A Survey on Data Quality Dimensions and Tools for Machine Learning

0
Sign in to get full access
Overview
- This paper provides a comprehensive survey of data quality dimensions and tools for machine learning.
- The authors review the state-of-the-art in data quality management for machine learning, covering key concepts like data-centric AI and data quality dimensions.
- They also examine various data quality assessment and improvement tools, highlighting their capabilities and limitations.
- The paper aims to serve as a reference for researchers and practitioners working on improving data quality for machine learning applications.
Plain English Explanation
When building machine learning models, the quality of the data used for training is crucial. Poor data quality can significantly impact model performance and lead to unreliable results. This paper takes a deep dive into the various aspects of data quality, known as "data quality dimensions," and the tools available to assess and improve data quality.
The authors start by explaining the concept of "data-centric AI," which focuses on optimizing the data rather than just the model. This is an important shift, as traditionally, the emphasis has been on improving the machine learning algorithms themselves. However, researchers have realized that having high-quality data is just as critical for achieving good model performance.
The paper then explores different data quality dimensions, such as accuracy, completeness, consistency, and timeliness. These dimensions help define what makes data "good" or "bad" and provide a framework for evaluating data quality. For example, if the data contains many missing values (incomplete), it may not be suitable for training a model.
Next, the authors review a range of data quality assessment and improvement tools. These tools can help identify data quality issues, such as outliers, anomalies, or biases, and suggest ways to address them. Some tools automate the process of data cleaning and transformation, while others provide visualizations to help humans understand data quality problems.
The key takeaway is that data quality is a critical, but often overlooked, aspect of building effective machine learning models. By understanding the various data quality dimensions and leveraging the right tools, researchers and practitioners can improve the reliability and performance of their AI systems.
Technical Explanation
The paper begins by introducing the concept of "data-centric AI," which emphasizes the importance of data quality in machine learning. The authors highlight how poor data quality can negatively impact model performance and argue that data quality management should be a central part of the machine learning development process.
The core of the paper is a comprehensive review of data quality dimensions. The authors identify and describe several key dimensions, including accuracy, completeness, consistency, timeliness, and others. These dimensions provide a framework for evaluating the quality of data used in machine learning applications.
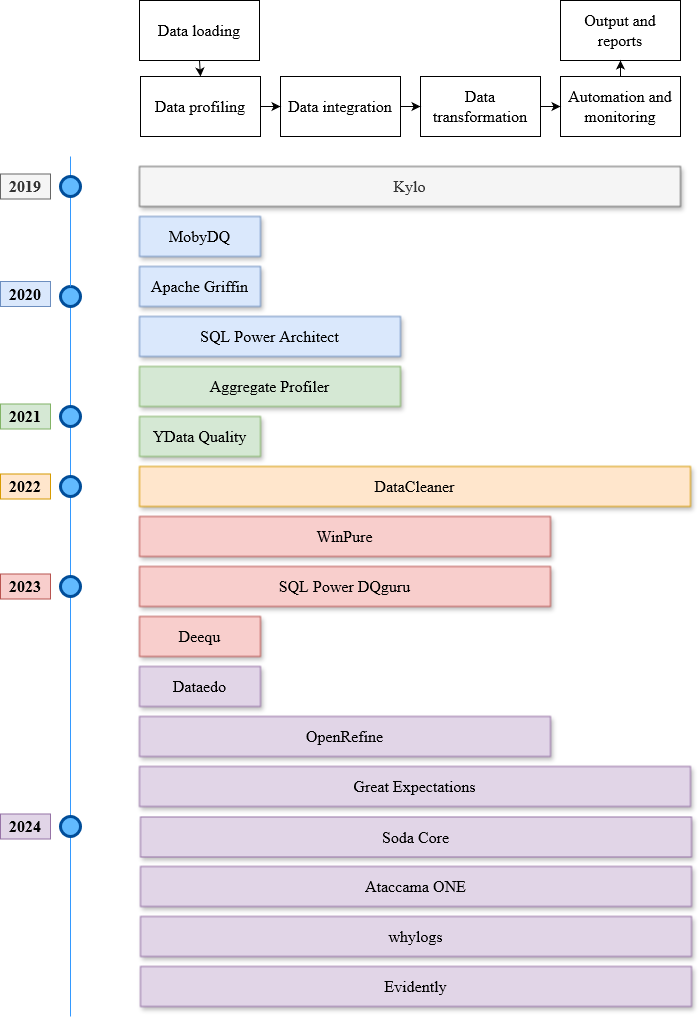
The paper then examines a wide range of data quality assessment and improvement tools. These tools can be used to identify data quality issues, such as outliers, anomalies, or biases, and suggest ways to address them. The authors categorize these tools based on their capabilities, such as data profiling, data cleaning, data transformation, and data monitoring.
For each tool, the paper provides a detailed overview of its functionality, strengths, and limitations. This information can help researchers and practitioners choose the right tools for their specific data quality challenges.
Throughout the paper, the authors draw connections to related research areas, such as data quality management automation and comprehensive taxonomies for dataset evaluation. This contextual information helps readers understand the broader landscape of data quality research for machine learning.
Critical Analysis
The paper provides a comprehensive and well-researched overview of data quality dimensions and tools for machine learning. The authors' detailed exploration of the various data quality dimensions is particularly valuable, as it helps establish a common framework for understanding and evaluating data quality.
However, the paper does not delve deeply into the practical challenges of implementing data quality management in real-world machine learning projects. While the authors discuss the capabilities and limitations of different data quality tools, they do not provide much guidance on how to effectively integrate these tools into the machine learning development lifecycle.
Additionally, the paper focuses primarily on technical aspects of data quality and does not extensively address the organizational and cultural factors that can influence data quality management. Successful data quality initiatives often require buy-in from stakeholders across the organization, and the paper could have provided more insights on this aspect.
Finally, the paper does not explore the potential ethical implications of data quality management, such as the impact of data biases or the use of data quality tools to monitor and enforce data standards. As machine learning systems become more pervasive, it will be crucial for researchers to consider the ethical considerations around data quality.
Conclusion
This paper offers a valuable and comprehensive survey of the data quality dimensions and tools relevant to machine learning. By highlighting the importance of data quality, the authors underscore the need for a data-centric approach to building effective AI systems.
The detailed exploration of data quality dimensions and the review of various data quality assessment and improvement tools provide a solid foundation for researchers and practitioners looking to enhance the reliability and performance of their machine learning models. However, the paper could have delved deeper into the practical and ethical challenges of implementing data quality management in real-world scenarios.
Overall, this paper serves as an important reference for the growing field of data-centric AI and lays the groundwork for future research on improving data quality for machine learning applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Survey on Data Quality Dimensions and Tools for Machine Learning
Yuhan Zhou, Fengjiao Tu, Kewei Sha, Junhua Ding, Haihua Chen
Machine learning (ML) technologies have become substantial in practically all aspects of our society, and data quality (DQ) is critical for the performance, fairness, robustness, safety, and scalability of ML models. With the large and complex data in data-centric AI, traditional methods like exploratory data analysis (EDA) and cross-validation (CV) face challenges, highlighting the importance of mastering DQ tools. In this survey, we review 17 DQ evaluation and improvement tools in the last 5 years. By introducing the DQ dimensions, metrics, and main functions embedded in these tools, we compare their strengths and limitations and propose a roadmap for developing open-source DQ tools for ML. Based on the discussions on the challenges and emerging trends, we further highlight the potential applications of large language models (LLMs) and generative AI in DQ evaluation and improvement for ML. We believe this comprehensive survey can enhance understanding of DQ in ML and could drive progress in data-centric AI. A complete list of the literature investigated in this survey is available on GitHub at: https://github.com/haihua0913/awesome-dq4ml.
Read more7/1/2024

