Survey on Embedding Models for Knowledge Graph and its Applications
2404.09167
0
0
Abstract
Knowledge Graph (KG) is a graph based data structure to represent facts of the world where nodes represent real world entities or abstract concept and edges represent relation between the entities. Graph as representation for knowledge has several drawbacks like data sparsity, computational complexity and manual feature engineering. Knowledge Graph embedding tackles the drawback by representing entities and relation in low dimensional vector space by capturing the semantic relation between them. There are different KG embedding models. Here, we discuss translation based and neural network based embedding models which differ based on semantic property, scoring function and architecture they use. Further, we discuss application of KG in some domains that use deep learning models and leverage social media data.
Create account to get full access
Overview
- This paper provides a comprehensive survey on embedding models for knowledge graphs and their various applications.
- Knowledge graphs are large-scale structured datasets that represent real-world entities and their relationships.
- Embedding models are used to encode knowledge graphs into low-dimensional vector representations, enabling efficient processing and integration with deep learning techniques.
- The survey covers the latest advancements in knowledge graph embedding models and their use in various domains, including enterprise use cases combining knowledge graphs and natural language processing, recommender systems, and hierarchical knowledge graph augmentation.
Plain English Explanation
Knowledge graphs are like giant digital maps of the world, where each point on the map represents a real-world thing, like a person, place, or concept, and the lines connecting the points show how these things are related to each other. These knowledge graphs can be incredibly useful for all sorts of applications, like building automatic knowledge graphs for languages like Bangla, or combining knowledge graphs with natural language processing to better understand and use the information they contain.
The problem is that these knowledge graphs can get really big and complex, making them hard to work with using regular computer programs. That's where embedding models come in. Embedding models are a way of taking all the information in a knowledge graph and squeezing it down into a much simpler, easier-to-use form, kind of like compressing a big image file into a smaller one. This allows us to use powerful machine learning techniques, like deep learning, to do all sorts of useful things with the knowledge graph data, like improving recommendations in recommender systems or automatically expanding and refining the knowledge graph itself.
This survey paper explores the latest advancements in these knowledge graph embedding models and the many ways they're being used to unlock the potential of these massive, complex datasets. It's a really important topic for anyone working on knowledge graph construction, natural language processing, or other AI applications that rely on structured knowledge.
Technical Explanation
The paper provides a comprehensive survey of the latest advancements in embedding models for knowledge graphs. Knowledge graphs are large-scale, structured datasets that represent real-world entities and their relationships. Embedding models are used to encode the information in these knowledge graphs into low-dimensional vector representations, which can then be efficiently processed using deep learning techniques.
The survey covers a wide range of knowledge graph embedding models, including TransE, DistMult, ComplEx, and RotatE, among others. These models use different strategies to learn the vector representations of entities and relations in the knowledge graph, optimizing for various objectives such as link prediction and relation extraction.
The paper also explores the application of these embedding models in diverse domains, such as recommender systems, natural language processing, and knowledge graph construction and refinement. For example, the embedding representations can be used to enhance the performance of recommender systems by incorporating knowledge about user preferences and item relationships. Similarly, the embeddings can be integrated with language models to improve tasks like question answering and knowledge graph augmentation.
The survey also discusses the challenges and limitations of current knowledge graph embedding models, such as the need for large amounts of training data, the difficulty in capturing complex relation types, and the potential for bias and noise in the underlying knowledge graphs. The authors highlight areas for future research, including the development of more expressive and efficient embedding models, the integration of knowledge graphs with other data sources, and the application of these techniques to real-world, cross-domain knowledge graph construction.
Critical Analysis
The survey provides a comprehensive and insightful overview of the current state of knowledge graph embedding models and their applications. The authors do an excellent job of highlighting the key advancements in the field, as well as the remaining challenges and areas for future research.
One potential limitation of the survey is that it does not go into depth on the specific technical details and mathematical formulations of the various embedding models. While this is understandable given the broad scope of the paper, some readers may have preferred a more technical analysis of the model architectures and training procedures.
Additionally, the survey could have benefited from a more critical examination of the potential biases and shortcomings of knowledge graph embedding models. For example, the authors could have discussed the impact of incomplete or noisy knowledge graphs on the performance of these models, or the potential for these models to amplify existing societal biases present in the training data.
Despite these minor limitations, the survey is a valuable resource for researchers and practitioners working in the field of knowledge graph representation and integration. The authors' clear and accessible writing style, coupled with the extensive coverage of the latest advancements, make this paper a must-read for anyone interested in the role of knowledge graphs in modern AI and machine learning applications.
