A Survey on Data Selection for Language Models

0
Sign in to get full access
Overview
- This paper provides a comprehensive survey of data selection techniques for training large language models.
- It presents a taxonomy to categorize and analyze different data selection approaches.
- The paper covers the background, motivation, and key considerations for effective data selection.
- It also discusses various data selection methods, their pros and cons, and potential future research directions.
Plain English Explanation
Developing large language models, such as GPT-3 or BERT, requires training on vast amounts of text data. However, not all data is equally valuable for model performance. A Survey on Data Selection for Language Models explores techniques to selectively choose the most relevant and informative data to train these powerful language models.
The paper starts by explaining the importance of data selection. Training language models on irrelevant or noisy data can lead to suboptimal performance, longer training times, and increased computational costs. The researchers introduce a taxonomy to categorize different data selection approaches, which helps understand their underlying principles and trade-offs.
For example, some methods focus on selecting data that is similar to the target task or domain, while others prioritize diversity to improve the model's general understanding. The paper delves into the nuances of these different strategies, highlighting their strengths and weaknesses.
By summarizing the current state of the art in data selection, the authors provide a valuable resource for researchers and practitioners working on large language models. The insights from this survey can help guide the development of more efficient and effective data curation and selection processes, ultimately leading to improved model performance and broader real-world applications.
Technical Explanation
The paper presents a comprehensive taxonomy for data selection in the context of training large language models. The taxonomy covers four main aspects:
-
Background and Motivation: This section discusses the importance of data selection, highlighting how it can improve model performance, reduce training costs, and address issues like dataset shift and out-of-domain generalization.
-
Data Selection Methods: The researchers categorize various data selection techniques into three broad groups:
target-aware ,target-agnostic , andhybrid approaches. These methods differ in their reliance on information about the target task or domain, and their trade-offs between diversity and task-specific relevance. -
Evaluation Metrics: The paper reviews common evaluation metrics used to assess the effectiveness of data selection, such as perplexity, task-specific performance, and diversity measures.
-
Challenges and Future Directions: The authors identify several open challenges, including the need for more principled theoretical frameworks, improved ways to handle multilingual and multimodal data, and the integration of data selection with other aspects of model development.
The technical discussion delves into the details of various data selection algorithms, such as Sentence Retrieval, Corpus Sampling, and Adversarial Data Selection. The paper also covers advanced techniques like Reinforcement Learning and Meta-Learning for data selection.
Critical Analysis
The survey provides a comprehensive overview of data selection techniques, but it also acknowledges several limitations and areas for further research. For instance, the authors note the need for more principled theoretical frameworks to guide data selection, as current approaches are often heuristic or empirical in nature.
Additionally, the paper highlights the challenges of handling multilingual and multimodal data, which are becoming increasingly important in the development of large language models. The integration of data selection with other aspects of model development, such as architecture search and hyperparameter optimization, is also identified as a crucial area for future work.
While the survey covers a wide range of data selection methods, the authors acknowledge that the field is rapidly evolving, and new techniques may emerge that are not yet reflected in the current taxonomy. Continuous updates and refinements to the taxonomy will be necessary to keep pace with the ongoing advancements in this area.
Conclusion
This survey on data selection for language models provides a valuable resource for researchers and practitioners working on the development of large-scale language models. By presenting a comprehensive taxonomy and analyzing the trade-offs of various data selection approaches, the paper offers insights that can inform more efficient and effective data curation and selection processes.