0
Data Quality in Edge Machine Learning: A State-of-the-Art Survey
Mohammed Djameleddine Belgoumri, Mohamed Reda Bouadjenek, Sunil Aryal, Hakim Hacid
Data-driven Artificial Intelligence (AI) systems trained using Machine Learning (ML) are shaping an ever-increasing (in size and importance) portion of our lives, including, but not limited to, recommendation systems, autonomous driving technologies, healthcare diagnostics, financial services, and personalized marketing. On the one hand, the outsized influence of these systems imposes a high standard of quality, particularly in the data used to train them. On the other hand, establishing and maintaining standards of Data Quality (DQ) becomes more challenging due to the proliferation of Edge Computing and Internet of Things devices, along with their increasing adoption for training and deploying ML models. The nature of the edge environment -- characterized by limited resources, decentralized data storage, and processing -- exacerbates data-related issues, making them more frequent, severe, and difficult to detect and mitigate. From these observations, it follows that DQ research for edge ML is a critical and urgent exploration track for the safety and robust usefulness of present and future AI systems. Despite this fact, DQ research for edge ML is still in its infancy. The literature on this subject remains fragmented and scattered across different research communities, with no comprehensive survey to date. Hence, this paper aims to fill this gap by providing a global view of the existing literature from multiple disciplines that can be grouped under the umbrella of DQ for edge ML. Specifically, we present a tentative definition of data quality in Edge computing, which we use to establish a set of DQ dimensions. We explore each dimension in detail, including existing solutions for mitigation.
Read more6/6/2024
📊
0
Towards augmented data quality management: Automation of Data Quality Rule Definition in Data Warehouses
Heidi Carolina Tamm, Anastasija Nikiforova
In the contemporary data-driven landscape, ensuring data quality (DQ) is crucial for deriving actionable insights from vast data repositories. The objective of this study is to explore the potential for automating data quality management within data warehouses as data repository commonly used by large organizations. By conducting a systematic review of existing DQ tools available in the market and academic literature, the study assesses their capability to automatically detect and enforce data quality rules. The review encompassed 151 tools from various sources, revealing that most current tools focus on data cleansing and fixing in domain-specific databases rather than data warehouses. Only a limited number of tools, specifically ten, demonstrated the capability to detect DQ rules, not to mention implementing this in data warehouses. The findings underscore a significant gap in the market and academic research regarding AI-augmented DQ rule detection in data warehouses. This paper advocates for further development in this area to enhance the efficiency of DQ management processes, reduce human workload, and lower costs. The study highlights the necessity of advanced tools for automated DQ rule detection, paving the way for improved practices in data quality management tailored to data warehouse environments. The study can guide organizations in selecting data quality tool that would meet their requirements most.
Read more6/18/2024

0
Data Readiness for AI: A 360-Degree Survey
Kaveen Hiniduma, Suren Byna, Jean Luca Bez
Data are the critical fuel for Artificial Intelligence (AI) models. Poor quality data produces inaccurate and ineffective AI models that may lead to incorrect or unsafe use. Checking for data readiness is a crucial step in improving data quality. Numerous R&D efforts have been spent on improving data quality. However, standardized metrics for evaluating data readiness for use in AI training are still evolving. In this study, we perform a comprehensive survey of metrics used for verifying AI's data readiness. This survey examines more than 120 papers that are published by ACM Digital Library, IEEE Xplore, other reputable journals, and articles published on the web by prominent AI experts. This survey aims to propose a taxonomy of data readiness for AI (DRAI) metrics for structured and unstructured datasets. We anticipate that this taxonomy can lead to new standards for DRAI metrics that would be used for enhancing the quality and accuracy of AI training and inference.
Read more4/10/2024