A Survey of Deep Learning Audio Generation Methods

0
🤿
Sign in to get full access
Overview
- This paper provides a comprehensive review of common deep learning techniques used for audio generation.
- It covers three main areas: audio representations, deep learning architectures, and evaluation metrics.
- The goal is to give novice readers and beginners a solid understanding of the current state-of-the-art in audio generation methods.
Plain English Explanation
This paper takes an in-depth look at the techniques used in deep learning for creating artificial audio. It starts by explaining the different ways audio can be represented, from the basic waveform to more complex frequency-based representations that mimic how humans hear sound.
The main focus of the paper is on explaining several key deep learning architectures that are commonly used for audio generation. These include autoencoders, generative adversarial networks, normalizing flows, transformer networks, and diffusion models. The paper explains how each of these architectures works and the kinds of audio generation tasks they are well-suited for.
Finally, the paper discusses several common metrics used to evaluate the quality and realism of generated audio. This can help researchers and developers understand how to measure the performance of their audio generation models.
Overall, this paper provides a comprehensive overview of the current state of audio generation using deep learning. It covers the fundamental concepts and the latest advancements in the field, making it a valuable resource for both beginners and experienced practitioners.
Technical Explanation
The paper begins by explaining the different ways audio can be represented, starting with the basic waveform and then moving to the frequency domain. This includes a discussion of the attributes of human hearing and more recent developments in audio representations.
The core of the paper is an in-depth explanation of several deep learning architectures used for audio generation. This includes:
-
Autoencoders: These neural networks learn a compressed representation of audio data, which can then be used to generate new audio samples. Autoencoders are particularly useful for tasks like audio synthesis and transformation.
-
Generative Adversarial Networks (GANs): GANs pit two neural networks against each other - a generator that produces fake audio samples and a discriminator that tries to identify them as fake. This adversarial training process allows GANs to generate highly realistic audio. GANs have been used for tasks like speech synthesis and music generation.
-
Normalizing Flows: These models learn a invertible transformation that maps the target audio distribution to a simpler, more tractable distribution. This allows for efficient sampling and generation of new audio samples. Normalizing flows have been used for tasks like audio synthesis and voice conversion.
-
Transformer Networks: Transformer architectures, originally developed for natural language processing, have also been applied to audio generation. These models leverage self-attention mechanisms to capture long-range dependencies in audio data. Transformer networks have shown promising results for tasks like music generation and sound synthesis.
-
Diffusion Models: Diffusion models learn to reverse a noising process, starting from pure noise and gradually transforming it into realistic audio samples. These models have demonstrated impressive performance on a variety of audio generation tasks. Diffusion models have been used for applications like speech synthesis and music generation.
The paper also discusses common evaluation metrics used to assess the quality and realism of generated audio, such as perceptual similarity, naturalness, and diversity.
Critical Analysis
The paper provides a comprehensive and well-structured overview of the current state-of-the-art in deep learning-based audio generation. It covers the key technical aspects in a clear and accessible way, making it a valuable resource for both beginners and experienced researchers in the field.
One potential limitation of the paper is that it does not delve too deeply into the specific architectural details and mathematical formulations of the various deep learning techniques. While this helps maintain a high-level, easy-to-understand perspective, readers interested in a more technical, in-depth understanding may need to refer to the original research papers.
Additionally, the paper does not extensively discuss the practical challenges and limitations of applying these techniques in real-world scenarios. For example, it does not address issues like data scarcity, model robustness, or the computational resources required for training large-scale audio generation models.
Further research could explore these practical considerations, as well as investigate the potential societal implications and ethical considerations around the use of highly realistic, AI-generated audio. Audio anti-spoofing and detection is an important area that deserves more attention as these technologies become more advanced.
Overall, this paper serves as an excellent starting point for understanding the state-of-the-art in deep learning-based audio generation. It provides a solid foundation for readers to explore the field further and critically evaluate the current research and its potential future directions.
