A Survey on the Robustness of Computer Vision Models against Common Corruptions

0
👀
Sign in to get full access
Overview
- Computer vision models can be affected by unexpected changes in input images, such as sensor errors or extreme lighting conditions.
- These common corruptions can significantly reduce the reliability of these models when deployed in real-world scenarios.
- This survey presents methods that improve the robustness of computer vision models against common corruptions.
- The methods are categorized into three groups: data augmentation, learning strategies, and network components.
- A unified benchmark framework is provided to compare robustness performance across datasets.
- The evaluation practices in the literature are also addressed to address inconsistencies.
Plain English Explanation
<a href="https://aimodels.fyi/papers/arxiv/survey-robustness-computer-vision-models-against-common">Computer vision models</a> are software systems that can analyze and interpret visual information, such as images or videos. These models are widely used in various applications, from self-driving cars to medical imaging. However, these models can be vulnerable to unexpected changes in the input images, known as <a href="https://aimodels.fyi/papers/arxiv/common-corruptions-enhancing-evaluating-robustness-air-to">common corruptions</a>. These corruptions can be caused by sensor errors, extreme lighting conditions, or other environmental factors.
When a computer vision model is deployed in the real world, it may encounter these corruptions, which can significantly reduce its reliability and performance. This is a critical issue, as these models are often used in high-stakes applications where their accuracy and reliability are paramount.
To address this problem, researchers have developed various methods to improve the <a href="https://aimodels.fyi/papers/arxiv/enhanced-model-robustness-to-input-corruptions-by">robustness of computer vision models against common corruptions</a>. These methods can be categorized into three main groups:
- Data Augmentation: Techniques that artificially generate corrupted images to train the model, making it more resilient to real-world corruptions.
- Learning Strategies: Specialized training approaches that help the model learn to be more robust to a wide range of corruptions.
- Network Components: Architectural modifications to the model itself, such as adding specific layers or modules, to enhance its corruption-handling capabilities.
To help researchers and developers compare the performance of these methods, the researchers have released a <a href="https://aimodels.fyi/papers/arxiv/posebench-benchmarking-robustness-pose-estimation-models-under">unified benchmark framework</a>. This framework includes several datasets and evaluation metrics, allowing for a more consistent and comprehensive assessment of model robustness.
By understanding and improving the robustness of computer vision models to common corruptions, researchers can help ensure these models are more reliable and trustworthy when deployed in real-world applications, such as <a href="https://aimodels.fyi/papers/arxiv/visual-robustness-benchmark-visual-question-answering-vqa">visual question answering</a> or pose estimation.
Technical Explanation
The survey paper first explains the importance of improving the robustness of computer vision models to common corruptions, such as noise, blur, and illumination changes. These corruptions can significantly degrade the performance of these models when deployed in real-world scenarios, but they are often overlooked during model evaluation and testing.
The researchers then categorize the existing methods for improving corruption robustness into three main groups:
-
Data Augmentation: These techniques involve artificially generating corrupted images during the training process to make the model more resilient to real-world corruptions. This can include adding noise, applying blur filters, or simulating changes in lighting conditions.
-
Learning Strategies: These specialized training approaches aim to help the model learn more robust features and representations that are less sensitive to common corruptions. This can involve techniques like adversarial training, meta-learning, or multi-task learning.
-
Network Components: Architectural modifications to the model itself, such as adding specialized layers or modules, can enhance the model's ability to handle corrupted inputs. This can include components like attention mechanisms, skip connections, or specialized normalization layers.
To facilitate the comparison of these robustness-enhancing methods, the researchers have developed a <a href="https://aimodels.fyi/papers/arxiv/posebench-benchmarking-robustness-pose-estimation-models-under">unified benchmark framework</a>. This framework includes several standard computer vision datasets, as well as a set of common corruption types and severity levels. Using this framework, the researchers can assess the performance and robustness of different models and methods in a more consistent and comprehensive manner.
The paper also highlights some key insights from their experimental analysis. For example, they find that corruption robustness does not necessarily scale with model size or training data size, as large models often gain only negligible robustness improvements compared to the increased computational requirements. This suggests the need for developing new learning strategies that can efficiently exploit limited data and mitigate unreliable learning behaviors to achieve truly generalizable and robust computer vision models.
Critical Analysis
The survey paper provides a comprehensive overview of the methods and approaches for improving the robustness of computer vision models to common corruptions. By categorizing the existing techniques into data augmentation, learning strategies, and network components, the researchers offer a clear and structured way for readers to understand the different approaches and their relative strengths and weaknesses.
One of the key strengths of the paper is the development of the unified benchmark framework. This tool can help address the inconsistencies in evaluation practices that have plagued the existing literature, allowing for a more apples-to-apples comparison of different robustness-enhancing methods. However, the effectiveness of this framework will depend on its continued maintenance and adoption by the research community.
The researchers also raise an important point about the limitations of simply scaling up model size and training data to improve robustness. This finding suggests that more innovative and efficient learning strategies are needed to truly achieve generalizable and robust computer vision models. The paper could have delved deeper into the specific challenges and potential solutions in this area, as this seems to be a critical direction for future research.
