A Survey on Recent Random Walk-based Methods for Embedding Knowledge Graphs
2406.07402
0
0
👁️
Abstract
Machine learning, deep learning, and NLP methods on knowledge graphs are present in different fields and have important roles in various domains from self-driving cars to friend recommendations on social media platforms. However, to apply these methods to knowledge graphs, the data usually needs to be in an acceptable size and format. In fact, knowledge graphs normally have high dimensions and therefore we need to transform them to a low-dimensional vector space. An embedding is a low-dimensional space into which you can translate high dimensional vectors in a way that intrinsic features of the input data are preserved. In this review, we first explain knowledge graphs and their embedding and then review some of the random walk-based embedding methods that have been developed recently.
Create account to get full access
Overview
- Machine learning, deep learning, and natural language processing (NLP) methods are used to work with knowledge graphs, which are important for applications like self-driving cars and social media recommendations
- However, knowledge graphs are often high-dimensional, so they need to be transformed into a low-dimensional vector space for these methods to be applied effectively
- This review explains knowledge graphs and their embeddings, then discusses some recent random walk-based embedding methods
Plain English Explanation
Knowledge graphs are like databases that store information about things and how they're related. They're used in all kinds of tech, from self-driving cars to friend recommendations on social media. Machine learning, deep learning, and natural language processing can be really helpful for working with knowledge graphs.
But knowledge graphs are often really complex, with tons of information and connections. To use those fancy AI methods, we need to simplify the knowledge graphs into a lower-dimensional form, kind of like compressing a big file. That's where embeddings come in - they let us translate the high-dimensional knowledge graphs into a more manageable low-dimensional vector space, while still preserving the important details.
This review first explains what knowledge graphs are and how embeddings work. Then it dives into some recent methods that use random walks to create those helpful low-dimensional embeddings of knowledge graphs.
Technical Explanation
Knowledge graphs are structured databases that store information about entities (like people, places, or things) and the relationships between them. They're often high-dimensional, with complex webs of interconnected data. To apply machine learning, deep learning, and NLP methods to knowledge graphs, researchers need to transform them into a lower-dimensional vector space, preserving the key intrinsic features.
This is where embeddings come in. An embedding is a way to translate high-dimensional data into a low-dimensional representation, like compressing a large file. By creating these low-dimensional embeddings of knowledge graphs, researchers can then use powerful AI techniques like subgraph2vec, EmpowerKG, and GuideWalk to analyze and make use of the knowledge graph data.
The review covers several recently developed random walk-based methods for creating knowledge graph embeddings. These approaches use random walks through the graph structure to capture the relationships between entities in a way that can be effectively represented in a lower-dimensional space.
Critical Analysis
The research covered in this review highlights the importance of knowledge graph embeddings for enabling the application of advanced machine learning and AI techniques. By transforming high-dimensional knowledge graphs into a lower-dimensional vector space, these methods make it possible to leverage the rich information contained in knowledge graphs for a variety of real-world applications.
However, the review also acknowledges some potential limitations and areas for further research. For example, the performance of these embedding methods may be sensitive to the size and structure of the knowledge graph, and additional work may be needed to adapt them for use with smaller or more specialized knowledge graphs. There is also an opportunity to explore ways of incorporating additional types of data, such as textual information, to further enhance the quality and usefulness of the learned embeddings.
Overall, this review provides a valuable overview of the current state of knowledge graph embedding research and its applications. By encouraging readers to think critically about the strengths, weaknesses, and future directions of this work, it helps to advance the broader understanding and responsible development of these important AI techniques.
Conclusion
This review explains how machine learning, deep learning, and NLP methods can be applied to knowledge graphs, which are important for a wide range of technology applications. However, knowledge graphs are often high-dimensional, so they need to be transformed into a lower-dimensional vector space, or embedding, for these methods to be used effectively.
The review covers the basics of knowledge graphs and embeddings, then dives into several recent random walk-based methods for creating knowledge graph embeddings. These techniques enable the rich information in knowledge graphs to be leveraged using powerful AI tools, with potential applications ranging from self-driving cars to friend recommendations on social media.