The insights from this work can help improve the performance, robustness, and generalization capabilities of large language models, ultimately leading to broader real-world applications and societal impact. As the field continues to evolve, this survey lays the groundwork for further research and innovation in this important aspect of language model development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Survey on Data Selection for Language Models
Alon Albalak, Yanai Elazar, Sang Michael Xie, Shayne Longpre, Nathan Lambert, Xinyi Wang, Niklas Muennighoff, Bairu Hou, Liangming Pan, Haewon Jeong, Colin Raffel, Shiyu Chang, Tatsunori Hashimoto, William Yang Wang
A major factor in the recent success of large language models is the use of enormous and ever-growing text datasets for unsupervised pre-training. However, naively training a model on all available data may not be optimal (or feasible), as the quality of available text data can vary. Filtering out data can also decrease the carbon footprint and financial costs of training models by reducing the amount of training required. Data selection methods aim to determine which candidate data points to include in the training dataset and how to appropriately sample from the selected data points. The promise of improved data selection methods has caused the volume of research in the area to rapidly expand. However, because deep learning is mostly driven by empirical evidence and experimentation on large-scale data is expensive, few organizations have the resources for extensive data selection research. Consequently, knowledge of effective data selection practices has become concentrated within a few organizations, many of which do not openly share their findings and methodologies. To narrow this gap in knowledge, we present a comprehensive review of existing literature on data selection methods and related research areas, providing a taxonomy of existing approaches. By describing the current landscape of research, this work aims to accelerate progress in data selection by establishing an entry point for new and established researchers. Additionally, throughout this review we draw attention to noticeable holes in the literature and conclude the paper by proposing promising avenues for future research.
Read more8/6/2024
0
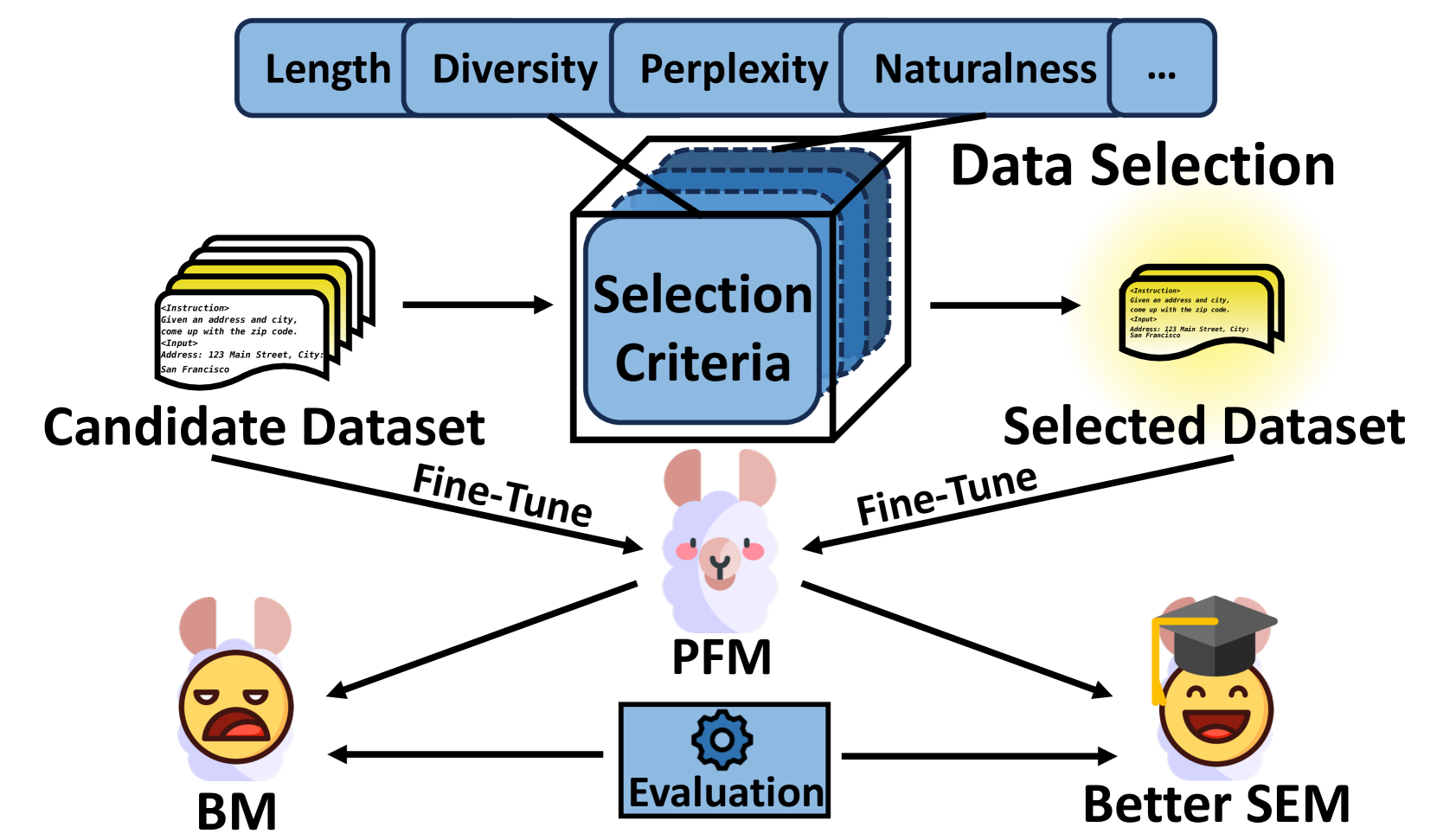
Take the essence and discard the dross: A Rethinking on Data Selection for Fine-Tuning Large Language Models
Ziche Liu, Rui Ke, Feng Jiang, Haizhou Li
Data selection for fine-tuning Large Language Models (LLMs) aims to select a high-quality subset from a given candidate dataset to train a Pending Fine-tune Model (PFM) into a Selective-Enhanced Model (SEM). It can improve the model performance and accelerate the training process. Although a few surveys have investigated related works of data selection, there is a lack of comprehensive comparison between existing methods due to their various experimental settings. To address this issue, we first propose a three-stage scheme for data selection and comprehensively review existing works according to this scheme. Then, we design a unified comparing method with ratio-based efficiency indicators and ranking-based feasibility indicators to overcome the difficulty of comparing various models with diverse experimental settings. After an in-depth comparative analysis, we find that the more targeted method with data-specific and model-specific quality labels has higher efficiency, but the introduction of additional noise information should be avoided when designing selection algorithms. Finally, we summarize the trends in data selection and highlight the short-term and long-term challenges to guide future research.
