A Survey of Multimodal Composite Editing and Retrieval

0
Sign in to get full access
Overview
- Multimodal composite retrieval combines and analyzes multiple data types, such as images and text, to find relevant content.
- Multimodal fusion integrates data from different modalities to enable more comprehensive understanding and better decision-making.
- This survey examines the latest developments in multimodal composite editing and retrieval.
Plain English Explanation
Multimodal composite retrieval is a way of searching for and finding relevant information by using a combination of different data types, like images and text. For example, you might search for images of dogs and have the system also return related text descriptions or captions.
Multimodal fusion is the process of taking this mixed data and combining it in a way that gives you a more complete and meaningful understanding. Rather than just looking at the images or text separately, multimodal fusion allows the system to consider how the different pieces of information work together.
This paper provides an overview of the latest research and developments in this area of multimodal composite editing and retrieval. It looks at how these techniques are being used and improved to help people find the information they're looking for more effectively.
Technical Explanation
The paper discusses the concept of multimodal composite retrieval, which involves combining and analyzing multiple types of data, such as images and text, to retrieve relevant content. This is contrasted with multimodal fusion, which integrates data from different modalities to enable more comprehensive understanding and better decision-making.
The survey examines recent advancements in these areas, covering topics like multimodal pretraining and adaptation for generation and recommendation, compressible and searchable AI-native multimodal retrieval, and multimodal learning with limited data. It provides an overview of the current state of the art and highlights promising directions for future research.
Critical Analysis
The paper offers a comprehensive survey of the field, covering a range of relevant topics and the latest developments. However, it does not delve deeply into the specific technical details or evaluation of the various approaches.
