Compressible and Searchable: AI-native Multi-Modal Retrieval System with Learned Image Compression
2404.10234
0
0
Abstract
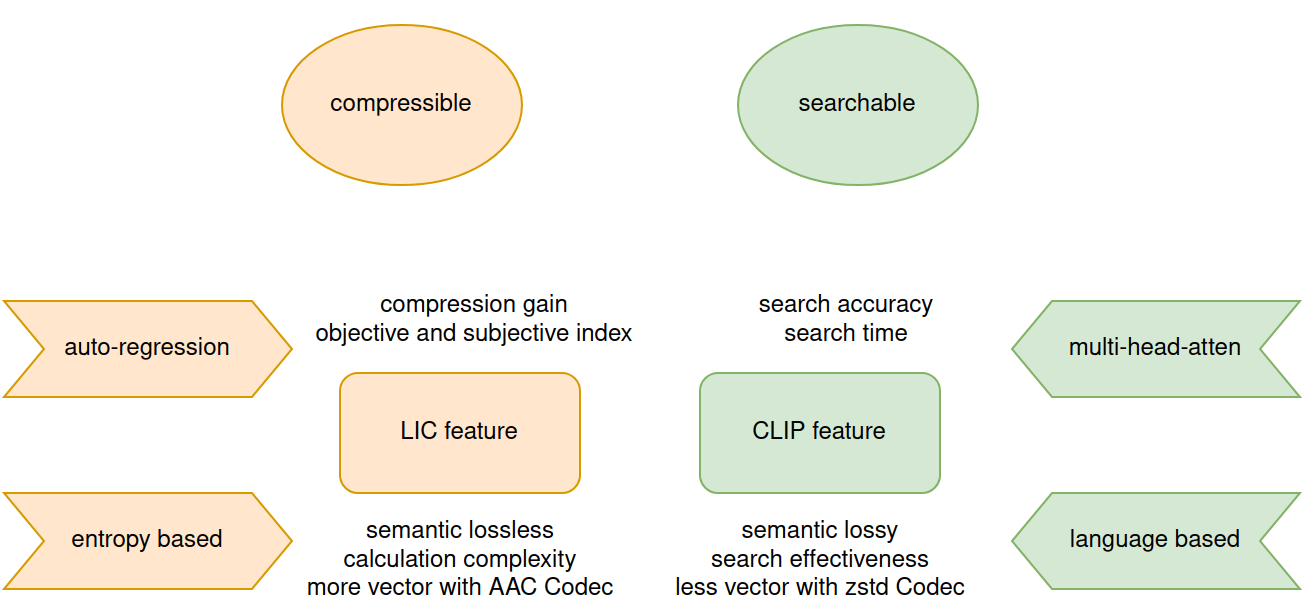
The burgeoning volume of digital content across diverse modalities necessitates efficient storage and retrieval methods. Conventional approaches struggle to cope with the escalating complexity and scale of multimedia data. In this paper, we proposed framework addresses this challenge by fusing AI-native multi-modal search capabilities with neural image compression. First we analyze the intricate relationship between compressibility and searchability, recognizing the pivotal role each plays in the efficiency of storage and retrieval systems. Through the usage of simple adapter is to bridge the feature of Learned Image Compression(LIC) and Contrastive Language-Image Pretraining(CLIP) while retaining semantic fidelity and retrieval of multi-modal data. Experimental evaluations on Kodak datasets demonstrate the efficacy of our approach, showcasing significant enhancements in compression efficiency and search accuracy compared to existing methodologies. Our work marks a significant advancement towards scalable and efficient multi-modal search systems in the era of big data.
Get summaries of the top AI research delivered straight to your inbox:
Overview
• This paper presents a novel AI-based multi-modal retrieval system that combines learned image compression with a powerful contrastive learning approach to achieve highly efficient and accurate retrieval of images and text.
• The key innovations include a novel architecture that integrates a learned image compression module with a CLIP-like multi-modal encoder, as well as a multi-modal fusion technique to effectively combine visual and textual information.
Plain English Explanation
The researchers have developed an AI system that can quickly and accurately find relevant images and text, even when working with large amounts of data. The system uses a novel approach that combines two key technologies:
-
Learned image compression: This allows the system to store images in a more compact form, taking up less storage space while still preserving the key visual information.
-
Contrastive learning: This is a technique that trains the AI to recognize patterns and relationships between images and text, enabling it to make smart connections and retrieve the most relevant results.
By integrating these two innovations, the system can efficiently process and search through vast amounts of multi-modal (image and text) data, making it a powerful tool for applications like visual search, content recommendation, and knowledge discovery.
Technical Explanation
The paper introduces a compressible and searchable AI-native multi-modal retrieval system that leverages learned image compression and contrastive learning techniques. The system consists of three key components:
- A learned image compression module that can efficiently encode visual information while preserving important details.
- A CLIP-like multi-modal encoder that jointly processes text and compressed image representations to learn powerful cross-modal embeddings.
