A Survey of Useful LLM Evaluation

0
Sign in to get full access
Overview
- This paper provides a comprehensive survey of various approaches to evaluating large language models (LLMs).
- It explores the challenges and potential solutions in assessing the capabilities and limitations of these powerful AI systems.
- The paper covers key topics such as evaluating task utility of LLM-powered applications, comparing the performance of different LLMs, and using LLMs in educational contexts.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can generate human-like text, answer questions, and complete various tasks. As these models become more advanced and widely used, it's important to have reliable ways to evaluate their capabilities and limitations.
This paper explores different approaches to LLM evaluation, aiming to help researchers, developers, and users better understand the strengths and weaknesses of these AI systems. It covers topics like assessing the real-world utility of LLM-powered applications, comparing the performance of different LLMs, and using LLMs in educational settings.
The paper explains the challenges involved in evaluating LLMs, such as the complexity of their inner workings and the difficulty of capturing their full range of capabilities. It also suggests potential solutions, like developing more focused and task-specific evaluation metrics, to help address these challenges.
By providing a comprehensive overview of LLM evaluation approaches, this paper aims to help researchers, developers, and users make more informed decisions about the use and deployment of these powerful AI systems.
Technical Explanation
The paper begins by discussing the rapid advancements in artificial intelligence, particularly the development of large language models (LLMs) that can perform a wide variety of natural language processing tasks. It then delves into the various approaches to evaluating the performance and capabilities of these LLMs.
One key area covered is the assessment of the real-world utility of LLM-powered applications. The paper explores methods for measuring the practical impact and usefulness of LLM-driven solutions, such as their ability to assist with specific tasks or their integration into various domains.
The paper also examines the comparative evaluation of different LLMs, discussing the challenges of benchmarking these complex systems and identifying the most suitable models for particular use cases. It highlights the need for robust and standardized evaluation frameworks to facilitate meaningful comparisons.
Furthermore, the paper delves into the use of LLMs in educational contexts, exploring the potential benefits and drawbacks of incorporating these AI systems into teaching and learning environments. It examines the unique considerations and evaluation approaches required in such settings.
Throughout the paper, the authors emphasize the importance of developing focused and task-specific evaluation metrics to capture the nuances and complexities of LLM performance. They also discuss the challenges posed by the inherent limitations and potential biases of these models, and the need for comprehensive and rigorous evaluation methods to address these concerns.
Critical Analysis
The paper provides a thorough and well-researched overview of the various approaches to evaluating large language models (LLMs). However, it acknowledges that the field of LLM evaluation is still evolving, and there are several limitations and areas for further research.
One key limitation highlighted in the paper is the difficulty in capturing the full range of capabilities and limitations of these complex AI systems. The authors note that current evaluation methods may fall short in fully assessing the nuanced and context-dependent performance of LLMs, particularly in real-world applications.
Additionally, the paper recognizes the potential for biases and ethical concerns in the use of LLMs, which may not be adequately addressed by existing evaluation frameworks. Further research is needed to develop more comprehensive assessment methods that can identify and mitigate these issues.
The paper also acknowledges the challenge of developing standardized and widely accepted evaluation protocols, as the rapid pace of LLM development and the diversity of use cases make it difficult to establish universal benchmarks. More collaborative efforts among researchers, developers, and end-users may be necessary to address this challenge.
Overall, the paper provides a valuable contribution to the ongoing discussion around LLM evaluation, highlighting the need for continued research and innovation in this important area of artificial intelligence.
Conclusion
This paper offers a comprehensive survey of the various approaches to evaluating large language models (LLMs), a critical area of research as these powerful AI systems become more widely adopted. It explores the challenges and potential solutions in assessing the capabilities and limitations of LLMs, covering key topics such as evaluating the real-world utility of LLM-powered applications, comparing the performance of different LLMs, and using LLMs in educational contexts.
By providing a thorough overview of LLM evaluation methods and the associated challenges, this paper aims to assist researchers, developers, and users in making more informed decisions about the deployment and application of these advanced AI systems. As the field of LLM evaluation continues to evolve, the insights and recommendations presented in this paper can contribute to the development of more robust and comprehensive assessment frameworks, ultimately enabling the responsible and effective use of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Survey of Useful LLM Evaluation
