Best Practices and Lessons Learned on Synthetic Data for Language Models

0

Sign in to get full access
Overview
- The paper discusses best practices and lessons learned in using synthetic data for training language models.
- It covers topics such as the reasoning behind using synthetic data, techniques for generating and incorporating it, and potential pitfalls to avoid.
- The paper aims to provide guidance for researchers and practitioners working with synthetic data in the field of natural language processing.
Plain English Explanation
Synthetic data is artificial information that is computer-generated, rather than coming from real-world sources. Researchers are increasingly using synthetic data to train language models, which are AI systems that can understand and generate human-like text.
The paper explores the benefits and challenges of incorporating synthetic data into language model training. One key reason to use synthetic data is that it can help fill gaps in real-world datasets, which may be limited or biased. Generating synthetic satellite imagery with deep learning is an example of how synthetic data can be useful.
However, the paper also cautions that synthetic data must be used carefully. For instance, if the synthetic data is not representative of real-world language, it could actually degrade the model's performance. The paper discusses techniques like iterative retraining of generative models to help ensure the synthetic data is high-quality.
Overall, the paper aims to provide guidance on best practices for researchers looking to leverage synthetic data to improve their language models, while avoiding potential pitfalls.
Technical Explanation
The paper examines the use of synthetic data in training language models, a common approach in natural language processing (NLP) research. One key motivation for using synthetic data is to address the limitations of real-world datasets, which may be biased, incomplete, or difficult to obtain. Experiments on how bad synthetic data can be for training provide insight into the potential trade-offs.
The paper discusses various techniques for generating and incorporating synthetic data, such as using deep learning to create synthetic satellite imagery that can supplement real-world datasets. It also explores potential pitfalls, such as the risk of the synthetic data diverging too far from real-world language patterns, which could undermine the model's performance.
To mitigate these risks, the paper recommends strategies like iterative retraining of generative models to ensure the synthetic data remains representative and high-quality. It also discusses the importance of carefully evaluating the synthetic data's impact on model performance, rather than simply assuming more data is better.
Critical Analysis
The paper provides a comprehensive overview of the current state of research on using synthetic data for language models, highlighting both the potential benefits and the challenges that researchers must navigate.
One limitation noted in the paper is the difficulty of ensuring the synthetic data is truly representative of real-world language patterns. While techniques like iterative retraining can help, there is always a risk of the synthetic data diverging from reality in ways that could undermine the model's performance. Investigations into the usefulness of synthetic images for transfer learning suggest this is a common issue that must be carefully managed.
Additionally, the paper does not delve deeply into the ethical considerations of using synthetic data, such as the potential for amplifying biases or creating "fake" language that could be used for malicious purposes. As the use of synthetic data becomes more widespread, it will be important for the research community to grapple with these larger societal implications.
Overall, the paper provides a valuable resource for researchers working with synthetic data in NLP, but there is still room for further exploration and refinement of best practices in this rapidly evolving field.
Conclusion
This paper offers a comprehensive look at the use of synthetic data in training language models, providing both practical guidance and critical analysis. It highlights the potential benefits of using synthetic data to address limitations in real-world datasets, as well as the importance of carefully managing the quality and representativeness of the synthetic data to avoid degrading model performance.
The insights and recommendations presented in this paper can serve as a valuable resource for researchers and practitioners working to leverage synthetic data to advance the field of natural language processing. By following the best practices outlined in the paper and remaining vigilant about potential pitfalls, the NLP community can continue to harness the power of synthetic data to drive innovation and improve the capabilities of language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Best Practices and Lessons Learned on Synthetic Data for Language Models
Ruibo Liu, Jerry Wei, Fangyu Liu, Chenglei Si, Yanzhe Zhang, Jinmeng Rao, Steven Zheng, Daiyi Peng, Diyi Yang, Denny Zhou, Andrew M. Dai
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
Read more8/13/2024

0
Unveiling the Flaws: Exploring Imperfections in Synthetic Data and Mitigation Strategies for Large Language Models
Jie Chen, Yupeng Zhang, Bingning Wang, Wayne Xin Zhao, Ji-Rong Wen, Weipeng Chen
Synthetic data has been proposed as a solution to address the issue of high-quality data scarcity in the training of large language models (LLMs). Studies have shown that synthetic data can effectively improve the performance of LLMs on downstream benchmarks. However, despite its potential benefits, our analysis suggests that there may be inherent flaws in synthetic data. The uniform format of synthetic data can lead to pattern overfitting and cause significant shifts in the output distribution, thereby reducing the model's instruction-following capabilities. Our work delves into these specific flaws associated with question-answer (Q-A) pairs, a prevalent type of synthetic data, and presents a method based on unlearning techniques to mitigate these flaws. The empirical results demonstrate the effectiveness of our approach, which can reverse the instruction-following issues caused by pattern overfitting without compromising performance on benchmarks at relatively low cost. Our work has yielded key insights into the effective use of synthetic data, aiming to promote more robust and efficient LLM training.
Read more6/19/2024

