Data Readiness for AI: A 360-Degree Survey
2404.05779
0
0

Abstract
Data are the critical fuel for Artificial Intelligence (AI) models. Poor quality data produces inaccurate and ineffective AI models that may lead to incorrect or unsafe use. Checking for data readiness is a crucial step in improving data quality. Numerous R&D efforts have been spent on improving data quality. However, standardized metrics for evaluating data readiness for use in AI training are still evolving. In this study, we perform a comprehensive survey of metrics used for verifying AI's data readiness. This survey examines more than 120 papers that are published by ACM Digital Library, IEEE Xplore, other reputable journals, and articles published on the web by prominent AI experts. This survey aims to propose a taxonomy of data readiness for AI (DRAI) metrics for structured and unstructured datasets. We anticipate that this taxonomy can lead to new standards for DRAI metrics that would be used for enhancing the quality and accuracy of AI training and inference.
Create account to get full access
Overview
- Provides a comprehensive survey of the current state of data readiness for AI systems
- Examines data quality metrics, assessment methods, and practical considerations for ensuring high-quality data for AI
- Identifies key challenges and best practices for improving data readiness in real-world AI deployments
Plain English Explanation
This paper takes a broad look at the topic of "data readiness" for artificial intelligence (AI) systems. The authors recognize that high-quality, well-curated data is essential for building effective AI models, but achieving this data readiness can be a major challenge in practice.
The paper explores various metrics and methods for assessing the quality and suitability of data for AI, covering aspects like data completeness, accuracy, and fairness. It also looks at the organizational and process-oriented factors that influence data readiness, such as data governance, documentation, and human-centered design.
The key insight is that achieving true data readiness for AI is a multi-faceted challenge that requires close attention to technical, operational, and even cultural aspects of data management. By taking a holistic "360-degree" view, the paper aims to provide a comprehensive framework for organizations to assess and improve their data readiness capabilities.
Technical Explanation
The paper begins by reviewing the existing literature on data quality and AI system development, highlighting the critical role of data readiness in enabling successful AI deployments. It then introduces the authors' proposed "Data Readiness for AI" (DRAI) framework, which encompasses a broad range of technical and non-technical factors that influence data quality and suitability for AI.
The DRAI framework includes five key dimensions: data quality, data governance, data operations, data-centric engineering, and data culture. Within each dimension, the authors identify specific metrics, practices, and challenges that organizations must address to achieve a high level of data readiness.
For example, the data quality dimension covers aspects like data completeness, accuracy, consistency, and fairness. The data governance dimension addresses issues of data ownership, access controls, and policy-making. The data operations dimension covers data collection, processing, and monitoring workflows.
Throughout the paper, the authors draw on real-world case studies and existing research to illustrate the practical challenges and best practices associated with each DRAI dimension. The goal is to provide a comprehensive, actionable framework that organizations can use to assess and improve their data readiness capabilities.
Critical Analysis
The paper presents a well-researched and thoughtful analysis of the complex challenges surrounding data readiness for AI. By taking a holistic, 360-degree view, the authors have succeeded in identifying a broad range of technical, organizational, and cultural factors that must be addressed.
One potential limitation of the framework is the degree of abstraction - while the high-level dimensions and metrics provide a useful structure, the specific implementation details may vary significantly across different organizations and AI use cases. The authors acknowledge this challenge and emphasize the need for customization and context-specific application of the DRAI framework.
Additionally, the paper does not delve deeply into the practical challenges of deploying and scaling the DRAI framework within large, complex organizations. Issues like change management, cross-functional collaboration, and the allocation of resources to data readiness initiatives could be explored further.
Despite these minor caveats, the DRAI framework represents a valuable contribution to the growing body of research and guidance on building high-quality, trustworthy AI systems. By bringing together diverse perspectives and best practices, the paper provides a solid foundation for organizations to assess and improve their data readiness capabilities.
Conclusion
The "Data Readiness for AI: A 360-Degree Survey" paper offers a comprehensive and insightful examination of the multifaceted challenge of ensuring data quality and suitability for artificial intelligence systems. By proposing the DRAI framework, the authors have provided a structured approach to identifying and addressing the technical, organizational, and cultural factors that influence data readiness.
