Surpassing legacy approaches to PWR core reload optimization with single-objective Reinforcement learning

0
Sign in to get full access
Overview
• The paper presents a hybrid approach that combines single-objective and multi-objective Reinforcement Learning (RL) algorithms to optimize the economic operation of the US nuclear power fleet.
• The goal is to surpass legacy approaches and human intelligence in this domain, enabling more efficient and cost-effective nuclear power generation.
• The research leverages interpretable AI techniques to provide insights into the decision-making process and facilitate transparent and accountable operations.
Plain English Explanation
The paper focuses on improving the economic operation of nuclear power plants in the United States. Nuclear power is an important source of electricity, but running these plants efficiently and cost-effectively can be challenging. The researchers developed a new approach that combines different machine learning techniques, specifically Reinforcement Learning (RL), to optimize the operations of the nuclear fleet.
RL is a type of artificial intelligence that learns by interacting with an environment and receiving rewards or penalties for its actions. In this case, the RL algorithms are trained to make decisions that would maximize the economic performance of the nuclear plants, such as minimizing costs and maximizing energy production.
The researchers used a hybrid approach, combining both single-objective and multi-objective RL algorithms. Single-objective RL focuses on optimizing a single metric, like cost, while multi-objective RL tries to balance multiple, potentially conflicting goals, like cost and environmental impact.
By using this hybrid approach, the researchers aim to surpass the performance of traditional methods and even human experts in managing the nuclear fleet. Additionally, they incorporate interpretable AI techniques, which means the decision-making process of the RL algorithms can be explained and understood more easily. This transparency is important for maintaining trust and accountability in the operation of critical infrastructure like nuclear power plants.
Technical Explanation
The paper presents a hybrid Reinforcement Learning (RL)-based optimization framework for the economic operation of the US nuclear power fleet. The researchers develop a combination of single-objective and multi-objective RL algorithms to tackle this complex optimization problem.
The single-objective RL component focuses on optimizing a specific performance metric, such as minimizing the operating costs of the nuclear plants. The multi-objective RL component aims to balance multiple, potentially conflicting objectives, like cost, energy production, and environmental impact.
By using this hybrid approach, the researchers seek to surpass the performance of legacy optimization methods and even human experts in managing the nuclear fleet. The incorporation of interpretable AI techniques, such as explainable AI and Pareto-based optimization, allows for transparent decision-making and accountability in the operation of the nuclear power plants.
The researchers conducted extensive simulations and experiments to validate the effectiveness of their hybrid RL-based optimization framework. They compared the performance of their approach to traditional optimization methods and human expert decisions, demonstrating significant improvements in economic efficiency and operational outcomes.
Critical Analysis
The paper presents a comprehensive and well-designed approach to optimize the economic operation of the US nuclear fleet using a hybrid Reinforcement Learning framework. The integration of single-objective and multi-objective RL algorithms is a novel and promising strategy to tackle the complex trade-offs involved in nuclear power plant management.
One potential limitation of the research is the reliance on simulation-based experiments. While the simulations appear to be well-designed, there may be some discrepancies between the simulated environment and the real-world complexities of nuclear power plant operations. Validating the approach on real-world data or in a pilot deployment could provide additional insights and help address any potential gaps between the simulated and actual performance.
Another area for further investigation could be the robustness of the hybrid RL-based optimization framework to uncertainties and disruptions in the nuclear power system, such as unexpected equipment failures, changes in electricity demand, or fluctuations in fuel prices. Assessing the system's resilience to these types of challenges would be valuable for ensuring the long-term reliability and viability of the proposed approach.
Conclusion
The paper presents a novel and compelling approach to optimize the economic operation of the US nuclear power fleet using a hybrid Reinforcement Learning framework. By combining single-objective and multi-objective RL algorithms, the researchers aim to surpass legacy optimization methods and human experts in managing this critical infrastructure.
The incorporation of interpretable AI techniques, such as explainable AI and Pareto-based optimization, is a significant strength of the research, as it enables transparent and accountable decision-making in the operation of nuclear power plants.