0
Curating Grounded Synthetic Data with Global Perspectives for Equitable A
Elin Tornquist, Robert Alexander Caulk
The development of robust AI models relies heavily on the quality and variety of training data available. In fields where data scarcity is prevalent, synthetic data generation offers a vital solution. In this paper, we introduce a novel approach to creating synthetic datasets, grounded in real-world diversity and enriched through strategic diversification. We synthesize data using a comprehensive collection of news articles spanning 12 languages and originating from 125 countries, to ensure a breadth of linguistic and cultural representations. Through enforced topic diversification, translation, and summarization, the resulting dataset accurately mirrors real-world complexities and addresses the issue of underrepresentation in traditional datasets. This methodology, applied initially to Named Entity Recognition (NER), serves as a model for numerous AI disciplines where data diversification is critical for generalizability. Preliminary results demonstrate substantial improvements in performance on traditional NER benchmarks, by up to 7.3%, highlighting the effectiveness of our synthetic data in mimicking the rich, varied nuances of global data sources. This paper outlines the strategies employed for synthesizing diverse datasets and provides such a curated dataset for NER.
Read more6/19/2024
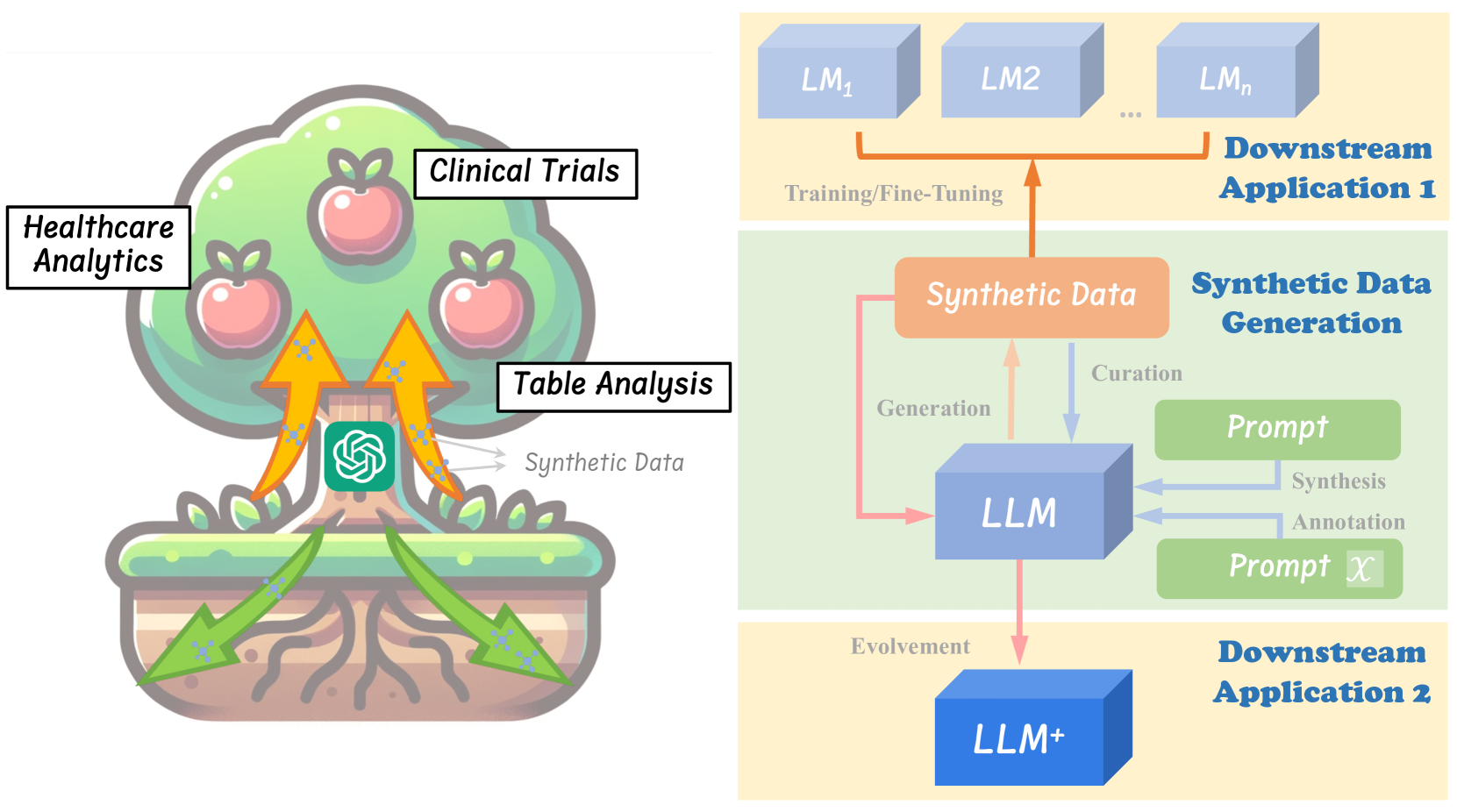
0
On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, Haobo Wang
Within the evolving landscape of deep learning, the dilemma of data quantity and quality has been a long-standing problem. The recent advent of Large Language Models (LLMs) offers a data-centric solution to alleviate the limitations of real-world data with synthetic data generation. However, current investigations into this field lack a unified framework and mostly stay on the surface. Therefore, this paper provides an organization of relevant studies based on a generic workflow of synthetic data generation. By doing so, we highlight the gaps within existing research and outline prospective avenues for future study. This work aims to shepherd the academic and industrial communities towards deeper, more methodical inquiries into the capabilities and applications of LLMs-driven synthetic data generation.
Read more6/24/2024