Conclusion
This paper offers a comprehensive review of the common deep learning techniques used for audio generation, covering three main aspects: audio representations, deep learning architectures, and evaluation metrics.
By explaining the fundamental concepts and the latest advancements in the field, the paper provides a valuable resource for both novice readers and experienced practitioners interested in the current state-of-the-art in audio generation using deep learning. The clear and accessible explanations, coupled with the relevant references to specific research papers, make this paper a valuable addition to the literature on this topic.
As the field of deep learning-based audio generation continues to evolve, further research will be needed to address practical challenges, explore ethical considerations, and push the boundaries of what is possible in terms of generating high-quality, realistic audio content. This paper lays a solid foundation for understanding the current landscape and serves as a starting point for future explorations in this exciting and rapidly advancing field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
A Survey of Deep Learning Audio Generation Methods
Matej Bov{z}i'c, Marko Horvat
This article presents a review of typical techniques used in three distinct aspects of deep learning model development for audio generation. In the first part of the article, we provide an explanation of audio representations, beginning with the fundamental audio waveform. We then progress to the frequency domain, with an emphasis on the attributes of human hearing, and finally introduce a relatively recent development. The main part of the article focuses on explaining basic and extended deep learning architecture variants, along with their practical applications in the field of audio generation. The following architectures are addressed: 1) Autoencoders 2) Generative adversarial networks 3) Normalizing flows 4) Transformer networks 5) Diffusion models. Lastly, we will examine four distinct evaluation metrics that are commonly employed in audio generation. This article aims to offer novice readers and beginners in the field a comprehensive understanding of the current state of the art in audio generation methods as well as relevant studies that can be explored for future research.
Read more6/4/2024
🛸
0
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, Mark D. Plumbley
Although audio generation shares commonalities across different types of audio, such as speech, music, and sound effects, designing models for each type requires careful consideration of specific objectives and biases that can significantly differ from those of other types. To bring us closer to a unified perspective of audio generation, this paper proposes a framework that utilizes the same learning method for speech, music, and sound effect generation. Our framework introduces a general representation of audio, called language of audio (LOA). Any audio can be translated into LOA based on AudioMAE, a self-supervised pre-trained representation learning model. In the generation process, we translate any modalities into LOA by using a GPT-2 model, and we perform self-supervised audio generation learning with a latent diffusion model conditioned on LOA. The proposed framework naturally brings advantages such as in-context learning abilities and reusable self-supervised pretrained AudioMAE and latent diffusion models. Experiments on the major benchmarks of text-to-audio, text-to-music, and text-to-speech demonstrate state-of-the-art or competitive performance against previous approaches. Our code, pretrained model, and demo are available at https://audioldm.github.io/audioldm2.
Read more5/14/2024
🔎
0
Towards generalizing deep-audio fake detection networks
Konstantin Gasenzer (High Performance Computing and Analytics Lab, Universitat Bonn, Germany), Moritz Wolter (High Performance Computing and Analytics Lab, Universitat Bonn, Germany)
Today's generative neural networks allow the creation of high-quality synthetic speech at scale. While we welcome the creative use of this new technology, we must also recognize the risks. As synthetic speech is abused for monetary and identity theft, we require a broad set of deepfake identification tools. Furthermore, previous work reported a limited ability of deep classifiers to generalize to unseen audio generators. We study the frequency domain fingerprints of current audio generators. Building on top of the discovered frequency footprints, we train excellent lightweight detectors that generalize. We report improved results on the WaveFake dataset and an extended version. To account for the rapid progress in the field, we extend the WaveFake dataset by additionally considering samples drawn from the novel Avocodo and BigVGAN networks. For illustration purposes, the supplementary material contains audio samples of generator artifacts.