- A multi-modal fusion mechanism that combines the visual and textual features to enable effective retrieval and ranking.
The researchers demonstrate the effectiveness of their approach through extensive experiments, showing significant improvements in retrieval accuracy and efficiency compared to existing methods.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated system that addresses the important challenge of efficient multi-modal retrieval. The authors acknowledge the potential limitations of their approach, such as the need for further research to improve the generalization capabilities of the learned image compression module.
One area that could benefit from further exploration is the interpretability and explainability of the system's decision-making process. Understanding how the AI makes connections between visual and textual information could lead to improved transparency and trust in the system's outputs.
Additionally, the paper does not explore the potential environmental and economic impacts of deploying such a system at scale, which is an important consideration for real-world applications.
Conclusion
The researchers have developed a highly innovative AI-native multi-modal retrieval system that combines learned image compression and contrastive learning techniques to enable efficient and accurate retrieval of images and text. This work represents a significant advancement in the field of multi-modal information processing and has the potential to drive numerous applications, from visual search to content recommendation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Large Language Model Informed Patent Image Retrieval
Hao-Cheng Lo, Jung-Mei Chu, Jieh Hsiang, Chun-Chieh Cho
0
0
In patent prosecution, image-based retrieval systems for identifying similarities between current patent images and prior art are pivotal to ensure the novelty and non-obviousness of patent applications. Despite their growing popularity in recent years, existing attempts, while effective at recognizing images within the same patent, fail to deliver practical value due to their limited generalizability in retrieving relevant prior art. Moreover, this task inherently involves the challenges posed by the abstract visual features of patent images, the skewed distribution of image classifications, and the semantic information of image descriptions. Therefore, we propose a language-informed, distribution-aware multimodal approach to patent image feature learning, which enriches the semantic understanding of patent image by integrating Large Language Models and improves the performance of underrepresented classes with our proposed distribution-aware contrastive losses. Extensive experiments on DeepPatent2 dataset show that our proposed method achieves state-of-the-art or comparable performance in image-based patent retrieval with mAP +53.3%, Recall@10 +41.8%, and MRR@10 +51.9%. Furthermore, through an in-depth user analysis, we explore our model in aiding patent professionals in their image retrieval efforts, highlighting the model's real-world applicability and effectiveness.
5/1/2024
🖼️
Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
Hongyi Zhu, Jia-Hong Huang, Stevan Rudinac, Evangelos Kanoulas
0
0
Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.
4/30/2024

Multi-modal Learnable Queries for Image Aesthetics Assessment
Zhiwei Xiong, Yunfan Zhang, Zhiqi Shen, Peiran Ren, Han Yu
0
0
Image aesthetics assessment (IAA) is attracting wide interest with the prevalence of social media. The problem is challenging due to its subjective and ambiguous nature. Instead of directly extracting aesthetic features solely from the image, user comments associated with an image could potentially provide complementary knowledge that is useful for IAA. With existing large-scale pre-trained models demonstrating strong capabilities in extracting high-quality transferable visual and textual features, learnable queries are shown to be effective in extracting useful features from the pre-trained visual features. Therefore, in this paper, we propose MMLQ, which utilizes multi-modal learnable queries to extract aesthetics-related features from multi-modal pre-trained features. Extensive experimental results demonstrate that MMLQ achieves new state-of-the-art performance on multi-modal IAA, beating previous methods by 7.7% and 8.3% in terms of SRCC and PLCC, respectively.
5/3/2024
CFIR: Fast and Effective Long-Text To Image Retrieval for Large Corpora
Zijun Long, Xuri Ge, Richard Mccreadie, Joemon Jose
0
0
Text-to-image retrieval aims to find the relevant images based on a text query, which is important in various use-cases, such as digital libraries, e-commerce, and multimedia databases. Although Multimodal Large Language Models (MLLMs) demonstrate state-of-the-art performance, they exhibit limitations in handling large-scale, diverse, and ambiguous real-world needs of retrieval, due to the computation cost and the injective embeddings they produce. This paper presents a two-stage Coarse-to-Fine Index-shared Retrieval (CFIR) framework, designed for fast and effective large-scale long-text to image retrieval. The first stage, Entity-based Ranking (ER), adapts to long-text query ambiguity by employing a multiple-queries-to-multiple-targets paradigm, facilitating candidate filtering for the next stage. The second stage, Summary-based Re-ranking (SR), refines these rankings using summarized queries. We also propose a specialized Decoupling-BEiT-3 encoder, optimized for handling ambiguous user needs and both stages, which also enhances computational efficiency through vector-based similarity inference. Evaluation on the AToMiC dataset reveals that CFIR surpasses existing MLLMs by up to 11.06% in Recall@1000, while reducing training and retrieval times by 68.75% and 99.79%, respectively. We will release our code to facilitate future research at https://github.com/longkukuhi/CFIR.
4/4/2024