Subgraph2vec: A random walk-based algorithm for embedding knowledge graphs

0
🔍
Sign in to get full access
Overview
- Graphs are a common way to represent data in the real world, and analyzing them can provide valuable insights in areas like anomaly detection, decision-making, clustering, and classification.
- However, many graph analysis methods require high computational resources, so researchers are exploring ways to reduce these costs, such as using graph embedding techniques.
- Knowledge graph (KG) embedding is a technique that represents entities and relations in a KG as low-dimensional vectors while preserving their semantic meanings.
- Existing KG embedding methods often use rigid, hard-coded walk patterns, which can limit their performance.
Plain English Explanation
Graphs are a way to represent information that is commonly found in the real world. For example, a social network is a graph where each person is a node, and the connections between them are edges. Analyzing these graphs can help us understand things like suspicious activity, make better decisions, group similar people or objects together, and classify them into different categories.
However, the computations required to analyze graphs can be very complex and time-consuming. To make this easier, researchers have developed techniques to "embed" graphs - that is, to represent the important information in a graph using a more compact set of numbers. This allows graph analysis to be done more efficiently.
One popular type of graph embedding is knowledge graph (KG) embedding. A knowledge graph is a way of representing information about the world, where each piece of information (like a fact or a relationship) is stored as a node and an edge. KG embedding tries to capture the meaning of these nodes and edges using a set of numbers.
Most existing KG embedding methods use a fixed set of rules to decide how to walk through the graph and extract the important information. This can sometimes limit how well the embeddings capture the true structure and meaning of the graph. In this work, the researchers introduce a new method called "subgraph2vec" that allows the user to define the specific parts of the graph to focus on, which can lead to better performance in some cases.
Technical Explanation
The key ideas in this paper are:
-
Graph Embedding: The paper focuses on knowledge graph (KG) embedding, which aims to represent the entities and relations in a KG as low-dimensional vectors while preserving their semantic meanings.
-
Subgraph2vec: The authors propose a new KG embedding method called "subgraph2vec" that allows the user to define the specific subgraph to focus on during the embedding process. This is in contrast to many existing methods that use rigid, hard-coded walk patterns.
-
Evaluation: The authors evaluate subgraph2vec on the task of link prediction, where the goal is to predict missing links in a KG. They show that subgraph2vec outperforms several baseline methods in most cases.
The technical details are as follows:
- The subgraph2vec method first extracts random walks from a user-defined subgraph of the KG.
- It then uses these walks to train a neural network that learns vector representations of the entities and relations.
- This allows the embedding to focus on the specific aspects of the KG that are most relevant to the user's needs, rather than relying on a one-size-fits-all approach.
- The authors demonstrate the effectiveness of subgraph2vec through extensive experiments on several real-world KG datasets.
Critical Analysis
The subgraph2vec method proposed in this paper provides a flexible way to learn KG embeddings by allowing the user to focus on specific parts of the graph. This is a valuable contribution, as it can help improve the performance of downstream tasks like link prediction and classification.
However, the paper does not extensively explore the limitations of the subgraph2vec approach. For example, it's unclear how the choice of subgraph affects the quality of the embeddings, or how to best define the subgraph for a given task. Additionally, the paper does not compare subgraph2vec to more recent graph embedding methods that may have different strengths and weaknesses.
Overall, the subgraph2vec method is a promising contribution to the field of graph embedding, but further research is needed to fully understand its capabilities and limitations.