Additionally, the paper does not extensively discuss the potential challenges or limitations of multimodal composite editing and retrieval, such as the complexity of data integration, the need for large and diverse datasets, or the potential for biases and errors in the underlying models.
Further research could explore these areas in more depth, as well as investigate the real-world applications and potential societal impacts of these technologies.
Conclusion
This survey provides a valuable overview of the current state of multimodal composite editing and retrieval, highlighting the importance of integrating and analyzing data from multiple modalities to enhance information retrieval and decision-making. The insights presented in the paper can inform future research and development in this rapidly evolving field, with the potential to drive advancements in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Survey of Multimodal Composite Editing and Retrieval
Suyan Li, Fuxiang Huang, Lei Zhang
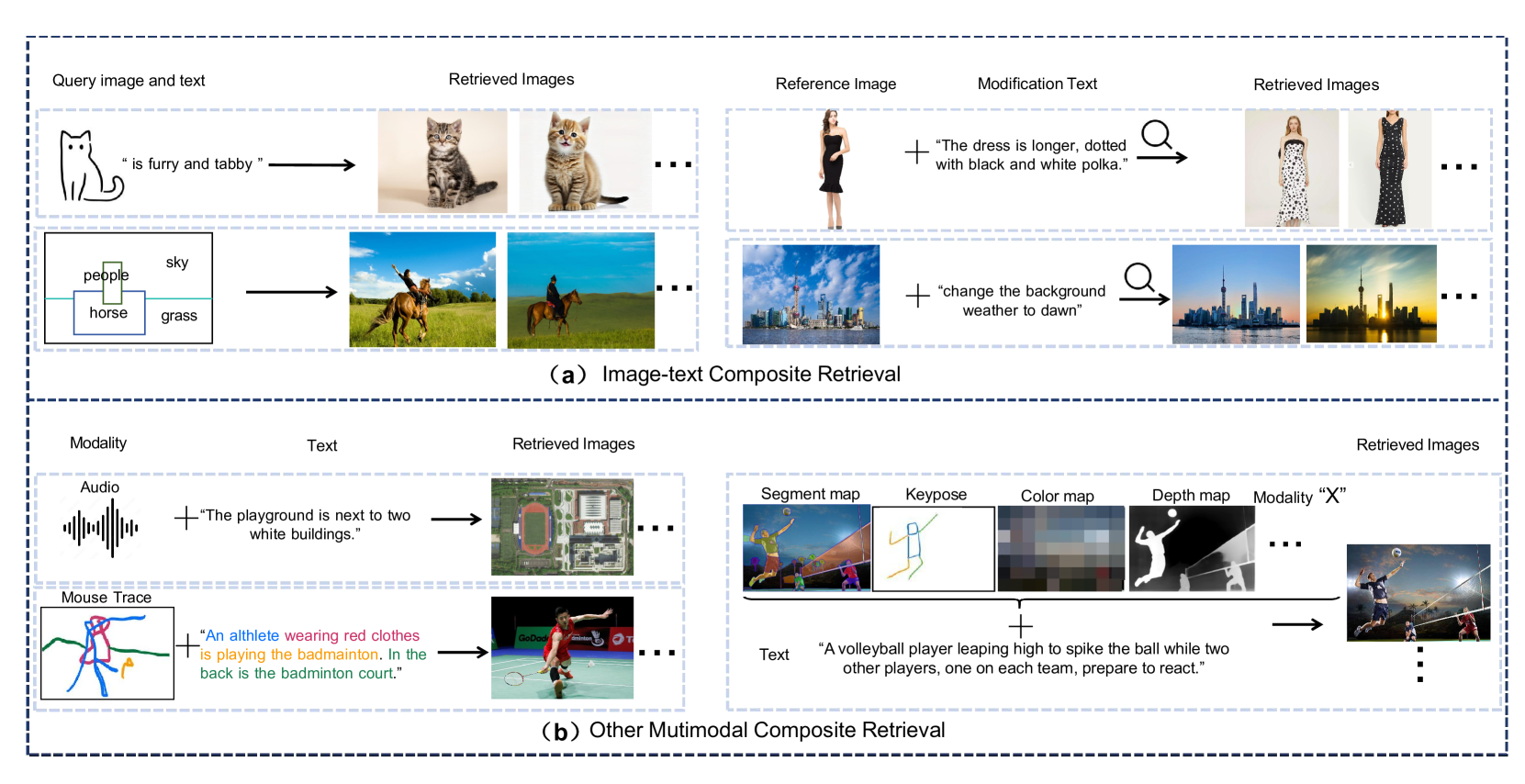
In the real world, where information is abundant and diverse across different modalities, understanding and utilizing various data types to improve retrieval systems is a key focus of research. Multimodal composite retrieval integrates diverse modalities such as text, image and audio, etc. to provide more accurate, personalized, and contextually relevant results. To facilitate a deeper understanding of this promising direction, this survey explores multimodal composite editing and retrieval in depth, covering image-text composite editing, image-text composite retrieval, and other multimodal composite retrieval. In this survey, we systematically organize the application scenarios, methods, benchmarks, experiments, and future directions. Multimodal learning is a hot topic in large model era, and have also witnessed some surveys in multimodal learning and vision-language models with transformers published in the PAMI journal. To the best of our knowledge, this survey is the first comprehensive review of the literature on multimodal composite retrieval, which is a timely complement of multimodal fusion to existing reviews. To help readers' quickly track this field, we build the project page for this survey, which can be found at https://github.com/fuxianghuang1/Multimodal-Composite-Editing-and-Retrieval.