Conclusion
This survey paper provides a comprehensive overview of the latest advancements in embedding models for knowledge graphs and their diverse applications. Knowledge graphs are increasingly becoming a crucial component of AI and machine learning systems, as they offer a structured representation of real-world entities and their relationships.
The paper explores how embedding models can be used to efficiently encode the information in these large-scale knowledge graphs, enabling the integration of deep learning techniques for tasks such as recommender systems, natural language processing, and knowledge graph construction and refinement. The authors also highlight the challenges and limitations of current embedding models, as well as promising avenues for future research.
Overall, this survey is a valuable resource for researchers and practitioners working at the intersection of knowledge representation and deep learning. By providing a comprehensive and accessible overview of the field, the authors have made a significant contribution to the ongoing efforts to unlock the potential of knowledge graphs in a wide range of AI-powered applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
A Survey on Recent Random Walk-based Methods for Embedding Knowledge Graphs
Elika Bozorgi, Sakher Khalil Alqaiidi, Afsaneh Shams, Hamid Reza Arabnia, Krzysztof Kochut
0
0
Machine learning, deep learning, and NLP methods on knowledge graphs are present in different fields and have important roles in various domains from self-driving cars to friend recommendations on social media platforms. However, to apply these methods to knowledge graphs, the data usually needs to be in an acceptable size and format. In fact, knowledge graphs normally have high dimensions and therefore we need to transform them to a low-dimensional vector space. An embedding is a low-dimensional space into which you can translate high dimensional vectors in a way that intrinsic features of the input data are preserved. In this review, we first explain knowledge graphs and their embedding and then review some of the random walk-based embedding methods that have been developed recently.
6/12/2024
🖼️
Knowledge Graph Completion using Structural and Textual Embeddings
Sakher Khalil Alqaaidi, Krzysztof Kochut
0
0
Knowledge Graphs (KGs) are widely employed in artificial intelligence applications, such as question-answering and recommendation systems. However, KGs are frequently found to be incomplete. While much of the existing literature focuses on predicting missing nodes for given incomplete KG triples, there remains an opportunity to complete KGs by exploring relations between existing nodes, a task known as relation prediction. In this study, we propose a relations prediction model that harnesses both textual and structural information within KGs. Our approach integrates walks-based embeddings with language model embeddings to effectively represent nodes. We demonstrate that our model achieves competitive results in the relation prediction task when evaluated on a widely used dataset.
