Visual Echoes: A Simple Unified Transformer for Audio-Visual Generation
2405.14598
0
0
Abstract
In recent years, with the realistic generation results and a wide range of personalized applications, diffusion-based generative models gain huge attention in both visual and audio generation areas. Compared to the considerable advancements of text2image or text2audio generation, research in audio2visual or visual2audio generation has been relatively slow. The recent audio-visual generation methods usually resort to huge large language model or composable diffusion models. Instead of designing another giant model for audio-visual generation, in this paper we take a step back showing a simple and lightweight generative transformer, which is not fully investigated in multi-modal generation, can achieve excellent results on image2audio generation. The transformer operates in the discrete audio and visual Vector-Quantized GAN space, and is trained in the mask denoising manner. After training, the classifier-free guidance could be deployed off-the-shelf achieving better performance, without any extra training or modification. Since the transformer model is modality symmetrical, it could also be directly deployed for audio2image generation and co-generation. In the experiments, we show that our simple method surpasses recent image2audio generation methods. Generated audio samples can be found at https://docs.google.com/presentation/d/1ZtC0SeblKkut4XJcRaDsSTuCRIXB3ypxmSi7HTY3IyQ/
Create account to get full access
Overview
- This paper presents a simple and unified transformer model called "Visual Echoes" that can generate both audio and visual content.
- The model is designed to be efficient and versatile, allowing for the generation of audio, video, and audio-visual content from a single framework.
- The authors demonstrate the model's capabilities in various tasks, including speech-driven gesture generation, audio-driven image generation, and multi-modal content generation.
Plain English Explanation
The "Visual Echoes" model is a powerful tool that can generate both audio and visual content. Unlike many other models that are specialized for either audio or visual tasks, this one is a "jack-of-all-trades" that can handle both.
The key innovation is the use of a single transformer-based architecture that can be trained to generate a wide range of multi-modal content, from speech-driven gestures to audio-driven images. This makes the model efficient and versatile, as it doesn't require separate models for each task.
The authors show that this unified approach can achieve strong performance across a variety of applications, without sacrificing the quality of the generated content. This could be particularly useful in scenarios where you need to generate both audio and visual elements, such as in video game cutscenes or virtual assistant interactions.
Technical Explanation
The core of the "Visual Echoes" model is a transformer-based architecture that can handle both audio and visual inputs and outputs. The authors use a single encoder-decoder structure, where the encoder processes the input (either audio or visual) and the decoder generates the output (either audio or visual).
To enable this multi-modal capability, the model uses a shared token embedding layer that can represent both audio and visual features. This allows the transformer to learn representations that capture the relationships between audio and visual information, which is crucial for tasks like speech-driven gesture generation or audio-driven image generation.
The authors also introduce a novel training strategy that involves gradually increasing the diversity of the training data, starting with simpler tasks and gradually moving towards more complex multi-modal generation. This helps the model learn robust representations that can handle a wide range of audio-visual scenarios.
Critical Analysis
The "Visual Echoes" model presents an interesting and potentially valuable approach to multi-modal content generation. By using a single unified transformer-based architecture, the authors have demonstrated the model's versatility and efficiency in handling a range of audio-visual tasks.
One potential limitation of the model is that it may not be able to match the performance of specialized models in certain tasks, as it needs to balance the requirements of different modalities. Additionally, the authors mention that the model can be computationally expensive, which could limit its practical deployment in some scenarios.
Further research could explore ways to improve the model's efficiency, potentially through the use of techniques like mixture-of-experts or model distillation. Investigating the model's ability to generalize to new, unseen tasks and domains could also be an interesting area of study.
Conclusion
The "Visual Echoes" model presented in this paper represents an innovative approach to multi-modal content generation. By using a single transformer-based architecture to handle both audio and visual tasks, the model demonstrates impressive versatility and efficiency.
