DPO: Differential reinforcement learning with application to optimal configuration search

0

Sign in to get full access
Overview
- The paper introduces a novel reinforcement learning approach called Differential Reinforcement Learning (DRL) and applies it to the problem of optimal configuration search.
- DRL aims to learn a policy that maximizes the expected differential reward, which is the difference between the current reward and a reference reward.
- The authors demonstrate the effectiveness of DRL on several benchmark tasks, showing that it can outperform traditional reinforcement learning methods.
Plain English Explanation
The paper presents a new way of teaching machines to learn and make decisions, called Differential Reinforcement Learning (DRL). The key idea behind DRL is to have the machine focus on improving its performance compared to a reference level, rather than just trying to maximize the overall reward.
Imagine you're teaching a robot to play chess. With traditional reinforcement learning, the robot would simply try to win as many games as possible. But with DRL, the robot would try to improve its performance game-by-game, comparing its current moves to a reference level of play. This allows the robot to make more targeted improvements and potentially reach a higher level of skill faster.
The authors apply this DRL approach to the problem of optimal configuration search, which is about finding the best settings or parameters for a system to achieve the desired outcome. This could be useful in areas like optimizing website designs or training language models.
By using DRL, the authors show that their system can outperform traditional reinforcement learning methods on several benchmark tasks. This suggests that DRL could be a promising approach for tackling complex optimization problems in a wide range of domains.
Technical Explanation
The key innovation of this paper is the Differential Reinforcement Learning (DRL) algorithm. Unlike standard reinforcement learning, which aims to maximize the total reward, DRL learns a policy that maximizes the expected differential reward - the difference between the current reward and a reference reward.
The authors formalize this as a Markov Decision Process, where the agent's goal is to find a policy that maximizes the expected differential return. They derive the gradient of this objective and use it to train the agent's policy network using standard gradient-based optimization techniques.
The authors apply DRL to the problem of optimal configuration search, where the goal is to find the best set of parameters or configuration for a system to achieve a desired outcome. They demonstrate the effectiveness of DRL on several benchmark tasks, including hyperparameter optimization for neural networks and robot control problems.
The results show that DRL can outperform traditional reinforcement learning approaches, as it is able to learn more nuanced policies that focus on improving performance relative to a reference, rather than just maximizing the overall reward.
Critical Analysis
The paper provides a solid theoretical foundation for Differential Reinforcement Learning and demonstrates its practical effectiveness on several benchmark tasks. However, there are a few potential limitations and areas for further research:
-
Sensitivity to reference reward: The performance of DRL may be sensitive to the choice of reference reward. The authors mention that this reference can be set based on domain knowledge, but it would be useful to explore more automated or adaptive ways of setting the reference.
-
Scalability to complex tasks: While the benchmark tasks in the paper are interesting, they may not fully capture the complexity of real-world optimization problems. Further research is needed to assess the scalability of DRL to larger-scale, more realistic configuration search problems.
-
Interpretability of learned policies: As with many deep reinforcement learning approaches, the learned policies in DRL may be difficult to interpret and understand. Developing more interpretable DRL methods could be an important direction for future work.
-
Potential biases in the reference reward: If the reference reward is not carefully chosen, it could lead to the DRL agent learning policies that optimize for the wrong objective. This is an important consideration when applying DRL in high-stakes domains.
Overall, this paper presents a promising new reinforcement learning approach that could have significant implications for a wide range of optimization and decision-making problems. Further research to address the limitations and explore the broader applicability of DRL would be a valuable contribution to the field.
Conclusion
This paper introduces a novel reinforcement learning method called Differential Reinforcement Learning (DRL), which aims to learn policies that maximize the expected differential reward - the difference between the current reward and a reference reward. The authors demonstrate the effectiveness of DRL on several benchmark tasks, showing that it can outperform traditional reinforcement learning approaches.
The key insight of DRL is to focus on relative performance improvement rather than just maximizing the overall reward. This allows the agent to learn more nuanced policies that are tailored to the specific problem at hand. While the paper highlights some potential limitations, the DRL approach shows promise as a powerful tool for tackling complex optimization and decision-making problems across a variety of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DPO: Differential reinforcement learning with application to optimal configuration search
Chandrajit Bajaj, Minh Nguyen
Reinforcement learning (RL) with continuous state and action spaces remains one of the most challenging problems within the field. Most current learning methods focus on integral identities such as value functions to derive an optimal strategy for the learning agent. In this paper, we instead study the dual form of the original RL formulation to propose the first differential RL framework that can handle settings with limited training samples and short-length episodes. Our approach introduces Differential Policy Optimization (DPO), a pointwise and stage-wise iteration method that optimizes policies encoded by local-movement operators. We prove a pointwise convergence estimate for DPO and provide a regret bound comparable with the best current theoretical derivation. Such pointwise estimate ensures that the learned policy matches the optimal path uniformly across different steps. We then apply DPO to a class of practical RL problems with continuous state and action spaces, and which search for optimal configurations with Lagrangian rewards. DPO is easy to implement, scalable, and shows competitive results on benchmarking experiments against several popular RL methods.
Read more8/14/2024
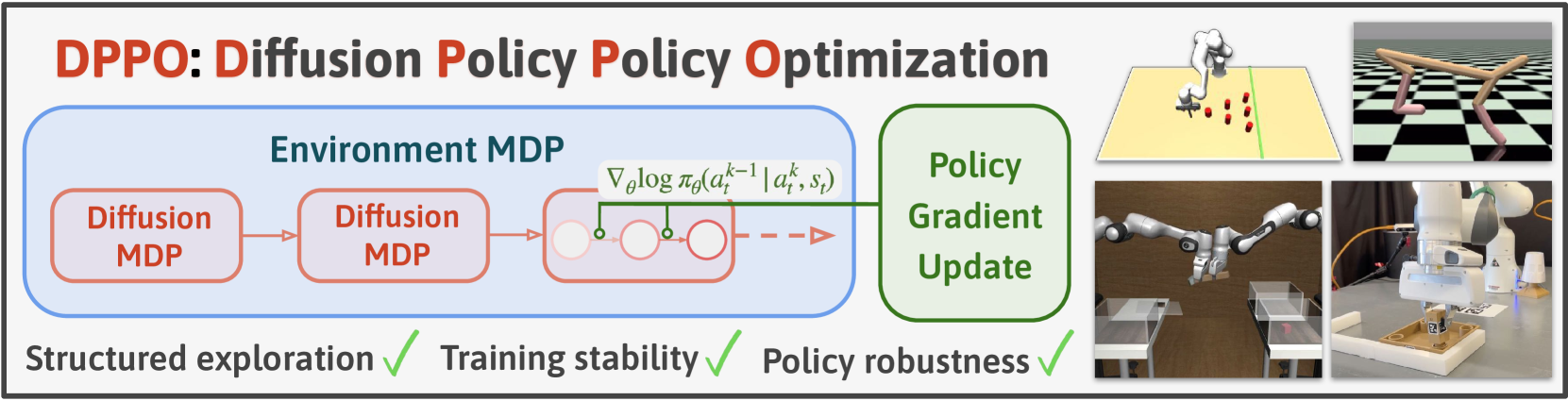
0
Diffusion Policy Policy Optimization
Allen Z. Ren, Justin Lidard, Lars L. Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, Max Simchowitz
We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io
Read more9/4/2024
🛠️
0
Direct Multi-Turn Preference Optimization for Language Agents
Wentao Shi, Mengqi Yuan, Junkang Wu, Qifan Wang, Fuli Feng
Adapting Large Language Models (LLMs) for agent tasks is critical in developing language agents. Direct Preference Optimization (DPO) is a promising technique for this adaptation with the alleviation of compounding errors, offering a means to directly optimize Reinforcement Learning (RL) objectives. However, applying DPO to multi-turn tasks presents challenges due to the inability to cancel the partition function. Overcoming this obstacle involves making the partition function independent of the current state and addressing length disparities between preferred and dis-preferred trajectories. In this light, we replace the policy constraint with the state-action occupancy measure constraint in the RL objective and add length normalization to the Bradley-Terry model, yielding a novel loss function named DMPO for multi-turn agent tasks with theoretical explanations. Extensive experiments on three multi-turn agent task datasets confirm the effectiveness and superiority of the DMPO loss.
Read more8/20/2024