While this research shows a lot of promise, the review also highlights areas for further exploration, such as adapting the methods for smaller or more specialized knowledge graphs and incorporating additional data sources. By summarizing the key ideas and encouraging critical analysis, this review helps advance the state of knowledge graph embedding research and its real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Survey on Embedding Models for Knowledge Graph and its Applications
Manita Pote
0
0
Knowledge Graph (KG) is a graph based data structure to represent facts of the world where nodes represent real world entities or abstract concept and edges represent relation between the entities. Graph as representation for knowledge has several drawbacks like data sparsity, computational complexity and manual feature engineering. Knowledge Graph embedding tackles the drawback by representing entities and relation in low dimensional vector space by capturing the semantic relation between them. There are different KG embedding models. Here, we discuss translation based and neural network based embedding models which differ based on semantic property, scoring function and architecture they use. Further, we discuss application of KG in some domains that use deep learning models and leverage social media data.
4/16/2024
🔍
Subgraph2vec: A random walk-based algorithm for embedding knowledge graphs
Elika Bozorgi, Saber Soleimani, Sakher Khalil Alqaiidi, Hamid Reza Arabnia, Krzysztof Kochut
0
0
Graph is an important data representation which occurs naturally in the real world applications cite{goyal2018graph}. Therefore, analyzing graphs provides users with better insights in different areas such as anomaly detection cite{ma2021comprehensive}, decision making cite{fan2023graph}, clustering cite{tsitsulin2023graph}, classification cite{wang2021mixup} and etc. However, most of these methods require high levels of computational time and space. We can use