A Survey on Statistical Theory of Deep Learning: Approximation, Training Dynamics, and Generative Models

0
🤿
Sign in to get full access
Overview
- This paper provides a comprehensive survey of the statistical theory of deep learning, covering topics such as approximation, training dynamics, and generative models.
- The paper highlights the importance of theory in understanding and advancing deep learning, and outlines a roadmap for the key ideas and insights discussed.
- The technical explanation covers the core elements of the paper, including experiment design, architectural considerations, and the key theoretical findings.
- The critical analysis examines the caveats, limitations, and areas for future research identified in the paper, encouraging readers to think critically about the research.
- The conclusion summarizes the main takeaways and their potential implications for the field and society at large.
Plain English Explanation
Deep learning, a powerful machine learning technique, has seen remarkable success in a wide range of applications, from image recognition to natural language processing. However, the underlying theoretical foundations of deep learning are not yet fully understood. A Survey on Statistical Theory of Deep Learning: Approximation, Training Dynamics, and Generative Models aims to provide a comprehensive overview of the current state of the statistical theory of deep learning.
The paper argues that developing a strong theoretical understanding of deep learning is crucial for further advancements in the field. By delving into the mathematical underpinnings of deep learning, researchers can gain insights into why certain architectures and training techniques work well, and how to design more effective and efficient deep learning models.
The paper covers three key areas of deep learning theory:
-
Approximation: This section explores the expressive power of deep neural networks, investigating their ability to approximate complex functions and capture intricate patterns in data.
-
Training Dynamics: Here, the paper examines the optimization challenges involved in training deep neural networks, such as the behavior of gradient descent and the convergence properties of different training algorithms.
-
Generative Models: The final section focuses on the theoretical foundations of deep generative models, which are used to generate new data samples that resemble the training data.
Throughout the paper, the authors provide intuitive explanations and examples to help readers understand the technical concepts. They also discuss the limitations of the current research and identify promising areas for future exploration, encouraging readers to think critically about the implications of this work.
By synthesizing the latest advancements in the statistical theory of deep learning, this paper offers a valuable resource for researchers, engineers, and anyone interested in understanding the inner workings of this transformative technology.
Technical Explanation
The paper begins by emphasizing the importance of developing a strong theoretical foundation for deep learning, as it can provide valuable insights into the capabilities and limitations of deep neural networks, as well as guide the development of more effective and efficient models.
The first section of the paper explores the approximation capabilities of deep neural networks. The authors discuss various theoretical results that characterize the expressive power of deep neural networks, including their ability to approximate arbitrary continuous functions and their advantages over shallow networks in terms of representational efficiency. They also explore the implications of these approximation properties for practical deep learning applications.
The next section delves into the training dynamics of deep neural networks. The paper examines the behavior of gradient-based optimization algorithms, such as stochastic gradient descent, used to train deep models. This includes an analysis of the convergence properties of these algorithms, as well as the role of hyperparameters and network architectures in the training process.
The final section of the technical explanation focuses on generative models, which are deep neural networks trained to generate new data samples that resemble the training data. The authors provide an overview of the theoretical foundations of deep generative models, including insights into their sampling and inference capabilities, as well as the challenges involved in training these models effectively.
Throughout the technical explanation, the authors cite relevant research papers and provide mathematical formulations and proofs to support the key theoretical concepts. They also discuss the limitations of the current research and identify promising directions for future work, such as the need for a unified theoretical framework that can account for the complexities of real-world deep learning applications.
Critical Analysis
The paper presents a comprehensive and well-structured survey of the statistical theory of deep learning, covering a wide range of topics and highlighting the importance of developing a strong theoretical understanding of this transformative technology.
One of the strengths of the paper is its balanced approach, which acknowledges both the significant progress that has been made in deep learning theory and the numerous challenges that remain. The authors do not shy away from discussing the limitations of the current research, such as the difficulty of applying theoretical results to practical deep learning systems, the need for more scalable and computationally efficient analysis techniques, and the lack of a unified theoretical framework that can account for the complexities of real-world deep learning applications.
Additionally, the authors encourage readers to think critically about the research and identify potential areas for further exploration. For example, they suggest the need to better understand the role of network architecture and hyperparameters in the training dynamics of deep neural networks, as well as the importance of developing more sophisticated generative models that can capture the rich structure of real-world data.
However, one potential criticism of the paper is that it may be overly focused on the theoretical aspects of deep learning, at the expense of a more practical, application-oriented perspective. While the technical explanations are well-executed, some readers may desire more discussion of how the theoretical insights can be translated into tangible improvements in deep learning systems and their real-world performance.
Overall, A Survey on Statistical Theory of Deep Learning: Approximation, Training Dynamics, and Generative Models is a valuable resource for researchers, engineers, and anyone interested in understanding the mathematical foundations of deep learning. Its balanced approach and critical analysis provide a solid foundation for further exploration and advancement in this rapidly evolving field.