The successful implementation of this hybrid RL-based optimization framework could lead to significant improvements in the economic efficiency and environmental sustainability of the US nuclear fleet, ultimately contributing to a more reliable and cost-effective energy supply for the nation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Surpassing legacy approaches to PWR core reload optimization with single-objective Reinforcement learning
Paul Seurin, Koroush Shirvan
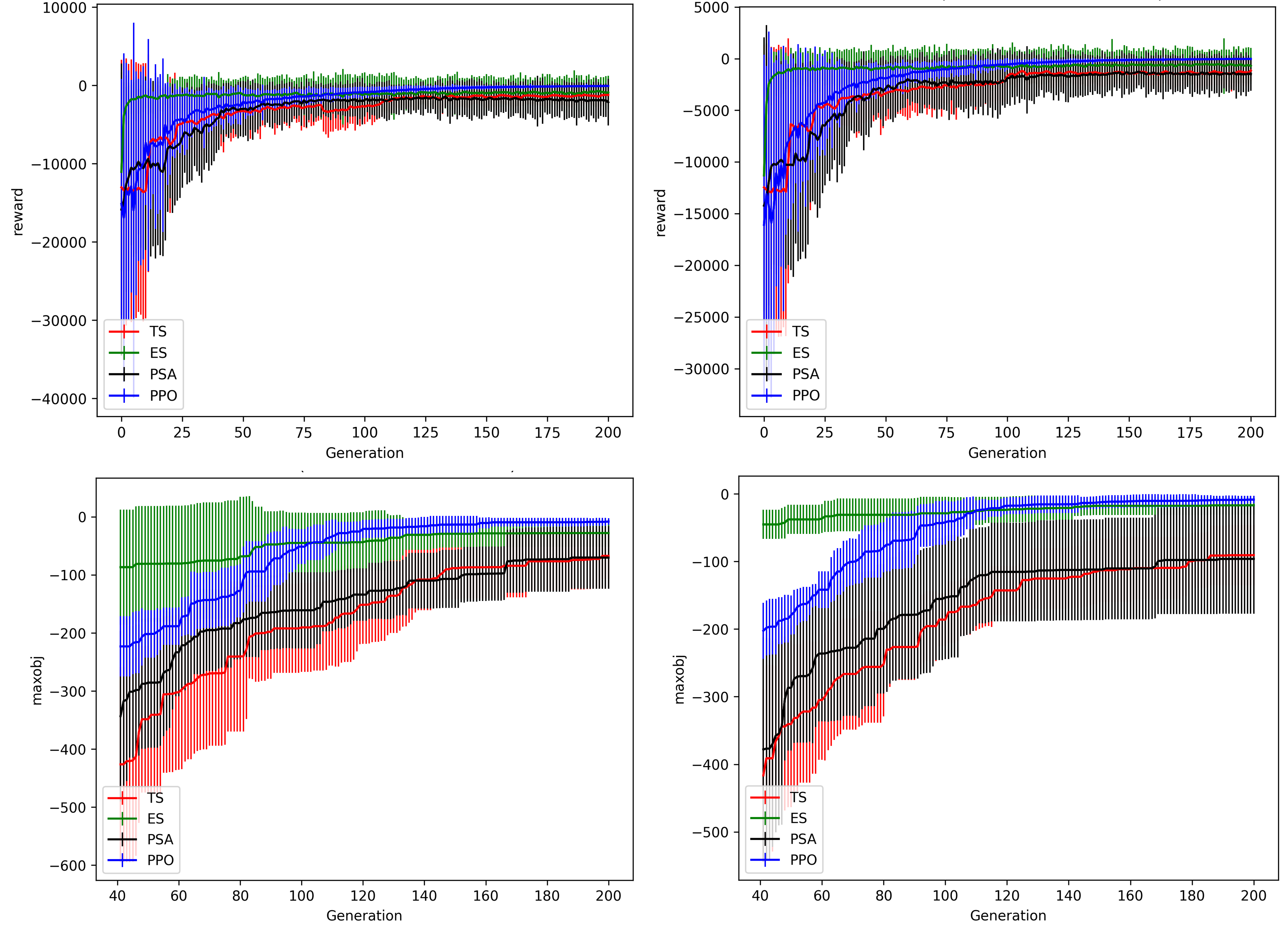
Optimizing the fuel cycle cost through the optimization of nuclear reactor core loading patterns involves multiple objectives and constraints, leading to a vast number of candidate solutions that cannot be explicitly solved. To advance the state-of-the-art in core reload patterns, we have developed methods based on Deep Reinforcement Learning (DRL) for both single- and multi-objective optimization. Our previous research has laid the groundwork for these approaches and demonstrated their ability to discover high-quality patterns within a reasonable time frame. On the other hand, stochastic optimization (SO) approaches are commonly used in the literature, but there is no rigorous explanation that shows which approach is better in which scenario. In this paper, we demonstrate the advantage of our RL-based approach, specifically using Proximal Policy Optimization (PPO), against the most commonly used SO-based methods: Genetic Algorithm (GA), Parallel Simulated Annealing (PSA) with mixing of states, and Tabu Search (TS), as well as an ensemble-based method, Prioritized Replay Evolutionary and Swarm Algorithm (PESA). We found that the LP scenarios derived in this paper are amenable to a global search to identify promising research directions rapidly, but then need to transition into a local search to exploit these directions efficiently and prevent getting stuck in local optima. PPO adapts its search capability via a policy with learnable weights, allowing it to function as both a global and local search method. Subsequently, we compared all algorithms against PPO in long runs, which exacerbated the differences seen in the shorter cases. Overall, the work demonstrates the statistical superiority of PPO compared to the other considered algorithms.
