The Challenges of Evaluating LLM Applications: An Analysis of Automated, Human, and LLM-Based Approaches

0
Sign in to get full access
Overview
- Examines the challenges in evaluating Large Language Model (LLM) applications, comparing automated, human, and LLM-based evaluation approaches
- Highlights the limitations of existing evaluation methods and the need for more comprehensive and reliable assessment frameworks
- Proposes a factor-based evaluation methodology to address the shortcomings of current evaluation practices
Plain English Explanation
This paper explores the difficulties in assessing the performance of large language models (LLMs), which are artificial intelligence systems trained on vast amounts of text data to generate human-like responses. The researchers compare different approaches to evaluating LLM applications, including automated methods, human assessments, and LLM-based evaluations.
The paper argues that existing evaluation techniques have significant limitations. Automated methods may not capture the nuances of language use or the contextual appropriateness of the model's outputs. Human evaluations, while more insightful, can be time-consuming and prone to inconsistencies. LLM-based evaluations, where the model is used to assess its own performance, may also have biases and blind spots.
To address these challenges, the researchers propose a "factor-based" evaluation methodology. This approach involves breaking down the assessment of LLM applications into various factors, such as link to 'factor based evaluation' coherence, factual accuracy, and task-specific performance. By considering these different factors, the researchers aim to provide a more comprehensive and reliable way to evaluate LLM applications.
The paper highlights the importance of developing robust and multifaceted evaluation frameworks to ensure that LLMs are being assessed accurately and effectively. This is crucial as these models become more widely adopted in various applications, from link to 'LLM Evaluation' language assistance to link to 'Human Evaluation' content generation.
Technical Explanation
The paper begins by discussing the growing importance of large language models (LLMs) in a wide range of applications, from language assistance to content generation. However, the authors note that effectively evaluating the performance of these LLM applications remains a significant challenge.
The researchers compare three main approaches to LLM evaluation: automated methods, human assessments, and LLM-based evaluations. Automated methods, such as link to 'Automated, Human, and LLM-Based Approaches', can provide objective and scalable evaluations, but may miss important contextual nuances. Human evaluations offer more insight, but can be time-consuming and prone to inconsistencies. LLM-based evaluations, where the model is used to assess its own performance, may also have biases and blind spots.
To address these limitations, the authors propose a "factor-based" evaluation methodology. This approach involves breaking down the assessment of LLM applications into various factors, such as link to 'factor based evaluation' coherence, factual accuracy, and task-specific performance. By considering these different factors, the researchers aim to provide a more comprehensive and reliable way to evaluate LLM applications.
The paper also discusses the importance of developing robust and multifaceted evaluation frameworks to ensure that LLMs are being assessed accurately and effectively. This is particularly crucial as these models become more widely adopted in various applications, from link to 'LLM Evaluation' language assistance to link to 'Human Evaluation' content generation.
Critical Analysis
The paper raises important points about the limitations of current LLM evaluation methods and the need for more comprehensive and reliable assessment frameworks. The proposed factor-based evaluation approach seems promising, as it acknowledges the multifaceted nature of LLM performance and the importance of considering various aspects, such as coherence, factual accuracy, and task-specific capabilities.
However, the paper does not delve into the specific details of how the factor-based evaluation would be implemented in practice. It would be helpful to see more information on the specific factors to be considered, how they would be measured, and how the overall evaluation would be synthesized. Additionally, the paper could have discussed the potential challenges and trade-offs in balancing the different evaluation factors.
Furthermore, the paper could have explored the role of link to 'Auto Arena: Automating LLM Evaluations' in addressing the limitations of human evaluations, as well as the potential for using LLM-based evaluations in a more nuanced and controlled way to mitigate the risks of biases and blind spots.
Overall, the paper effectively highlights the need for more robust and comprehensive LLM evaluation frameworks, and the proposed factor-based approach is a step in the right direction. However, further research and practical implementation details would be valuable to fully assess the viability and efficacy of this evaluation methodology.
Conclusion
This paper emphasizes the critical challenges in evaluating the performance of large language models (LLMs) and the limitations of existing evaluation methods, including automated, human, and LLM-based approaches. To address these challenges, the researchers propose a factor-based evaluation methodology that considers various aspects of LLM performance, such as coherence, factual accuracy, and task-specific capabilities.
The proposed framework aims to provide a more comprehensive and reliable way to assess the effectiveness of LLM applications, which are becoming increasingly prevalent in a wide range of domains. As these models continue to evolve and be deployed in more real-world scenarios, the development of robust and multifaceted evaluation frameworks will be crucial to ensure that they are being assessed accurately and effectively.
The paper highlights the importance of continued research and innovation in the field of LLM evaluation, as the accurate assessment of these powerful AI systems will have significant implications for their continued development and deployment in various applications that impact our daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Challenges of Evaluating LLM Applications: An Analysis of Automated, Human, and LLM-Based Approaches
Bhashithe Abeysinghe, Ruhan Circi
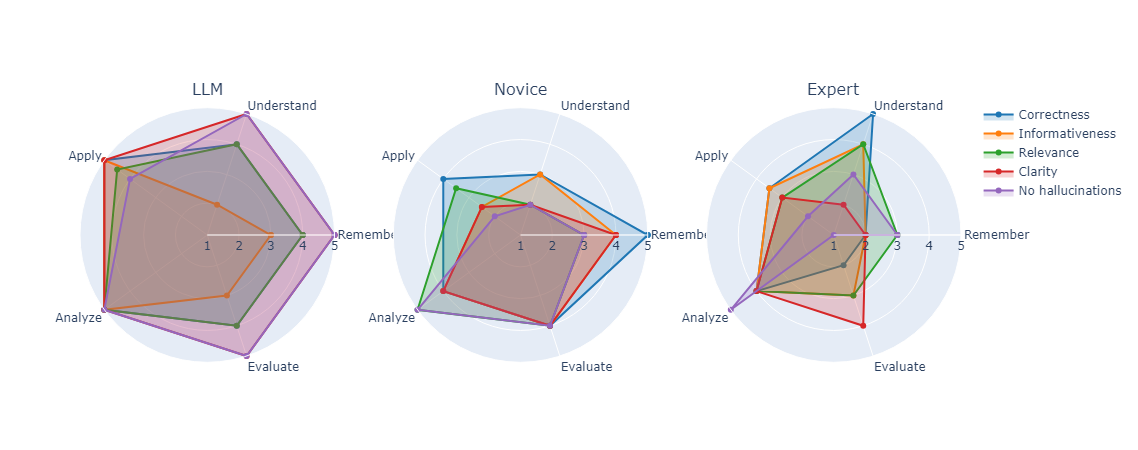
Chatbots have been an interesting application of natural language generation since its inception. With novel transformer based Generative AI methods, building chatbots have become trivial. Chatbots which are targeted at specific domains for example medicine and psychology are implemented rapidly. This however, should not distract from the need to evaluate the chatbot responses. Especially because the natural language generation community does not entirely agree upon how to effectively evaluate such applications. With this work we discuss the issue further with the increasingly popular LLM based evaluations and how they correlate with human evaluations. Additionally, we introduce a comprehensive factored evaluation mechanism that can be utilized in conjunction with both human and LLM-based evaluations. We present the results of an experimental evaluation conducted using this scheme in one of our chatbot implementations which consumed educational reports, and subsequently compare automated, traditional human evaluation, factored human evaluation, and factored LLM evaluation. Results show that factor based evaluation produces better insights on which aspects need to be improved in LLM applications and further strengthens the argument to use human evaluation in critical spaces where main functionality is not direct retrieval.
Read more6/14/2024