Conclusion
This comprehensive survey paper highlights the importance of developing a strong theoretical understanding of deep learning, as it can provide valuable insights into the capabilities and limitations of deep neural networks, as well as guide the development of more effective and efficient models.
The paper covers three key areas of deep learning theory: approximation, training dynamics, and generative models. By synthesizing the latest advancements in these areas, the authors offer a valuable resource for researchers and practitioners alike, helping to bridge the gap between the empirical success of deep learning and its underlying mathematical foundations.
While the paper acknowledges the significant progress that has been made in deep learning theory, it also identifies numerous challenges and areas for future exploration, such as the need for more scalable and computationally efficient analysis techniques, and the importance of developing a unified theoretical framework that can account for the complexities of real-world deep learning applications.
Overall, this paper serves as an important milestone in the ongoing effort to deepen our understanding of deep learning and unlock its full potential for tackling a wide range of complex problems in various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
A Survey on Statistical Theory of Deep Learning: Approximation, Training Dynamics, and Generative Models
Namjoon Suh, Guang Cheng
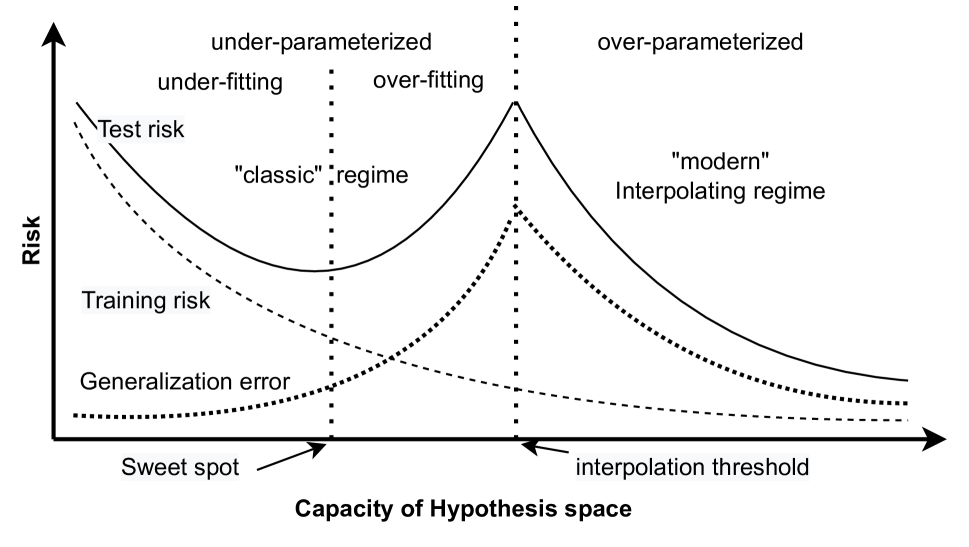
In this article, we review the literature on statistical theories of neural networks from three perspectives: approximation, training dynamics and generative models. In the first part, results on excess risks for neural networks are reviewed in the nonparametric framework of regression (and classification in Appendix~{color{blue}B}). These results rely on explicit constructions of neural networks, leading to fast convergence rates of excess risks. Nonetheless, their underlying analysis only applies to the global minimizer in the highly non-convex landscape of deep neural networks. This motivates us to review the training dynamics of neural networks in the second part. Specifically, we review papers that attempt to answer ``how the neural network trained via gradient-based methods finds the solution that can generalize well on unseen data.'' In particular, two well-known paradigms are reviewed: the Neural Tangent Kernel (NTK) paradigm, and Mean-Field (MF) paradigm. Last but not least, we review the most recent theoretical advancements in generative models including Generative Adversarial Networks (GANs), diffusion models, and in-context learning (ICL) in the Large Language Models (LLMs) from two perpsectives reviewed previously, i.e., approximation and training dynamics.
Read more9/17/2024
0
General Distribution Learning: A theoretical framework for Deep Learning
Binchuan Qi
This paper introduces General Distribution Learning (GD learning), a novel theoretical learning framework designed to address a comprehensive range of machine learning and statistical tasks, including classification, regression, and parameter estimation. GD learning focuses on estimating the true underlying probability distribution of dataset and using models to fit the estimated parameters of the distribution. The learning error in GD learning is thus decomposed into two distinct categories: estimation error and fitting error. The estimation error, which stems from the constraints of finite sampling, limited prior knowledge, and the estimation algorithm's inherent limitations, quantifies the discrepancy between the true distribution and its estimate. The fitting error can be attributed to model's capacity limitation and the performance limitation of the optimization algorithm, which evaluates the deviation of the model output from the fitted objective. To address the challenge of non-convexity in the optimization of learning error, we introduce the standard loss function and demonstrate that, when employing this function, global optimal solutions in non-convex optimization can be approached by minimizing the gradient norm and the structural error. Moreover, we demonstrate that the estimation error is determined by the uncertainty of the estimate $q$, and propose the minimum uncertainty principle to obtain an optimal estimate of the true distribution. We further provide upper bounds for the estimation error, fitting error, and learning error within the GD learning framework. Ultimately, our findings are applied to offer theoretical explanations for several unanswered questions on deep learning, including overparameterization, non-convex optimization, flat minima, dynamic isometry condition and other techniques in deep learning.