The paper's holistic perspective and focus on practical application make it a valuable resource for AI practitioners, data scientists, and organizational leaders seeking to build robust, trustworthy AI systems. By emphasizing the importance of data readiness and providing a clear roadmap for assessment and improvement, the authors have made a significant contribution to the ongoing efforts to realize the full potential of AI while mitigating its risks and challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
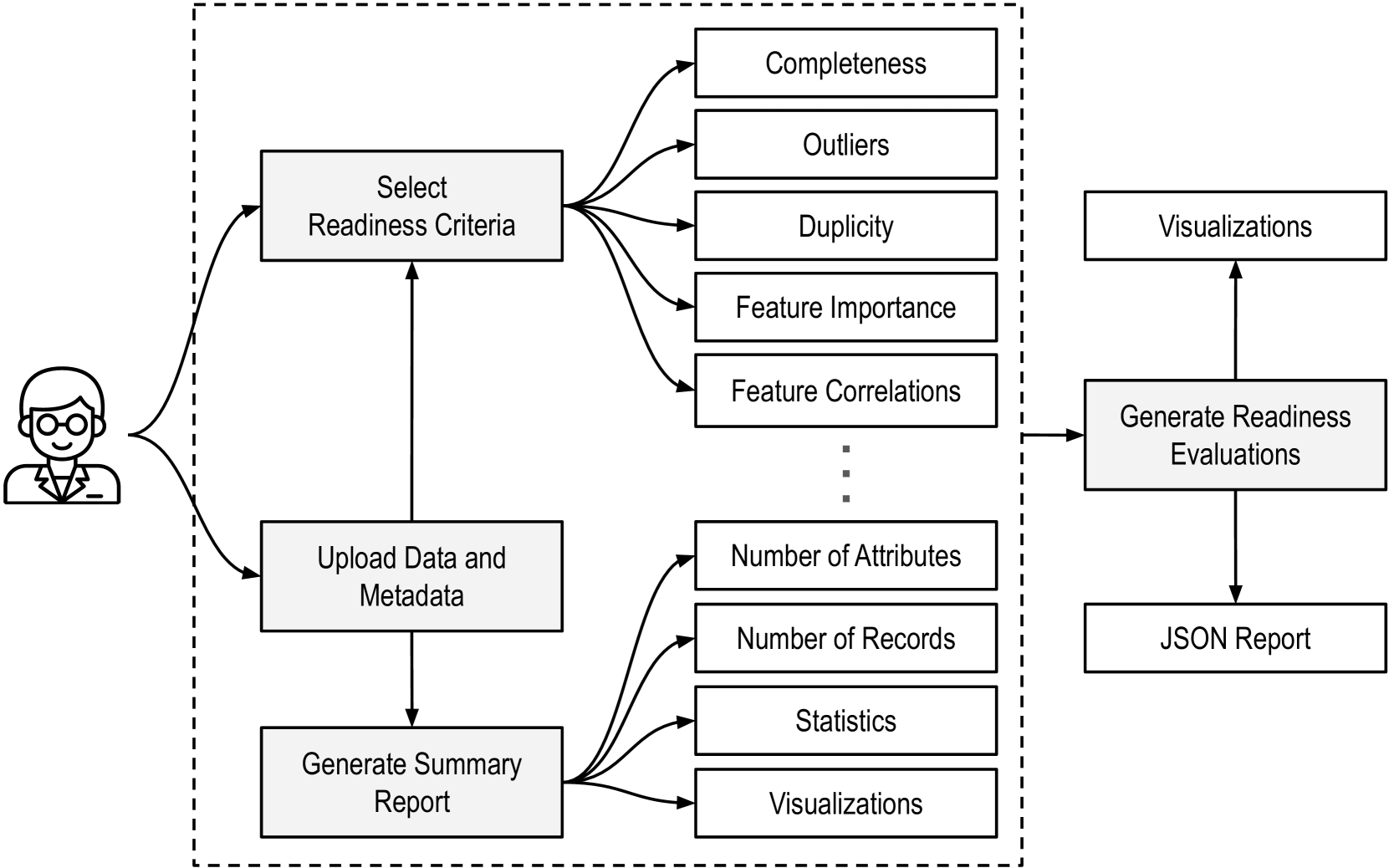
AI Data Readiness Inspector (AIDRIN) for Quantitative Assessment of Data Readiness for AI
Kaveen Hiniduma, Suren Byna, Jean Luca Bez, Ravi Madduri
0
0
Garbage In Garbage Out is a universally agreed quote by computer scientists from various domains, including Artificial Intelligence (AI). As data is the fuel for AI, models trained on low-quality, biased data are often ineffective. Computer scientists who use AI invest a considerable amount of time and effort in preparing the data for AI. However, there are no standard methods or frameworks for assessing the readiness of data for AI. To provide a quantifiable assessment of the readiness of data for AI processes, we define parameters of AI data readiness and introduce AIDRIN (AI Data Readiness Inspector). AIDRIN is a framework covering a broad range of readiness dimensions available in the literature that aid in evaluating the readiness of data quantitatively and qualitatively. AIDRIN uses metrics in traditional data quality assessment such as completeness, outliers, and duplicates for data evaluation. Furthermore, AIDRIN uses metrics specific to assess data for AI, such as feature importance, feature correlations, class imbalance, fairness, privacy, and FAIR (Findability, Accessibility, Interoperability, and Reusability) principle compliance. AIDRIN provides visualizations and reports to assist data scientists in further investigating the readiness of data. The AIDRIN framework enhances the efficiency of the machine learning pipeline to make informed decisions on data readiness for AI applications.