Read more9/12/2024
0
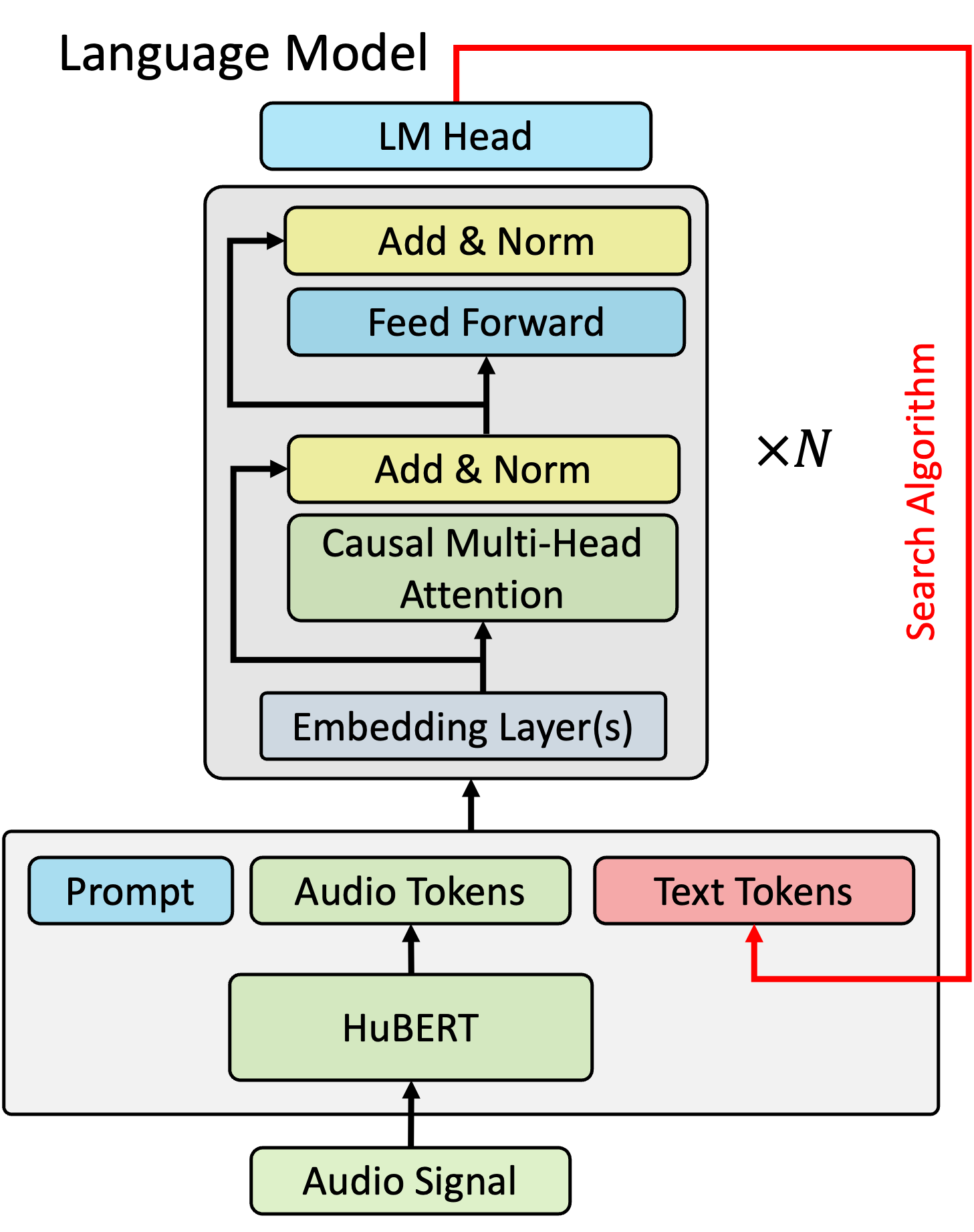
Multi-Modal Retrieval For Large Language Model Based Speech Recognition
Jari Kolehmainen, Aditya Gourav, Prashanth Gurunath Shivakumar, Yile Gu, Ankur Gandhe, Ariya Rastrow, Grant Strimel, Ivan Bulyko
Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.
Read more6/17/2024
0
Multimodal Pretraining, Adaptation, and Generation for Recommendation: A Survey
Qijiong Liu, Jieming Zhu, Yanting Yang, Quanyu Dai, Zhaocheng Du, Xiao-Ming Wu, Zhou Zhao, Rui Zhang, Zhenhua Dong
Personalized recommendation serves as a ubiquitous channel for users to discover information tailored to their interests. However, traditional recommendation models primarily rely on unique IDs and categorical features for user-item matching, potentially overlooking the nuanced essence of raw item contents across multiple modalities such as text, image, audio, and video. This underutilization of multimodal data poses a limitation to recommender systems, especially in multimedia services like news, music, and short-video platforms. The recent advancements in large multimodal models offer new opportunities and challenges in developing content-aware recommender systems. This survey seeks to provide a comprehensive exploration of the latest advancements and future trajectories in multimodal pretraining, adaptation, and generation techniques, as well as their applications in enhancing recommender systems. Furthermore, we discuss current open challenges and opportunities for future research in this dynamic domain. We believe that this survey, alongside the curated resources, will provide valuable insights to inspire further advancements in this evolving landscape.