other ways like embedding to reduce these costs. Knowledge graph (KG) embedding is a technique that aims to achieve the vector representation of a KG. It represents entities and relations of a KG in a low-dimensional space while maintaining the semantic meanings of them. There are different methods for embedding graphs including random walk-based methods such as node2vec, metapath2vec and regpattern2vec. However, most of these methods bias the walks based on a rigid pattern usually hard-coded in the algorithm. In this work, we introduce textit{subgraph2vec} for embedding KGs where walks are run inside a user-defined subgraph. We use this embedding for link prediction and prove our method has better performance in most cases in comparison with the previous ones.
5/6/2024
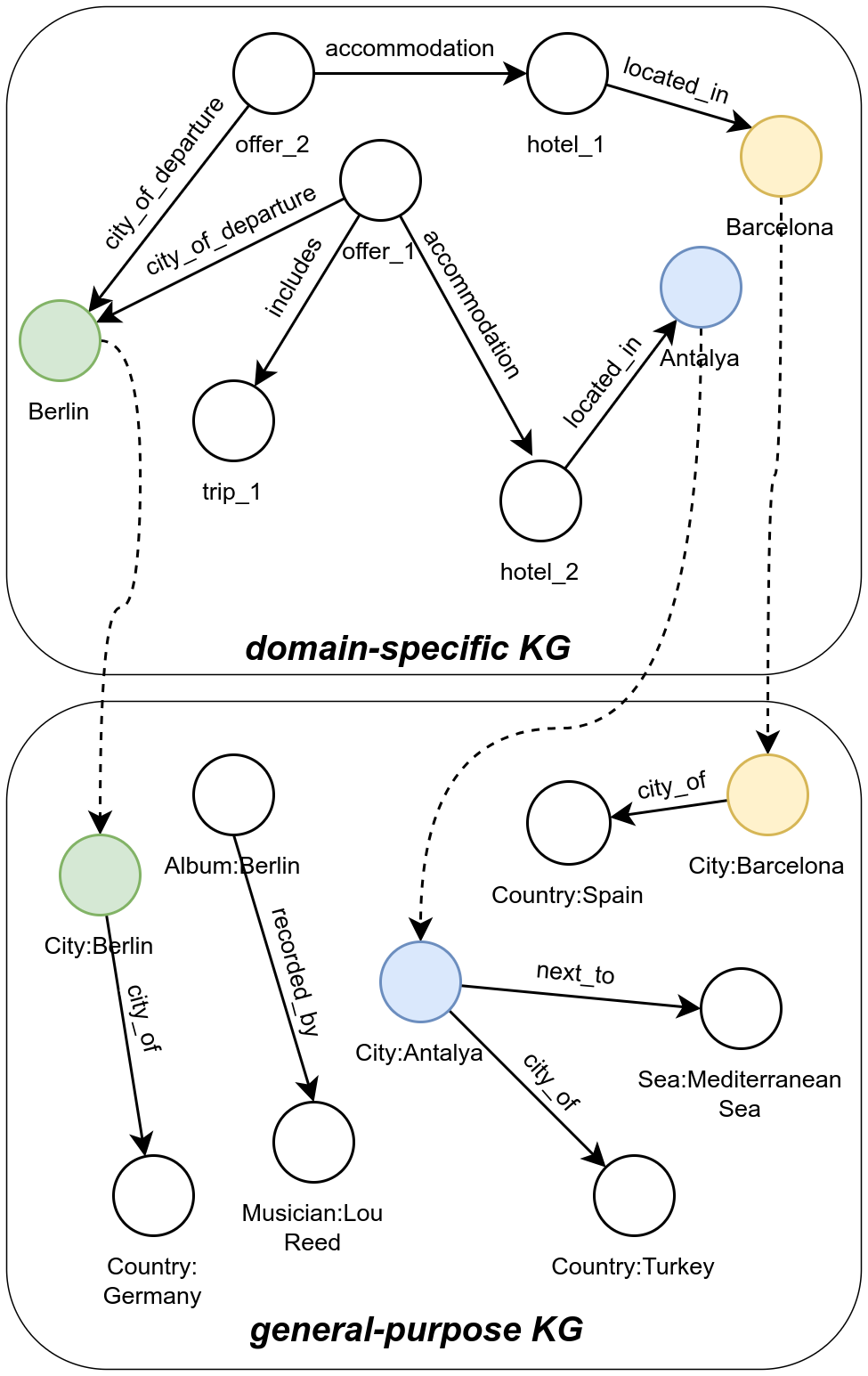
Empowering Small-Scale Knowledge Graphs: A Strategy of Leveraging General-Purpose Knowledge Graphs for Enriched Embeddings
Albert Sawczyn, Jakub Binkowski, Piotr Bielak, Tomasz Kajdanowicz
0
0
Knowledge-intensive tasks pose a significant challenge for Machine Learning (ML) techniques. Commonly adopted methods, such as Large Language Models (LLMs), often exhibit limitations when applied to such tasks. Nevertheless, there have been notable endeavours to mitigate these challenges, with a significant emphasis on augmenting LLMs through Knowledge Graphs (KGs). While KGs provide many advantages for representing knowledge, their development costs can deter extensive research and applications. Addressing this limitation, we introduce a framework for enriching embeddings of small-scale domain-specific Knowledge Graphs with well-established general-purpose KGs. Adopting our method, a modest domain-specific KG can benefit from a performance boost in downstream tasks when linked to a substantial general-purpose KG. Experimental evaluations demonstrate a notable enhancement, with up to a 44% increase observed in the Hits@10 metric. This relatively unexplored