0
DPO Meets PPO: Reinforced Token Optimization for RLHF
Han Zhong, Guhao Feng, Wei Xiong, Xinle Cheng, Li Zhao, Di He, Jiang Bian, Liwei Wang
In the classical Reinforcement Learning from Human Feedback (RLHF) framework, Proximal Policy Optimization (PPO) is employed to learn from sparse, sentence-level rewards -- a challenging scenario in traditional deep reinforcement learning. Despite the great successes of PPO in the alignment of state-of-the-art closed-source large language models (LLMs), its open-source implementation is still largely sub-optimal, as widely reported by numerous research studies. To address these issues, we introduce a framework that models RLHF problems as a Markov decision process (MDP), enabling the capture of fine-grained token-wise information. Furthermore, we provide theoretical insights that demonstrate the superiority of our MDP framework over the previous sentence-level bandit formulation. Under this framework, we introduce an algorithm, dubbed as Reinforced Token Optimization (texttt{RTO}), which learns the token-wise reward function from preference data and performs policy optimization based on this learned token-wise reward signal. Theoretically, texttt{RTO} is proven to have the capability of finding the near-optimal policy sample-efficiently. For its practical implementation, texttt{RTO} innovatively integrates Direct Preference Optimization (DPO) and PPO. DPO, originally derived from sparse sentence rewards, surprisingly provides us with a token-wise characterization of response quality, which is seamlessly incorporated into our subsequent PPO training stage. Extensive real-world alignment experiments verify the effectiveness of the proposed approach.
Read more7/23/2024