6/28/2024

Data Quality in Edge Machine Learning: A State-of-the-Art Survey
Mohammed Djameleddine Belgoumri, Mohamed Reda Bouadjenek, Sunil Aryal, Hakim Hacid
0
0
Data-driven Artificial Intelligence (AI) systems trained using Machine Learning (ML) are shaping an ever-increasing (in size and importance) portion of our lives, including, but not limited to, recommendation systems, autonomous driving technologies, healthcare diagnostics, financial services, and personalized marketing. On the one hand, the outsized influence of these systems imposes a high standard of quality, particularly in the data used to train them. On the other hand, establishing and maintaining standards of Data Quality (DQ) becomes more challenging due to the proliferation of Edge Computing and Internet of Things devices, along with their increasing adoption for training and deploying ML models. The nature of the edge environment -- characterized by limited resources, decentralized data storage, and processing -- exacerbates data-related issues, making them more frequent, severe, and difficult to detect and mitigate. From these observations, it follows that DQ research for edge ML is a critical and urgent exploration track for the safety and robust usefulness of present and future AI systems. Despite this fact, DQ research for edge ML is still in its infancy. The literature on this subject remains fragmented and scattered across different research communities, with no comprehensive survey to date. Hence, this paper aims to fill this gap by providing a global view of the existing literature from multiple disciplines that can be grouped under the umbrella of DQ for edge ML. Specifically, we present a tentative definition of data quality in Edge computing, which we use to establish a set of DQ dimensions. We explore each dimension in detail, including existing solutions for mitigation.
6/6/2024
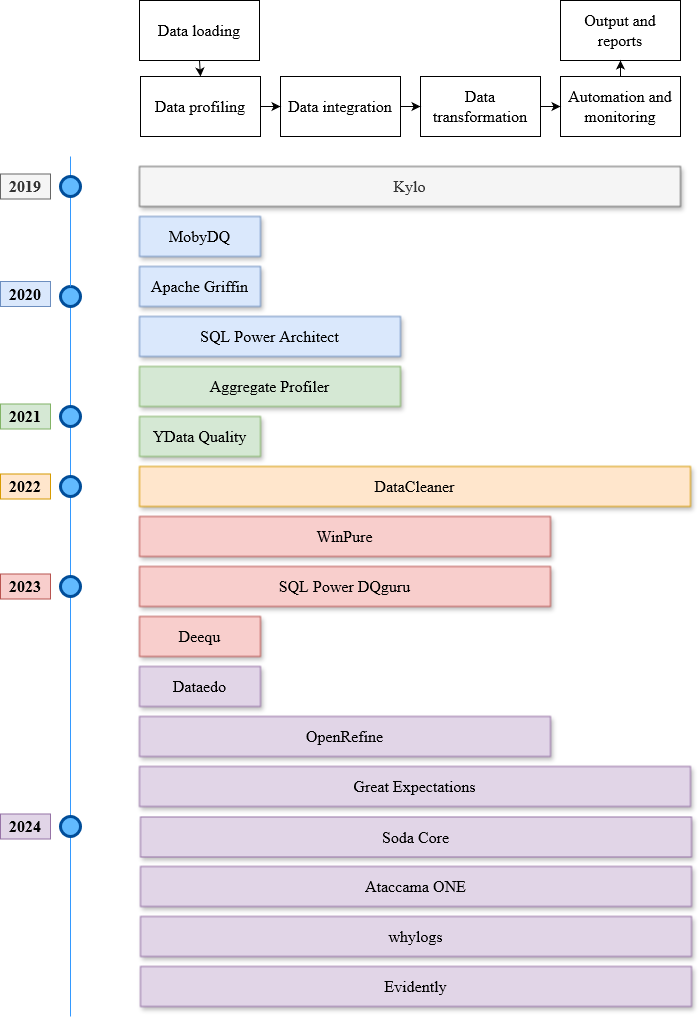
A Survey on Data Quality Dimensions and Tools for Machine Learning
Yuhan Zhou, Fengjiao Tu, Kewei Sha, Junhua Ding, Haihua Chen
0
0
Machine learning (ML) technologies have become substantial in practically all aspects of our society, and data quality (DQ) is critical for the performance, fairness, robustness, safety, and scalability of ML models. With the large and complex data in data-centric AI, traditional methods like exploratory data analysis (EDA) and cross-validation (CV) face challenges, highlighting the importance of mastering DQ tools. In this survey, we review 17 DQ evaluation and improvement tools in the last 5 years. By introducing the DQ dimensions, metrics, and main functions embedded in these tools, we compare their strengths and limitations and propose a roadmap for developing open-source DQ tools for ML. Based on the discussions on the challenges and emerging trends, we further highlight the potential applications of large language models (LLMs) and generative AI in DQ evaluation and improvement for ML. We believe this comprehensive survey can enhance understanding of DQ in ML and could drive progress in data-centric AI. A complete list of the literature investigated in this survey is available on GitHub at: https://github.com/haihua0913/awesome-dq4ml.
7/1/2024

AI Competitions and Benchmarks: Dataset Development
Romain Egele, Julio C. S. Jacques Junior, Jan N. van Rijn, Isabelle Guyon, Xavier Bar'o, Albert Clap'es, Prasanna Balaprakash, Sergio Escalera, Thomas Moeslund, Jun Wan
0
0
Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
4/16/2024