Read more7/19/2024
0
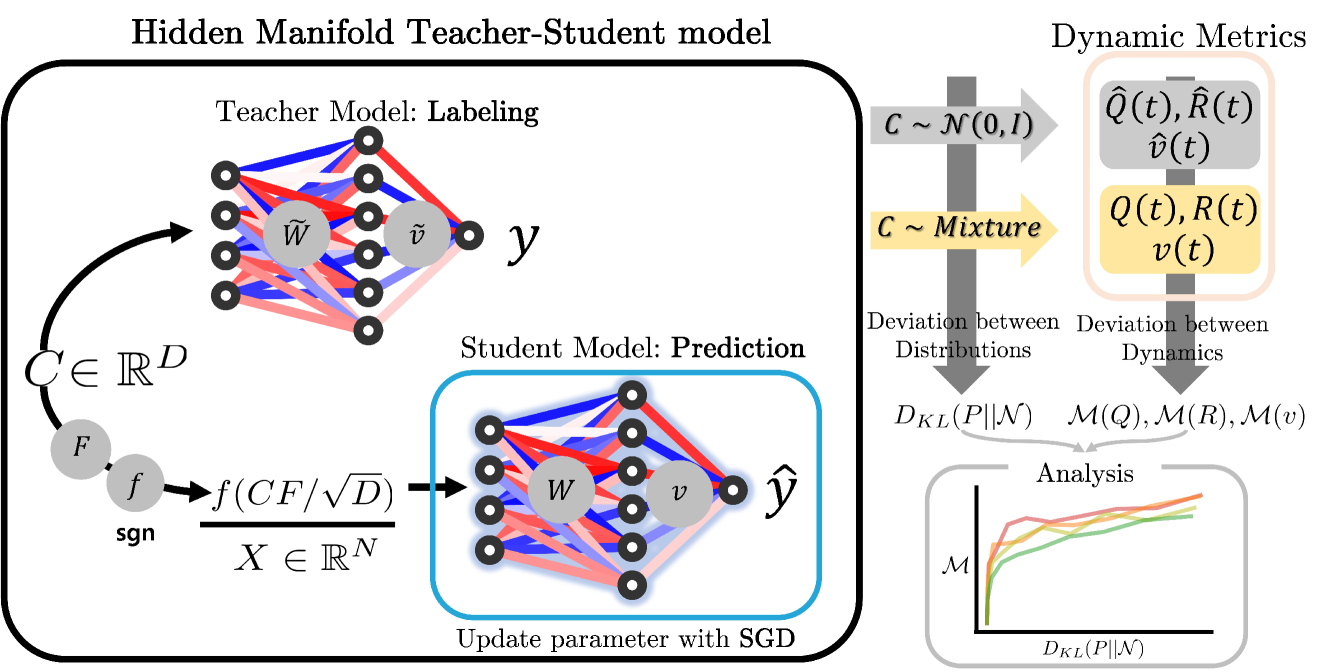
From Empirical Observations to Universality: Dynamics of Deep Learning with Inputs Built on Gaussian mixture
Jaeyong Bae, Hawoong Jeong
This study broadens the scope of theoretical frameworks in deep learning by delving into the dynamics of neural networks with inputs that demonstrate the structural characteristics to Gaussian Mixture (GM). We analyzed how the dynamics of neural networks under GM-structured inputs diverge from the predictions of conventional theories based on simple Gaussian structures. A revelation of our work is the observed convergence of neural network dynamics towards conventional theory even with standardized GM inputs, highlighting an unexpected universality. We found that standardization, especially in conjunction with certain nonlinear functions, plays a critical role in this phenomena. Consequently, despite the complex and varied nature of GM distributions, we demonstrate that neural networks exhibit asymptotic behaviors in line with predictions under simple Gaussian frameworks.
Read more5/2/2024
🏋️
0
Approximation and Gradient Descent Training with Neural Networks
G. Welper
It is well understood that neural networks with carefully hand-picked weights provide powerful function approximation and that they can be successfully trained in over-parametrized regimes. Since over-parametrization ensures zero training error, these two theories are not immediately compatible. Recent work uses the smoothness that is required for approximation results to extend a neural tangent kernel (NTK) optimization argument to an under-parametrized regime and show direct approximation bounds for networks trained by gradient flow. Since gradient flow is only an idealization of a practical method, this paper establishes analogous results for networks trained by gradient descent.
Read more5/21/2024