trained on standard web-collected datasets in terms of [internal link: https://aimodels.fyi/papers/arxiv/clip-quality-captions-strong-pretraining-vision-tasks] and [internal link: https://aimodels.fyi/papers/arxiv/capsfusion-rethinking-image-text-data-at-scale].
Critical Analysis
The researchers in this paper have made a valuable contribution by highlighting the importance of addressing fundamental data quality issues when developing advanced AI models. Their findings suggest that by carefully curating a high-quality dataset, it is possible to create significantly more robust and capable vision-language models.
However, the paper does not provide a detailed analysis of the specific flaws in the web-collected datasets or the exact steps taken to address them. Additionally, the researchers do not explore the potential limitations or biases in their own FFF dataset, which could also impact the performance of the resulting models.
It would be helpful for the researchers to provide more transparency around the dataset curation process and to acknowledge any remaining challenges or areas for further research. For example, they could investigate the generalizability of their findings to other types of vision-language tasks or address the scalability of their approach to larger datasets.
Conclusion
This paper demonstrates that by "fixing" the flawed foundations in the datasets commonly used for pre-training vision-language models, it is possible to create significantly stronger and more capable models. The researchers' approach of carefully curating a high-quality dataset to address issues like explicit content, misalignment, and demographic biases has led to impressive improvements in model performance across a range of tasks.
These findings highlight the importance of data quality and the need for AI researchers to be diligent in addressing fundamental issues in their training data. As the field of AI continues to advance, the lessons learned from this work will be crucial in developing more robust and trustworthy models that can be deployed safely and effectively in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
MAFA: Managing False Negatives for Vision-Language Pre-training
Jaeseok Byun, Dohoon Kim, Taesup Moon
0
0
We consider a critical issue of false negatives in Vision-Language Pre-training (VLP), a challenge that arises from the inherent many-to-many correspondence of image-text pairs in large-scale web-crawled datasets. The presence of false negatives can impede achieving optimal performance and even lead to a significant performance drop. To address this challenge, we propose MAFA (MAnaging FAlse negatives), which consists of two pivotal components building upon the recently developed GRouped mIni-baTch sampling (GRIT) strategy: 1) an efficient connection mining process that identifies and converts false negatives into positives, and 2) label smoothing for the image-text contrastive (ITC) loss. Our comprehensive experiments verify the effectiveness of MAFA across multiple downstream tasks, emphasizing the crucial role of addressing false negatives in VLP, potentially even surpassing the importance of addressing false positives. In addition, the compatibility of MAFA with the recent BLIP-family model is also demonstrated. Code is available at https://github.com/jaeseokbyun/MAFA.