4/26/2024
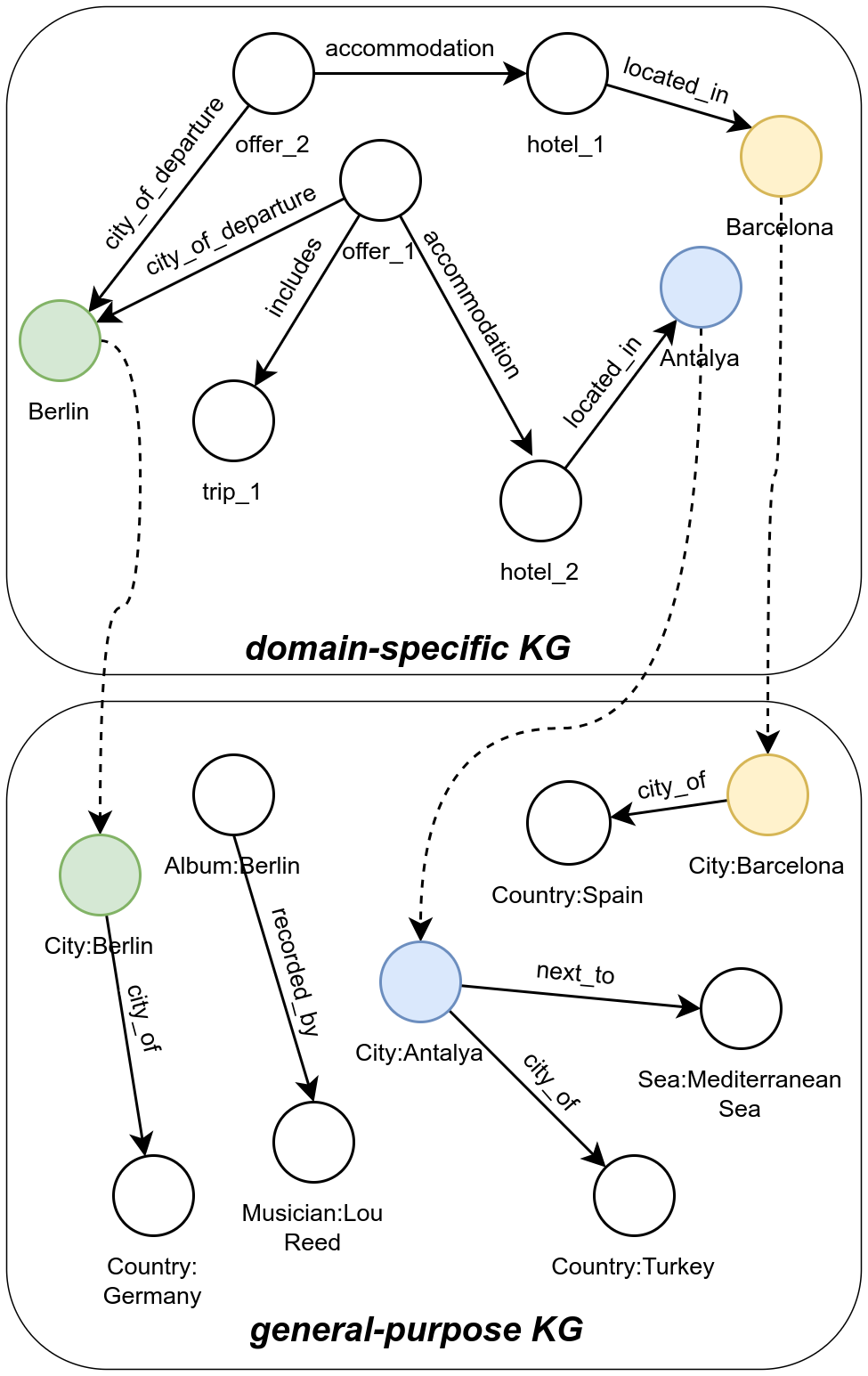
Empowering Small-Scale Knowledge Graphs: A Strategy of Leveraging General-Purpose Knowledge Graphs for Enriched Embeddings
Albert Sawczyn, Jakub Binkowski, Piotr Bielak, Tomasz Kajdanowicz
0
0
Knowledge-intensive tasks pose a significant challenge for Machine Learning (ML) techniques. Commonly adopted methods, such as Large Language Models (LLMs), often exhibit limitations when applied to such tasks. Nevertheless, there have been notable endeavours to mitigate these challenges, with a significant emphasis on augmenting LLMs through Knowledge Graphs (KGs). While KGs provide many advantages for representing knowledge, their development costs can deter extensive research and applications. Addressing this limitation, we introduce a framework for enriching embeddings of small-scale domain-specific Knowledge Graphs with well-established general-purpose KGs. Adopting our method, a modest domain-specific KG can benefit from a performance boost in downstream tasks when linked to a substantial general-purpose KG. Experimental evaluations demonstrate a notable enhancement, with up to a 44% increase observed in the Hits@10 metric. This relatively unexplored research direction can catalyze more frequent incorporation of KGs in knowledge-intensive tasks, resulting in more robust, reliable ML implementations, which hallucinates less than prevalent LLM solutions. Keywords: knowledge graph, knowledge graph completion, entity alignment, representation learning, machine learning
5/20/2024
🌀
Knowledge Graph Embedding in Intent-Based Networking
Kashif Mehmood, Katina Kralevska, David Palma
0
0
This paper presents a novel approach to network management by integrating intent-based networking (IBN) with knowledge graphs (KGs), creating a more intuitive and efficient pipeline for service orchestration. By mapping high-level business intents onto network configurations using KGs, the system dynamically adapts to network changes and service demands, ensuring optimal performance and resource allocation. We utilize knowledge graph embedding (KGE) to acquire context information from the network and service providers. The KGE model is trained using a custom KG and Gaussian embedding model and maps intents to services via service prediction and intent validation processes. The proposed intent lifecycle enables intent translation and assurance by only deploying validated intents according to network and resource availability. We evaluate the trained model for its efficiency in service mapping and intent validation tasks using simulated environments and extensive experiments. The service prediction and intent verification accuracy greater than 80 percent is achieved for the trained KGE model on a custom service orchestration intent knowledge graph (IKG) based on TMForum's intent common model.
5/14/2024