The model's ability to generate high-quality audio, visual, and audio-visual content from a unified framework could have significant implications for a wide range of applications, from virtual assistants to video game development. As the field of multi-modal AI continues to evolve, the "Visual Echoes" model could serve as an important stepping stone towards more integrated and efficient approaches to audio-visual generation and understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Versatile Diffusion Transformer with Mixture of Noise Levels for Audiovisual Generation
Gwanghyun Kim, Alonso Martinez, Yu-Chuan Su, Brendan Jou, Jos'e Lezama, Agrim Gupta, Lijun Yu, Lu Jiang, Aren Jansen, Jacob Walker, Krishna Somandepalli
0
0
Training diffusion models for audiovisual sequences allows for a range of generation tasks by learning conditional distributions of various input-output combinations of the two modalities. Nevertheless, this strategy often requires training a separate model for each task which is expensive. Here, we propose a novel training approach to effectively learn arbitrary conditional distributions in the audiovisual space.Our key contribution lies in how we parameterize the diffusion timestep in the forward diffusion process. Instead of the standard fixed diffusion timestep, we propose applying variable diffusion timesteps across the temporal dimension and across modalities of the inputs. This formulation offers flexibility to introduce variable noise levels for various portions of the input, hence the term mixture of noise levels. We propose a transformer-based audiovisual latent diffusion model and show that it can be trained in a task-agnostic fashion using our approach to enable a variety of audiovisual generation tasks at inference time. Experiments demonstrate the versatility of our method in tackling cross-modal and multimodal interpolation tasks in the audiovisual space. Notably, our proposed approach surpasses baselines in generating temporally and perceptually consistent samples conditioned on the input. Project page: avdit2024.github.io
5/24/2024
🌀
ViT-TTS: Visual Text-to-Speech with Scalable Diffusion Transformer
Huadai Liu, Rongjie Huang, Xuan Lin, Wenqiang Xu, Maozong Zheng, Hong Chen, Jinzheng He, Zhou Zhao
0
0
Text-to-speech(TTS) has undergone remarkable improvements in performance, particularly with the advent of Denoising Diffusion Probabilistic Models (DDPMs). However, the perceived quality of audio depends not solely on its content, pitch, rhythm, and energy, but also on the physical environment. In this work, we propose ViT-TTS, the first visual TTS model with scalable diffusion transformers. ViT-TTS complement the phoneme sequence with the visual information to generate high-perceived audio, opening up new avenues for practical applications of AR and VR to allow a more immersive and realistic audio experience. To mitigate the data scarcity in learning visual acoustic information, we 1) introduce a self-supervised learning framework to enhance both the visual-text encoder and denoiser decoder; 2) leverage the diffusion transformer scalable in terms of parameters and capacity to learn visual scene information. Experimental results demonstrate that ViT-TTS achieves new state-of-the-art results, outperforming cascaded systems and other baselines regardless of the visibility of the scene. With low-resource data (1h, 2h, 5h), ViT-TTS achieves comparative results with rich-resource baselines.~footnote{Audio samples are available at url{https://ViT-TTS.github.io/.}}
4/23/2024

Complex Image-Generative Diffusion Transformer for Audio Denoising
Junhui Li, Pu Wang, Jialu Li, Youshan Zhang
0
0
The audio denoising technique has captured widespread attention in the deep neural network field. Recently, the audio denoising problem has been converted into an image generation task, and deep learning-based approaches have been applied to tackle this problem. However, its performance is still limited, leaving room for further improvement. In order to enhance audio denoising performance, this paper introduces a complex image-generative diffusion transformer that captures more information from the complex Fourier domain. We explore a novel diffusion transformer by integrating the transformer with a diffusion model. Our proposed model demonstrates the scalability of the transformer and expands the receptive field of sparse attention using attention diffusion. Our work is among the first to utilize diffusion transformers to deal with the image generation task for audio denoising. Extensive experiments on two benchmark datasets demonstrate that our proposed model outperforms state-of-the-art methods.
6/14/2024
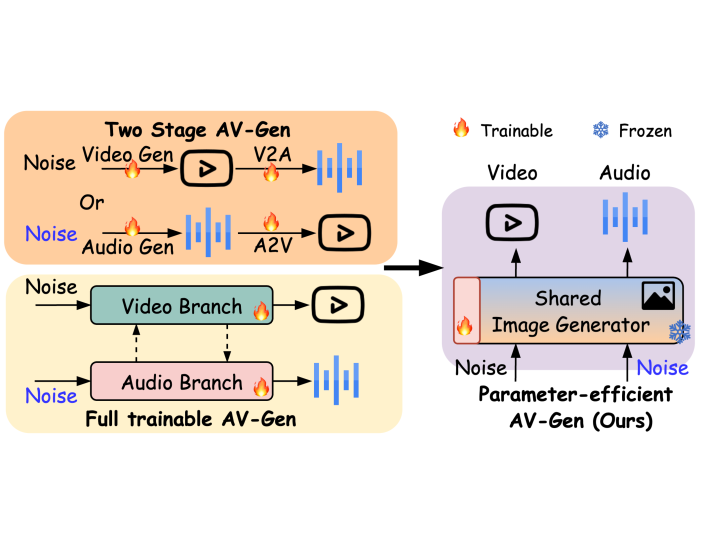
AV-DiT: Efficient Audio-Visual Diffusion Transformer for Joint Audio and Video Generation
Kai Wang, Shijian Deng, Jing Shi, Dimitrios Hatzinakos, Yapeng Tian
0
0
Recent Diffusion Transformers (DiTs) have shown impressive capabilities in generating high-quality single-modality content, including images, videos, and audio. However, it is still under-explored whether the transformer-based diffuser can efficiently denoise the Gaussian noises towards superb multimodal content creation. To bridge this gap, we introduce AV-DiT, a novel and efficient audio-visual diffusion transformer designed to generate high-quality, realistic videos with both visual and audio tracks. To minimize model complexity and computational costs, AV-DiT utilizes a shared DiT backbone pre-trained on image-only data, with only lightweight, newly inserted adapters being trainable. This shared backbone facilitates both audio and video generation. Specifically, the video branch incorporates a trainable temporal attention layer into a frozen pre-trained DiT block for temporal consistency. Additionally, a small number of trainable parameters adapt the image-based DiT block for audio generation. An extra shared DiT block, equipped with lightweight parameters, facilitates feature interaction between audio and visual modalities, ensuring alignment. Extensive experiments on the AIST++ and Landscape datasets demonstrate that AV-DiT achieves state-of-the-art performance in joint audio-visual generation with significantly fewer tunable parameters. Furthermore, our results highlight that a single shared image generative backbone with modality-specific adaptations is sufficient for constructing a joint audio-video generator. Our source code and pre-trained models will be released.
6/13/2024