Read more7/16/2024
🏅
0
Multistep Criticality Search and Power Shaping in Microreactors with Reinforcement Learning
Majdi I. Radaideh, Leo Tunkle, Dean Price, Kamal Abdulraheem, Linyu Lin, Moutaz Elias
Reducing operation and maintenance costs is a key objective for advanced reactors in general and microreactors in particular. To achieve this reduction, developing robust autonomous control algorithms is essential to ensure safe and autonomous reactor operation. Recently, artificial intelligence and machine learning algorithms, specifically reinforcement learning (RL) algorithms, have seen rapid increased application to control problems, such as plasma control in fusion tokamaks and building energy management. In this work, we introduce the use of RL for intelligent control in nuclear microreactors. The RL agent is trained using proximal policy optimization (PPO) and advantage actor-critic (A2C), cutting-edge deep RL techniques, based on a high-fidelity simulation of a microreactor design inspired by the Westinghouse eVincitextsuperscript{TM} design. We utilized a Serpent model to generate data on drum positions, core criticality, and core power distribution for training a feedforward neural network surrogate model. This surrogate model was then used to guide a PPO and A2C control policies in determining the optimal drum position across various reactor burnup states, ensuring critical core conditions and symmetrical power distribution across all six core portions. The results demonstrate the excellent performance of PPO in identifying optimal drum positions, achieving a hextant power tilt ratio of approximately 1.002 (within the limit of $<$ 1.02) and maintaining criticality within a 10 pcm range. A2C did not provide as competitive of a performance as PPO in terms of performance metrics for all burnup steps considered in the cycle. Additionally, the results highlight the capability of well-trained RL control policies to quickly identify control actions, suggesting a promising approach for enabling real-time autonomous control through digital twins.
Read more6/26/2024

0
Design Optimization of Nuclear Fusion Reactor through Deep Reinforcement Learning
Jinsu Kim, Jaemin Seo
This research explores the application of Deep Reinforcement Learning (DRL) to optimize the design of a nuclear fusion reactor. DRL can efficiently address the challenging issues attributed to multiple physics and engineering constraints for steady-state operation. The fusion reactor design computation and the optimization code applicable to parallelization with DRL are developed. The proposed framework enables finding the optimal reactor design that satisfies the operational requirements while reducing building costs. Multi-objective design optimization for a fusion reactor is now simplified by DRL, indicating the high potential of the proposed framework for advancing the efficient and sustainable design of future reactors.
Read more9/14/2024

0
DPO: Differential reinforcement learning with application to optimal configuration search
Chandrajit Bajaj, Minh Nguyen
Reinforcement learning (RL) with continuous state and action spaces remains one of the most challenging problems within the field. Most current learning methods focus on integral identities such as value functions to derive an optimal strategy for the learning agent. In this paper, we instead study the dual form of the original RL formulation to propose the first differential RL framework that can handle settings with limited training samples and short-length episodes. Our approach introduces Differential Policy Optimization (DPO), a pointwise and stage-wise iteration method that optimizes policies encoded by local-movement operators. We prove a pointwise convergence estimate for DPO and provide a regret bound comparable with the best current theoretical derivation. Such pointwise estimate ensures that the learned policy matches the optimal path uniformly across different steps. We then apply DPO to a class of practical RL problems with continuous state and action spaces, and which search for optimal configurations with Lagrangian rewards. DPO is easy to implement, scalable, and shows competitive results on benchmarking experiments against several popular RL methods.
Read more8/14/2024