Read more4/10/2024
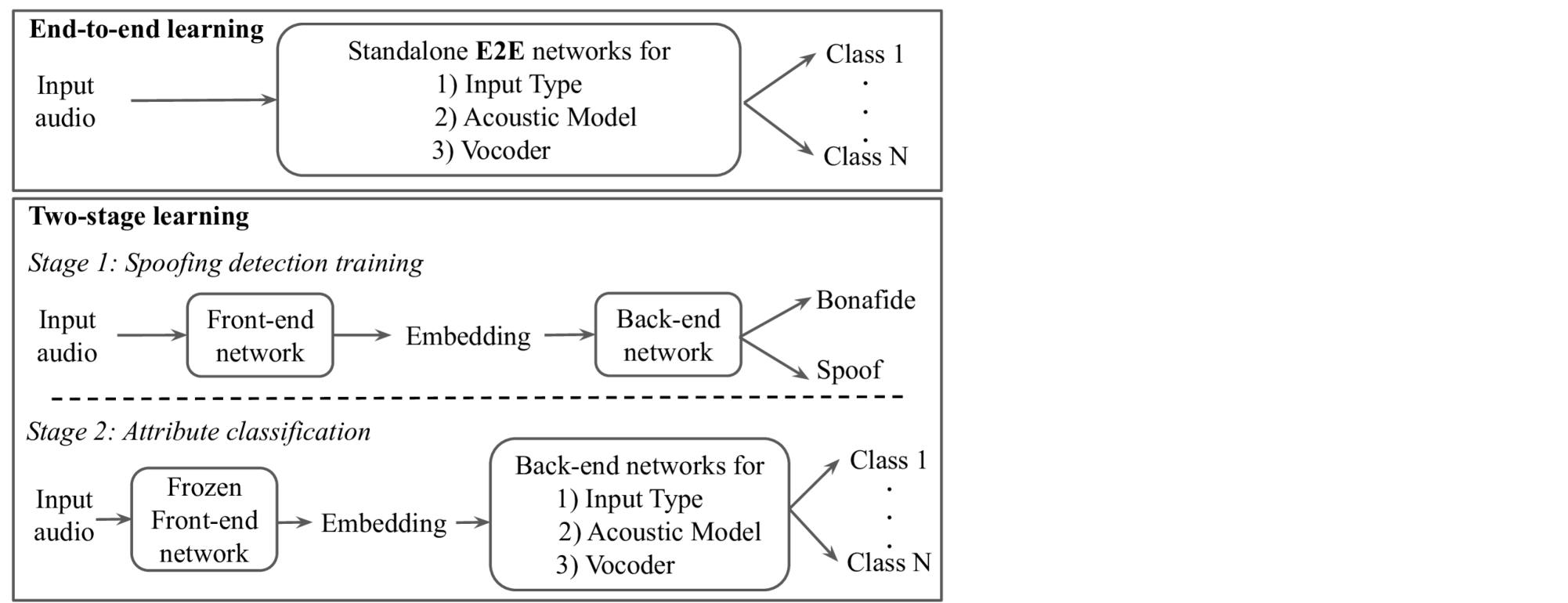
0
Source Tracing of Audio Deepfake Systems
Nicholas Klein, Tianxiang Chen, Hemlata Tak, Ricardo Casal, Elie Khoury
Recent progress in generative AI technology has made audio deepfakes remarkably more realistic. While current research on anti-spoofing systems primarily focuses on assessing whether a given audio sample is fake or genuine, there has been limited attention on discerning the specific techniques to create the audio deepfakes. Algorithms commonly used in audio deepfake generation, like text-to-speech (TTS) and voice conversion (VC), undergo distinct stages including input processing, acoustic modeling, and waveform generation. In this work, we introduce a system designed to classify various spoofing attributes, capturing the distinctive features of individual modules throughout the entire generation pipeline. We evaluate our system on two datasets: the ASVspoof 2019 Logical Access and the Multi-Language Audio Anti-Spoofing Dataset (MLAAD). Results from both experiments demonstrate the robustness of the system to identify the different spoofing attributes of deepfake generation systems.
Read more7/12/2024