Conclusion
This paper introduces a new knowledge graph embedding method called subgraph2vec that allows users to focus on specific parts of the graph during the embedding process. By doing so, subgraph2vec can outperform existing methods in tasks like link prediction, providing a more flexible and effective way to represent and analyze knowledge graphs. While the paper demonstrates the potential of this approach, further research is needed to fully understand its strengths, weaknesses, and broader implications for the field of graph analysis and representation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Subgraph2vec: A random walk-based algorithm for embedding knowledge graphs
Elika Bozorgi, Saber Soleimani, Sakher Khalil Alqaiidi, Hamid Reza Arabnia, Krzysztof Kochut
Graph is an important data representation which occurs naturally in the real world applications cite{goyal2018graph}. Therefore, analyzing graphs provides users with better insights in different areas such as anomaly detection cite{ma2021comprehensive}, decision making cite{fan2023graph}, clustering cite{tsitsulin2023graph}, classification cite{wang2021mixup} and etc. However, most of these methods require high levels of computational time and space. We can use other ways like embedding to reduce these costs. Knowledge graph (KG) embedding is a technique that aims to achieve the vector representation of a KG. It represents entities and relations of a KG in a low-dimensional space while maintaining the semantic meanings of them. There are different methods for embedding graphs including random walk-based methods such as node2vec, metapath2vec and regpattern2vec. However, most of these methods bias the walks based on a rigid pattern usually hard-coded in the algorithm. In this work, we introduce textit{subgraph2vec} for embedding KGs where walks are run inside a user-defined subgraph. We use this embedding for link prediction and prove our method has better performance in most cases in comparison with the previous ones.
Read more5/6/2024
👁️
0
A Survey on Recent Random Walk-based Methods for Embedding Knowledge Graphs
Elika Bozorgi, Sakher Khalil Alqaiidi, Afsaneh Shams, Hamid Reza Arabnia, Krzysztof Kochut
Machine learning, deep learning, and NLP methods on knowledge graphs are present in different fields and have important roles in various domains from self-driving cars to friend recommendations on social media platforms. However, to apply these methods to knowledge graphs, the data usually needs to be in an acceptable size and format. In fact, knowledge graphs normally have high dimensions and therefore we need to transform them to a low-dimensional vector space. An embedding is a low-dimensional space into which you can translate high dimensional vectors in a way that intrinsic features of the input data are preserved. In this review, we first explain knowledge graphs and their embedding and then review some of the random walk-based embedding methods that have been developed recently.
Read more9/25/2024

0
An Ad-hoc graph node vector embedding algorithm for general knowledge graphs using Kinetica-Graph
B. Kaan Karamete, Eli Glaser
This paper discusses how to generate general graph node embeddings from knowledge graph representations. The embedded space is composed of a number of sub-features to mimic both local affinity and remote structural relevance. These sub-feature dimensions are defined by several indicators that we speculate to catch nodal similarities, such as hop-based topological patterns, the number of overlapping labels, the transitional probabilities (markov-chain probabilities), and the cluster indices computed by our recursive spectral bisection (RSB) algorithm. These measures are flattened over the one dimensional vector space into their respective sub-component ranges such that the entire set of vector similarity functions could be used for finding similar nodes. The error is defined by the sum of pairwise square differences across a randomly selected sample of graph nodes between the assumed embeddings and the ground truth estimates as our novel loss function. The ground truth is estimated to be a combination of pairwise Jaccard similarity and the number of overlapping labels. Finally, we demonstrate a multi-variate stochastic gradient descent (SGD) algorithm to compute the weighing factors among sub-vector spaces to minimize the average error using a random sampling logic.
Read more7/24/2024
0
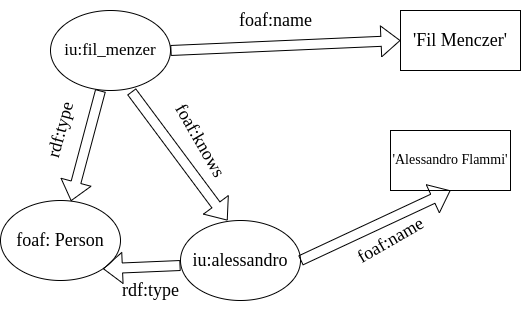
Survey on Embedding Models for Knowledge Graph and its Applications
Manita Pote
Knowledge Graph (KG) is a graph based data structure to represent facts of the world where nodes represent real world entities or abstract concept and edges represent relation between the entities. Graph as representation for knowledge has several drawbacks like data sparsity, computational complexity and manual feature engineering. Knowledge Graph embedding tackles the drawback by representing entities and relation in low dimensional vector space by capturing the semantic relation between them. There are different KG embedding models. Here, we discuss translation based and neural network based embedding models which differ based on semantic property, scoring function and architecture they use. Further, we discuss application of KG in some domains that use deep learning models and leverage social media data.
Read more4/16/2024