A Survey of Data Synthesis Approaches

0
Sign in to get full access
Overview
- Provides a high-level summary of data synthesis approaches
- Covers objectives, techniques, and applications of data augmentation
- Discusses the benefits and limitations of various data synthesis methods
Plain English Explanation
Data synthesis is the process of generating new data that mimics the characteristics of real-world data. This can be useful for improving diversity in machine learning datasets, addressing data imbalances, and enabling privacy-preserving data sharing.
Some common data synthesis techniques include generative adversarial networks (GANs), variational autoencoders (VAEs), and Bayesian networks. These methods can create synthetic data that retains the statistical properties of the original data while introducing variations.
Data synthesis has applications in medical imaging, financial modeling, and natural language processing, among other domains. However, it's important to be aware of the limitations of synthetic data, such as the potential for introducing biases or failing to capture all the nuances of real-world data.
Technical Explanation
The paper provides a comprehensive survey of data synthesis approaches, covering the key objectives, techniques, and applications of data augmentation.
In Section 2, the authors outline three main objectives of data augmentation: improving diversity, addressing data imbalances, and enabling privacy-preserving data sharing. These objectives guide the selection and application of different data synthesis methods.
Section 3 delves into the technical details of data synthesis techniques, including generative adversarial networks (GANs), variational autoencoders (VAEs), and Bayesian networks. The authors explain how these methods can generate synthetic data that preserves the statistical properties of the original data.
The paper then explores various applications of data synthesis, such as medical imaging, financial modeling, and natural language processing. These case studies demonstrate the versatility and potential benefits of data augmentation in different domains.
Critical Analysis
The paper provides a thorough and well-structured overview of data synthesis approaches, highlighting their strengths and limitations. The authors acknowledge that while data augmentation can be a powerful tool, it is not a panacea and comes with its own set of challenges.
One potential limitation discussed is the risk of introducing biases into the synthetic data, which could then be propagated into downstream models. The authors suggest that careful curation and evaluation of the synthetic data are crucial to mitigate this issue.
Another concern raised is the difficulty in assessing the quality and fidelity of the synthetic data, as there is no universally accepted metric for evaluating the similarity between real and synthetic data. The authors suggest that further research is needed to develop robust evaluation frameworks.
Overall, the paper provides a valuable and balanced perspective on the current state of data synthesis research, highlighting both the promising applications and the need for continued development and refinement of these techniques.
Conclusion
This survey paper offers a comprehensive overview of data synthesis approaches, their objectives, techniques, and applications. While data augmentation can be a powerful tool for improving machine learning models, it is important to be aware of the potential limitations and carefully consider the trade-offs involved.
As the field of data synthesis continues to evolve, researchers and practitioners will need to grapple with challenges such as bias mitigation and quality assessment. By understanding the current state of the art and the open research questions, the community can work towards developing more robust and reliable data synthesis methods that can truly unlock the potential of synthetic data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Survey of Data Synthesis Approaches
Hsin-Yu Chang, Pei-Yu Chen, Tun-Hsiang Chou, Chang-Sheng Kao, Hsuan-Yun Yu, Yen-Ting Lin, Yun-Nung Chen
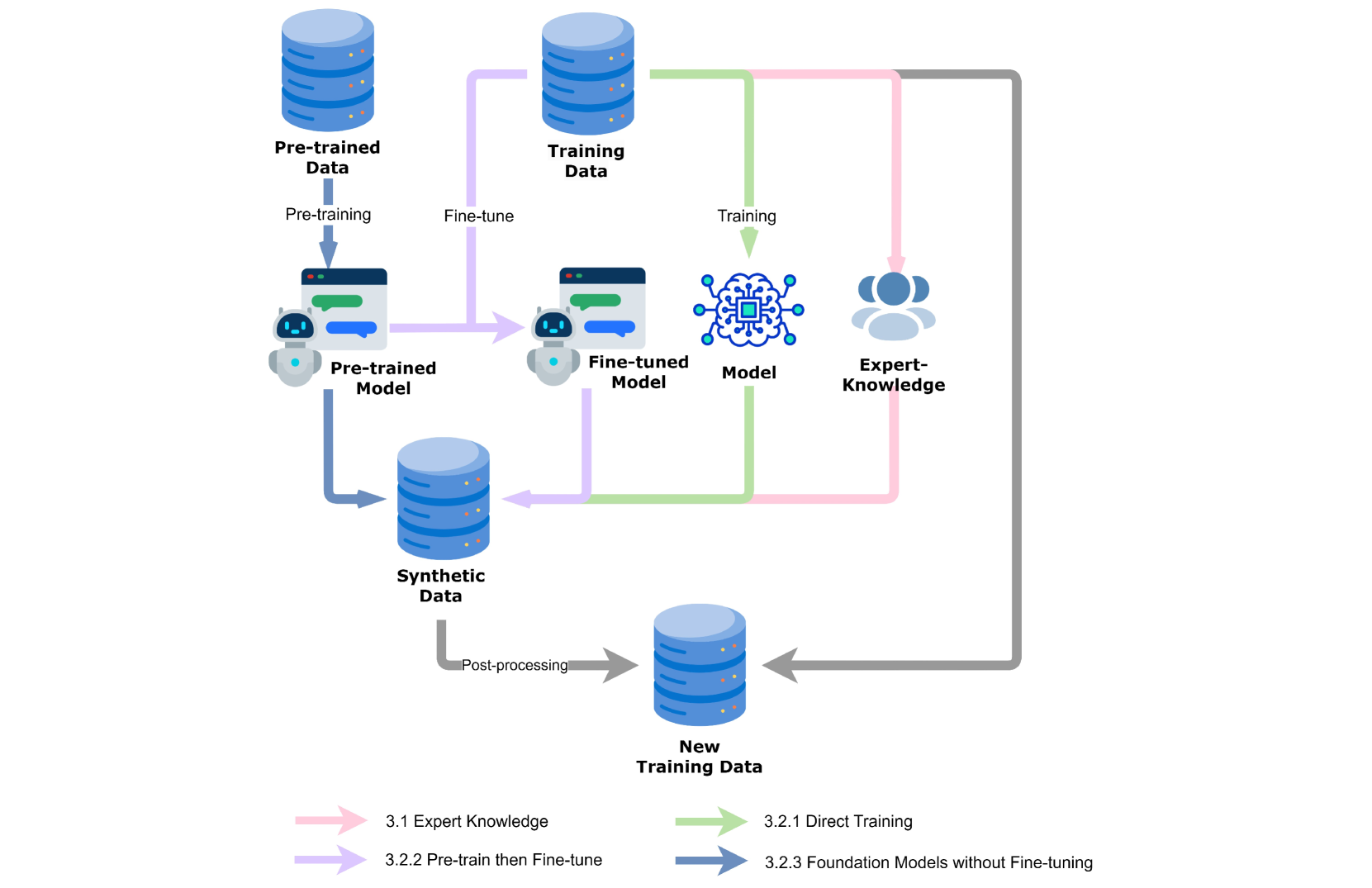
This paper provides a detailed survey of synthetic data techniques. We first discuss the expected goals of using synthetic data in data augmentation, which can be divided into four parts: 1) Improving Diversity, 2) Data Balancing, 3) Addressing Domain Shift, and 4) Resolving Edge Cases. Synthesizing data are closely related to the prevailing machine learning techniques at the time, therefore, we summarize the domain of synthetic data techniques into four categories: 1) Expert-knowledge, 2) Direct Training, 3) Pre-train then Fine-tune, and 4) Foundation Models without Fine-tuning. Next, we categorize the goals of synthetic data filtering into four types for discussion: 1) Basic Quality, 2) Label Consistency, and 3) Data Distribution. In section 5 of this paper, we also discuss the future directions of synthetic data and state three direction that we believe is important: 1) focus more on quality, 2) the evaluation of synthetic data, and 3) multi-model data augmentation.
Read more7/8/2024