Read more7/4/2024
0
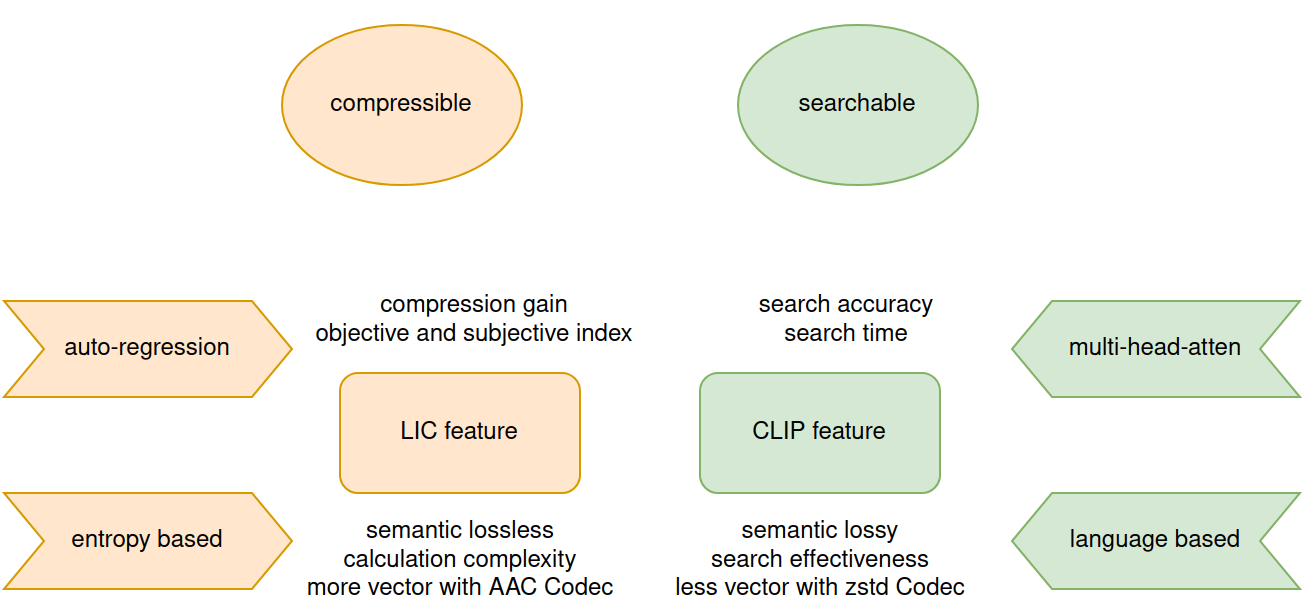
Compressible and Searchable: AI-native Multi-Modal Retrieval System with Learned Image Compression
Jixiang Luo
The burgeoning volume of digital content across diverse modalities necessitates efficient storage and retrieval methods. Conventional approaches struggle to cope with the escalating complexity and scale of multimedia data. In this paper, we proposed framework addresses this challenge by fusing AI-native multi-modal search capabilities with neural image compression. First we analyze the intricate relationship between compressibility and searchability, recognizing the pivotal role each plays in the efficiency of storage and retrieval systems. Through the usage of simple adapter is to bridge the feature of Learned Image Compression(LIC) and Contrastive Language-Image Pretraining(CLIP) while retaining semantic fidelity and retrieval of multi-modal data. Experimental evaluations on Kodak datasets demonstrate the efficacy of our approach, showcasing significant enhancements in compression efficiency and search accuracy compared to existing methodologies. Our work marks a significant advancement towards scalable and efficient multi-modal search systems in the era of big data.
Read more4/17/2024