One potential area for further exploration is the interplay between robustness to common corruptions and other desirable model properties, such as accuracy, efficiency, and fairness. It would be interesting to see how different robustness-enhancing methods impact these other aspects of model performance and whether there are any inherent trade-offs or synergies.
Overall, the survey paper provides a valuable resource for researchers and practitioners working on improving the reliability and real-world performance of computer vision models. By highlighting the key methods, insights, and research directions, the paper can help drive the development of more robust and trustworthy computer vision systems.
Conclusion
This survey paper presents a comprehensive overview of methods for improving the robustness of computer vision models against common corruptions, such as noise, blur, and illumination changes. The researchers categorize the existing techniques into three main groups: data augmentation, learning strategies, and network components.
To facilitate the comparison of these robustness-enhancing methods, the researchers have developed a unified benchmark framework that includes standard computer vision datasets and a set of common corruption types and severity levels. This tool can help address the inconsistencies in evaluation practices that have been a challenge in the existing literature.
The paper also highlights some key insights from the experimental analysis, such as the finding that corruption robustness does not necessarily scale with model size or training data size. This suggests the need for developing new learning strategies that can efficiently exploit limited data and mitigate unreliable learning behaviors to achieve truly generalizable and robust computer vision models.
By understanding and improving the robustness of computer vision models to common corruptions, researchers can help ensure these models are more reliable and trustworthy when deployed in real-world applications, such as self-driving cars, medical imaging, and visual question answering. The insights and methods presented in this survey paper can serve as a valuable resource for the research community to advance the field of robust computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
New!A Survey on the Robustness of Computer Vision Models against Common Corruptions
Shunxin Wang, Raymond Veldhuis, Christoph Brune, Nicola Strisciuglio
The performance of computer vision models are susceptible to unexpected changes in input images caused by sensor errors or extreme imaging environments, known as common corruptions (e.g. noise, blur, illumination changes). These corruptions can significantly hinder the reliability of these models when deployed in real-world scenarios, yet they are often overlooked when testing model generalization and robustness. In this survey, we present a comprehensive overview of methods that improve the robustness of computer vision models against common corruptions. We categorize methods into three groups based on the model components and training methods they target: data augmentation, learning strategies, and network components. We release a unified benchmark framework (available at url{https://github.com/nis-research/CorruptionBenchCV}) to compare robustness performance across several datasets, and we address the inconsistencies of evaluation practices in the literature. Our experimental analysis highlights the base corruption robustness of popular vision backbones, revealing that corruption robustness does not necessarily scale with model size and data size. Large models gain negligible robustness improvements, considering the increased computational requirements. To achieve generalizable and robust computer vision models, we foresee the need of developing new learning strategies that efficiently exploit limited data and mitigate unreliable learning behaviors.
Read more9/17/2024

0
Common Corruptions for Enhancing and Evaluating Robustness in Air-to-Air Visual Object Detection
Anastasios Arsenos, Vasileios Karampinis, Evangelos Petrongonas, Christos Skliros, Dimitrios Kollias, Stefanos Kollias, Athanasios Voulodimos
The main barrier to achieving fully autonomous flights lies in autonomous aircraft navigation. Managing non-cooperative traffic presents the most important challenge in this problem. The most efficient strategy for handling non-cooperative traffic is based on monocular video processing through deep learning models. This study contributes to the vision-based deep learning aircraft detection and tracking literature by investigating the impact of data corruption arising from environmental and hardware conditions on the effectiveness of these methods. More specifically, we designed $7$ types of common corruptions for camera inputs taking into account real-world flight conditions. By applying these corruptions to the Airborne Object Tracking (AOT) dataset we constructed the first robustness benchmark dataset named AOT-C for air-to-air aerial object detection. The corruptions included in this dataset cover a wide range of challenging conditions such as adverse weather and sensor noise. The second main contribution of this letter is to present an extensive experimental evaluation involving $8$ diverse object detectors to explore the degradation in the performance under escalating levels of corruptions (domain shifts). Based on the evaluation results, the key observations that emerge are the following: 1) One-stage detectors of the YOLO family demonstrate better robustness, 2) Transformer-based and multi-stage detectors like Faster R-CNN are extremely vulnerable to corruptions, 3) Robustness against corruptions is related to the generalization ability of models. The third main contribution is to present that finetuning on our augmented synthetic data results in improvements in the generalisation ability of the object detector in real-world flight experiments.