research direction can catalyze more frequent incorporation of KGs in knowledge-intensive tasks, resulting in more robust, reliable ML implementations, which hallucinates less than prevalent LLM solutions. Keywords: knowledge graph, knowledge graph completion, entity alignment, representation learning, machine learning
5/20/2024
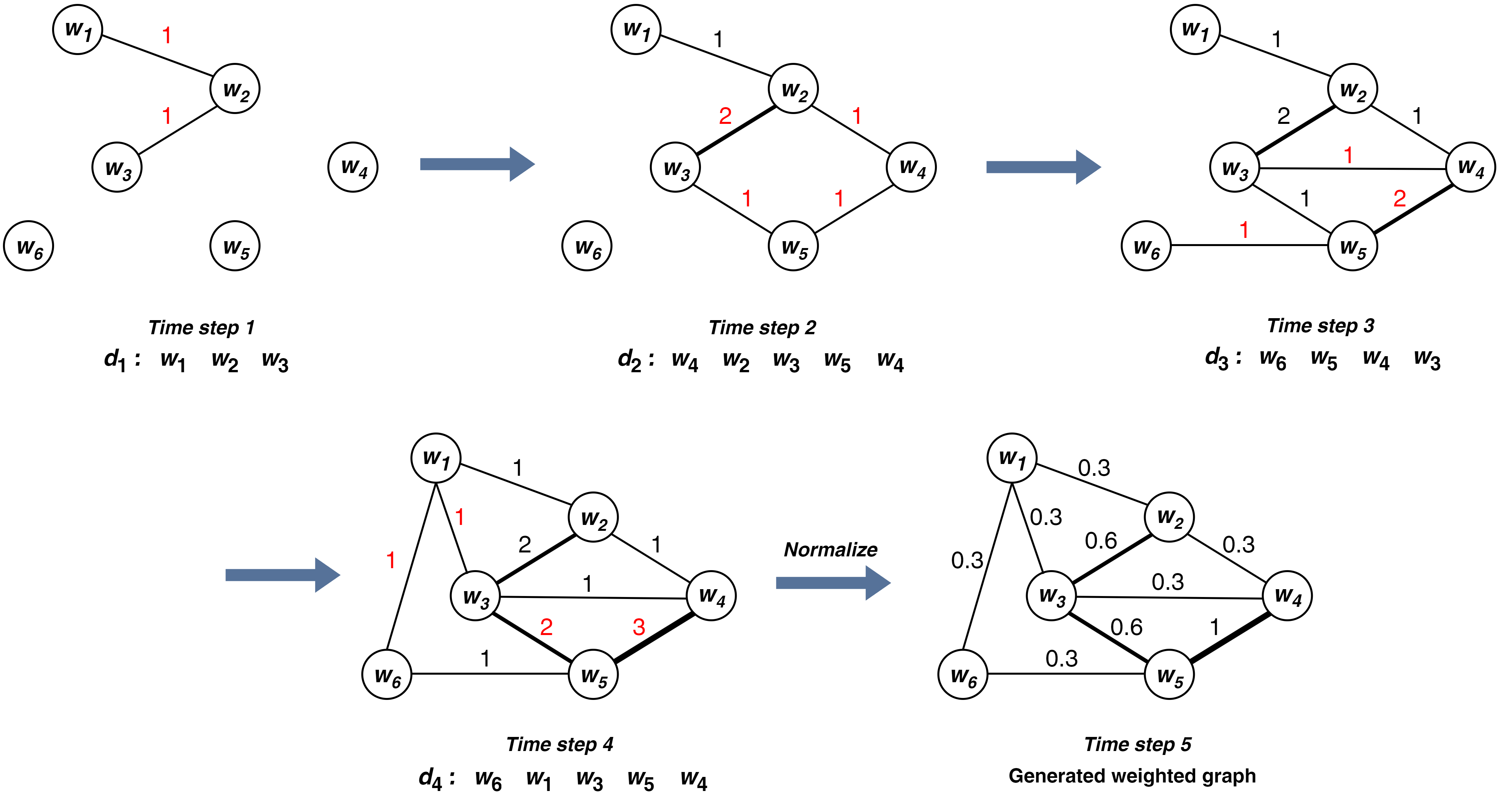
GuideWalk -- Heterogeneous Data Fusion for Enhanced Learning -- A Multiclass Document Classification Case
Sarmad N. Mohammed, Semra Gunduc{c}
0
0
One of the prime problems of computer science and machine learning is to extract information efficiently from large-scale, heterogeneous data. Text data, with its syntax, semantics, and even hidden information content, possesses an exceptional place among the data types in concern. The processing of the text data requires embedding, a method of translating the content of the text to numeric vectors. A correct embedding algorithm is the starting point for obtaining the full information content of the text data. In this work, a new embedding method based on the graph structure of the meaningful sentences is proposed. The design of the algorithm aims to construct an embedding vector that constitutes syntactic and semantic elements as well as the hidden content of the text data. The success of the proposed embedding method is tested in classification problems. Among the wide range of application areas, text classification is the best laboratory for embedding methods; the classification power of the method can be tested using dimensional reduction without any further processing. Furthermore, the method can be compared with different embedding algorithms and machine learning methods. The proposed method is tested with real-world data sets and eight well-known and successful embedding algorithms. The proposed embedding method shows significantly better classification for binary and multiclass datasets compared to well-known algorithms.
5/1/2024