Ji-Lun Peng, Sijia Cheng, Egil Diau, Yung-Yu Shih, Po-Heng Chen, Yen-Ting Lin, Yun-Nung Chen
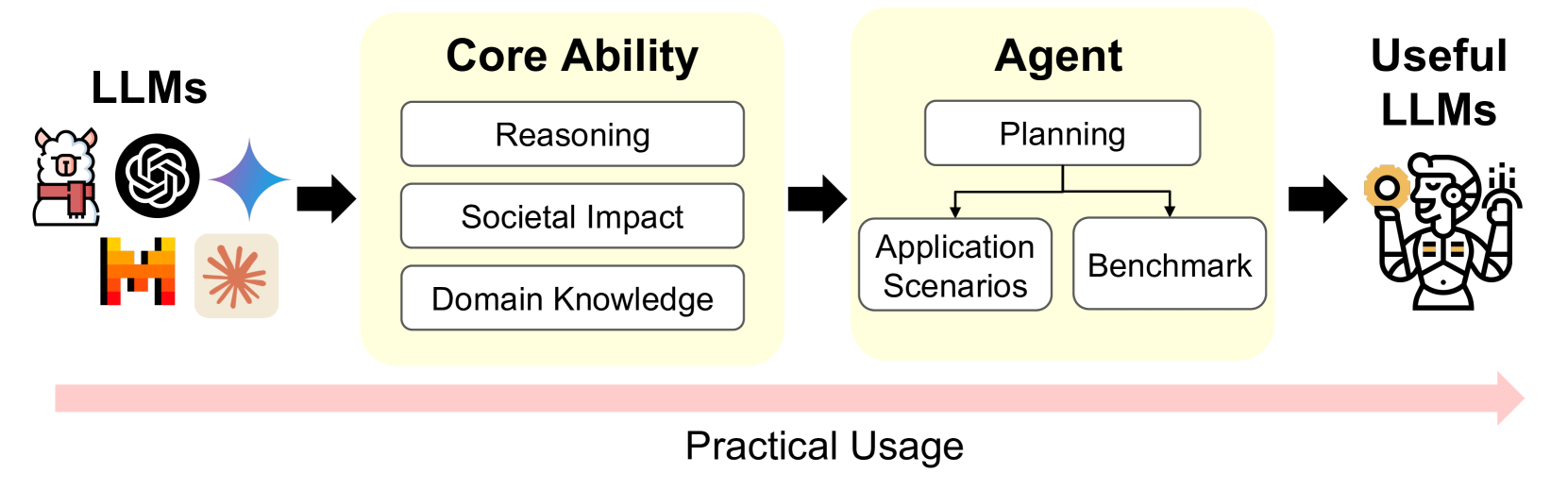
LLMs have gotten attention across various research domains due to their exceptional performance on a wide range of complex tasks. Therefore, refined methods to evaluate the capabilities of LLMs are needed to determine the tasks and responsibility they should undertake. Our study mainly discussed how LLMs, as useful tools, should be effectively assessed. We proposed the two-stage framework: from ``core ability'' to ``agent'', clearly explaining how LLMs can be applied based on their specific capabilities, along with the evaluation methods in each stage. Core ability refers to the capabilities that LLMs need in order to generate high-quality natural language texts. After confirming LLMs possess core ability, they can solve real-world and complex tasks as agent. In the core ability stage, we discussed the reasoning ability, societal impact, and domain knowledge of LLMs. In the ``agent'' stage, we demonstrated embodied action, planning, and tool learning of LLMs agent applications. Finally, we examined the challenges currently confronting the evaluation methods for LLMs, as well as the directions for future development.
Read more6/4/2024
0
A Reality check of the benefits of LLM in business
Ming Cheung
Large language models (LLMs) have achieved remarkable performance in language understanding and generation tasks by leveraging vast amounts of online texts. Unlike conventional models, LLMs can adapt to new domains through prompt engineering without the need for retraining, making them suitable for various business functions, such as strategic planning, project implementation, and data-driven decision-making. However, their limitations in terms of bias, contextual understanding, and sensitivity to prompts raise concerns about their readiness for real-world applications. This paper thoroughly examines the usefulness and readiness of LLMs for business processes. The limitations and capacities of LLMs are evaluated through experiments conducted on four accessible LLMs using real-world data. The findings have significant implications for organizations seeking to leverage generative AI and provide valuable insights into future research directions. To the best of our knowledge, this represents the first quantified study of LLMs applied to core business operations and challenges.
Read more6/18/2024
0
The Challenges of Evaluating LLM Applications: An Analysis of Automated, Human, and LLM-Based Approaches
Bhashithe Abeysinghe, Ruhan Circi
Chatbots have been an interesting application of natural language generation since its inception. With novel transformer based Generative AI methods, building chatbots have become trivial. Chatbots which are targeted at specific domains for example medicine and psychology are implemented rapidly. This however, should not distract from the need to evaluate the chatbot responses. Especially because the natural language generation community does not entirely agree upon how to effectively evaluate such applications. With this work we discuss the issue further with the increasingly popular LLM based evaluations and how they correlate with human evaluations. Additionally, we introduce a comprehensive factored evaluation mechanism that can be utilized in conjunction with both human and LLM-based evaluations. We present the results of an experimental evaluation conducted using this scheme in one of our chatbot implementations which consumed educational reports, and subsequently compare automated, traditional human evaluation, factored human evaluation, and factored LLM evaluation. Results show that factor based evaluation produces better insights on which aspects need to be improved in LLM applications and further strengthens the argument to use human evaluation in critical spaces where main functionality is not direct retrieval.
Read more6/14/2024
🚀
0
Unveiling LLM Evaluation Focused on Metrics: Challenges and Solutions
Taojun Hu, Xiao-Hua Zhou
Natural Language Processing (NLP) is witnessing a remarkable breakthrough driven by the success of Large Language Models (LLMs). LLMs have gained significant attention across academia and industry for their versatile applications in text generation, question answering, and text summarization. As the landscape of NLP evolves with an increasing number of domain-specific LLMs employing diverse techniques and trained on various corpus, evaluating performance of these models becomes paramount. To quantify the performance, it's crucial to have a comprehensive grasp of existing metrics. Among the evaluation, metrics which quantifying the performance of LLMs play a pivotal role. This paper offers a comprehensive exploration of LLM evaluation from a metrics perspective, providing insights into the selection and interpretation of metrics currently in use. Our main goal is to elucidate their mathematical formulations and statistical interpretations. We shed light on the application of these metrics using recent Biomedical LLMs. Additionally, we offer a succinct comparison of these metrics, aiding researchers in selecting appropriate metrics for diverse tasks. The overarching goal is to furnish researchers with a pragmatic guide for effective LLM evaluation and metric selection, thereby advancing the understanding and application of these large language models.
Read more4/16/2024