Read more6/21/2024

0
Unleashing the Power of Data Tsunami: A Comprehensive Survey on Data Assessment and Selection for Instruction Tuning of Language Models
Yulei Qin, Yuncheng Yang, Pengcheng Guo, Gang Li, Hang Shao, Yuchen Shi, Zihan Xu, Yun Gu, Ke Li, Xing Sun
Instruction tuning plays a critical role in aligning large language models (LLMs) with human preference. Despite the vast amount of open instruction datasets, naively training a LLM on all existing instructions may not be optimal and practical. To pinpoint the most beneficial datapoints, data assessment and selection methods have been proposed in the fields of natural language processing (NLP) and deep learning. However, under the context of instruction tuning, there still exists a gap in knowledge on what kind of data evaluation metrics can be employed and how they can be integrated into the selection mechanism. To bridge this gap, we present a comprehensive review on existing literature of data assessment and selection especially for instruction tuning of LLMs. We systematically categorize all applicable methods into quality-based, diversity-based, and importance-based ones where a unified, fine-grained taxonomy is structured. For each category, representative methods are elaborated to describe the landscape of relevant research. In addition, comparison between latest methods is conducted on their officially reported results to provide in-depth discussions on their limitations. Finally, we summarize the open challenges and propose the promosing avenues for future studies. All related contents are available at https://github.com/yuleiqin/fantastic-data-engineering.
Read more8/9/2024

0
Exploring Large Language Models for Feature Selection: A Data-centric Perspective
Dawei Li, Zhen Tan, Huan Liu
The rapid advancement of Large Language Models (LLMs) has significantly influenced various domains, leveraging their exceptional few-shot and zero-shot learning capabilities. In this work, we aim to explore and understand the LLMs-based feature selection methods from a data-centric perspective. We begin by categorizing existing feature selection methods with LLMs into two groups: data-driven feature selection which requires samples values to do statistical inference and text-based feature selection which utilizes prior knowledge of LLMs to do semantical associations using descriptive context. We conduct extensive experiments in both classification and regression tasks with LLMs in various sizes (e.g., GPT-4, ChatGPT and LLaMA-2). Our findings emphasize the effectiveness and robustness of text-based feature selection methods and showcase their potentials using a real-world medical application. We also discuss the challenges and future opportunities in employing LLMs for feature selection, offering insights for further research and development in this emerging field.
Read more8/23/2024