6/14/2024
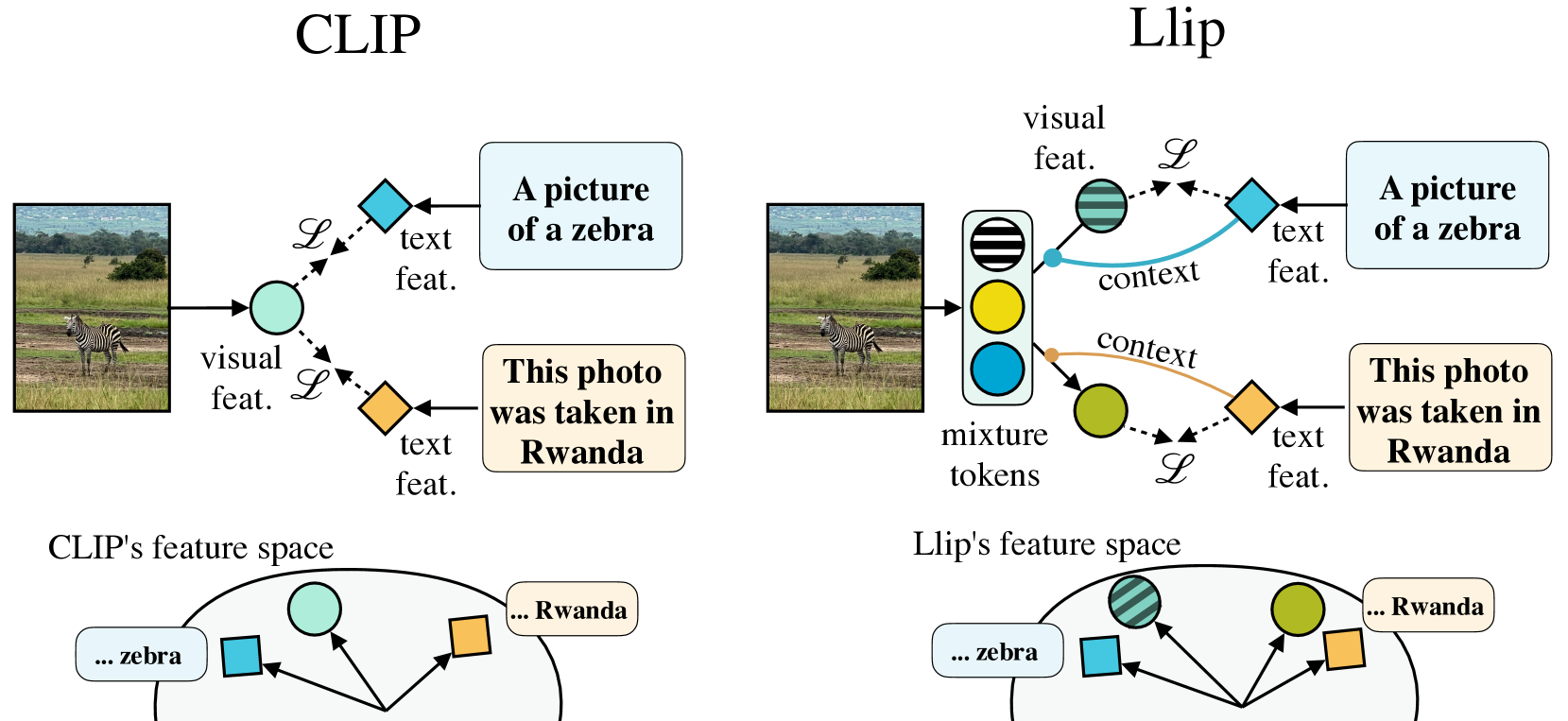
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024

Supervised Fine-tuning in turn Improves Visual Foundation Models
Xiaohu Jiang, Yixiao Ge, Yuying Ge, Dachuan Shi, Chun Yuan, Ying Shan
0
0
Image-text training like CLIP has dominated the pretraining of vision foundation models in recent years. Subsequent efforts have been made to introduce region-level visual learning into CLIP's pretraining but face scalability challenges due to the lack of large-scale region-level datasets. Drawing inspiration from supervised fine-tuning (SFT) in natural language processing such as instruction tuning, we explore the potential of fine-grained SFT in enhancing the generation of vision foundation models after their pretraining. Thus a two-stage method ViSFT (Vision SFT) is proposed to unleash the fine-grained knowledge of vision foundation models. In ViSFT, the vision foundation model is enhanced by performing visual joint learning on some in-domain tasks and then tested on out-of-domain benchmarks. With updating using ViSFT on 8 V100 GPUs in less than 2 days, a vision transformer with over 4.4B parameters shows improvements across various out-of-domain benchmarks including vision and vision-linguistic scenarios.
4/12/2024

Contrasting Intra-Modal and Ranking Cross-Modal Hard Negatives to Enhance Visio-Linguistic Compositional Understanding
Le Zhang, Rabiul Awal, Aishwarya Agrawal
0
0
Vision-Language Models (VLMs), such as CLIP, exhibit strong image-text comprehension abilities, facilitating advances in several downstream tasks such as zero-shot image classification, image-text retrieval, and text-to-image generation. However, the compositional reasoning abilities of existing VLMs remains subpar. The root of this limitation lies in the inadequate alignment between the images and captions in the pretraining datasets. Additionally, the current contrastive learning objective fails to focus on fine-grained grounding components like relations, actions, and attributes, resulting in bag-of-words representations. We introduce a simple and effective method to improve compositional reasoning in VLMs. Our method better leverages available datasets by refining and expanding the standard image-text contrastive learning framework. Our approach does not require specific annotations and does not incur extra parameters. When integrated with CLIP, our technique yields notable improvement over state-of-the-art baselines across five vision-language compositional benchmarks. We open-source our code at https://github.com/lezhang7/Enhance-FineGrained.
4/26/2024