0
Best Practices and Lessons Learned on Synthetic Data for Language Models
Ruibo Liu, Jerry Wei, Fangyu Liu, Chenglei Si, Yanzhe Zhang, Jinmeng Rao, Steven Zheng, Daiyi Peng, Diyi Yang, Denny Zhou, Andrew M. Dai
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
Read more8/13/2024

0
Exploring the Impact of Synthetic Data for Aerial-view Human Detection
Hyungtae Lee, Yan Zhang, Yi-Ting Shen, Heesung Kwon, Shuvra S. Bhattacharyya
Aerial-view human detection has a large demand for large-scale data to capture more diverse human appearances compared to ground-view human detection. Therefore, synthetic data can be a good resource to expand data, but the domain gap with real-world data is the biggest obstacle to its use in training. As a common solution to deal with the domain gap, the sim2real transformation is used, and its quality is affected by three factors: i) the real data serving as a reference when calculating the domain gap, ii) the synthetic data chosen to avoid the transformation quality degradation, and iii) the synthetic data pool from which the synthetic data is selected. In this paper, we investigate the impact of these factors on maximizing the effectiveness of synthetic data in training in terms of improving learning performance and acquiring domain generalization ability--two main benefits expected of using synthetic data. As an evaluation metric for the second benefit, we introduce a method for measuring the distribution gap between two datasets, which is derived as the normalized sum of the Mahalanobis distances of all test data. As a result, we have discovered several important findings that have never been investigated or have been used previously without accurate understanding. We expect that these findings can break the current trend of either naively using or being hesitant to use synthetic data in machine learning due to the lack of understanding, leading to more appropriate use in future research.
Read more5/28/2024

0
Curating Grounded Synthetic Data with Global Perspectives for Equitable A
Elin Tornquist, Robert Alexander Caulk
The development of robust AI models relies heavily on the quality and variety of training data available. In fields where data scarcity is prevalent, synthetic data generation offers a vital solution. In this paper, we introduce a novel approach to creating synthetic datasets, grounded in real-world diversity and enriched through strategic diversification. We synthesize data using a comprehensive collection of news articles spanning 12 languages and originating from 125 countries, to ensure a breadth of linguistic and cultural representations. Through enforced topic diversification, translation, and summarization, the resulting dataset accurately mirrors real-world complexities and addresses the issue of underrepresentation in traditional datasets. This methodology, applied initially to Named Entity Recognition (NER), serves as a model for numerous AI disciplines where data diversification is critical for generalizability. Preliminary results demonstrate substantial improvements in performance on traditional NER benchmarks, by up to 7.3%, highlighting the effectiveness of our synthetic data in mimicking the rich, varied nuances of global data sources. This paper outlines the strategies employed for synthesizing diverse datasets and provides such a curated dataset for NER.
Read more6/19/2024