Read more5/17/2024

0
Enhanced Model Robustness to Input Corruptions by Per-corruption Adaptation of Normalization Statistics
Elena Camuffo, Umberto Michieli, Simone Milani, Jijoong Moon, Mete Ozay
Developing a reliable vision system is a fundamental challenge for robotic technologies (e.g., indoor service robots and outdoor autonomous robots) which can ensure reliable navigation even in challenging environments such as adverse weather conditions (e.g., fog, rain), poor lighting conditions (e.g., over/under exposure), or sensor degradation (e.g., blurring, noise), and can guarantee high performance in safety-critical functions. Current solutions proposed to improve model robustness usually rely on generic data augmentation techniques or employ costly test-time adaptation methods. In addition, most approaches focus on addressing a single vision task (typically, image recognition) utilising synthetic data. In this paper, we introduce Per-corruption Adaptation of Normalization statistics (PAN) to enhance the model robustness of vision systems. Our approach entails three key components: (i) a corruption type identification module, (ii) dynamic adjustment of normalization layer statistics based on identified corruption type, and (iii) real-time update of these statistics according to input data. PAN can integrate seamlessly with any convolutional model for enhanced accuracy in several robot vision tasks. In our experiments, PAN obtains robust performance improvement on challenging real-world corrupted image datasets (e.g., OpenLoris, ExDark, ACDC), where most of the current solutions tend to fail. Moreover, PAN outperforms the baseline models by 20-30% on synthetic benchmarks in object recognition tasks.
Read more7/10/2024
0
PoseBench: Benchmarking the Robustness of Pose Estimation Models under Corruptions
Sihan Ma, Jing Zhang, Qiong Cao, Dacheng Tao
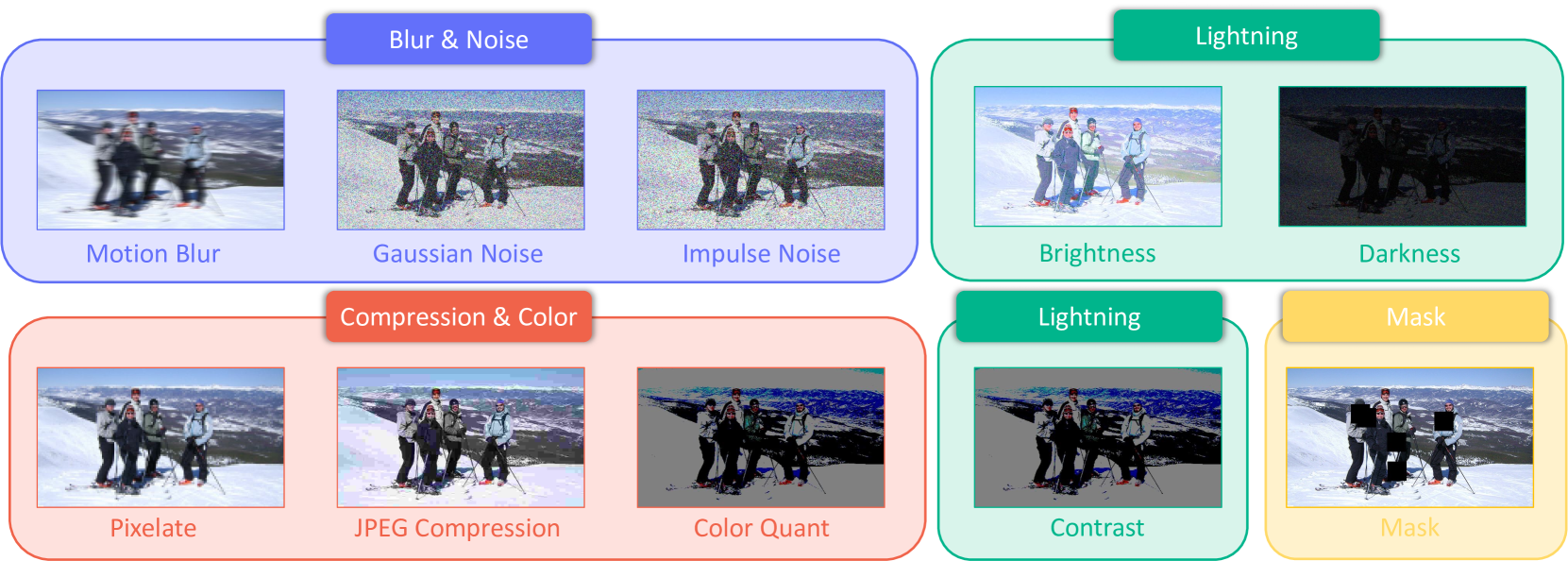
Pose estimation aims to accurately identify anatomical keypoints in humans and animals using monocular images, which is crucial for various applications such as human-machine interaction, embodied AI, and autonomous driving. While current models show promising results, they are typically trained and tested on clean data, potentially overlooking the corruption during real-world deployment and thus posing safety risks in practical scenarios. To address this issue, we introduce PoseBench, a comprehensive benchmark designed to evaluate the robustness of pose estimation models against real-world corruption. We evaluated 60 representative models, including top-down, bottom-up, heatmap-based, regression-based, and classification-based methods, across three datasets for human and animal pose estimation. Our evaluation involves 10 types of corruption in four categories: 1) blur and noise, 2) compression and color loss, 3) severe lighting, and 4) masks. Our findings reveal that state-of-the-art models are vulnerable to common real-world corruptions and exhibit distinct behaviors when tackling human and animal pose estimation tasks. To improve model robustness, we delve into various design considerations, including input resolution, pre-training datasets, backbone capacity, post-processing, and data augmentations. We hope that our benchmark will serve as a foundation for advancing research in robust pose estimation. The benchmark and source code will be released at https://xymsh.github.io/PoseBench
Read more9/17/2024