0
On the Benchmarking of LLMs for Open-Domain Dialogue Evaluation
John Mendonc{c}a, Alon Lavie, Isabel Trancoso
Large Language Models (LLMs) have showcased remarkable capabilities in various Natural Language Processing tasks. For automatic open-domain dialogue evaluation in particular, LLMs have been seamlessly integrated into evaluation frameworks, and together with human evaluation, compose the backbone of most evaluations. However, existing evaluation benchmarks often rely on outdated datasets and evaluate aspects like Fluency and Relevance, which fail to adequately capture the capabilities and limitations of state-of-the-art chatbot models. This paper critically examines current evaluation benchmarks, highlighting that the use of older response generators and quality aspects fail to accurately reflect modern chatbot capabilities. A small annotation experiment on a recent LLM-generated dataset (SODA) reveals that LLM evaluators such as GPT-4 struggle to detect actual deficiencies in dialogues generated by current LLM chatbots.
Read more7/8/2024

0
Towards Optimizing and Evaluating a Retrieval Augmented QA Chatbot using LLMs with Human in the Loop
Anum Afzal, Alexander Kowsik, Rajna Fani, Florian Matthes
Large Language Models have found application in various mundane and repetitive tasks including Human Resource (HR) support. We worked with the domain experts of SAP SE to develop an HR support chatbot as an efficient and effective tool for addressing employee inquiries. We inserted a human-in-the-loop in various parts of the development cycles such as dataset collection, prompt optimization, and evaluation of generated output. By enhancing the LLM-driven chatbot's response quality and exploring alternative retrieval methods, we have created an efficient, scalable, and flexible tool for HR professionals to address employee inquiries effectively. Our experiments and evaluation conclude that GPT-4 outperforms other models and can overcome inconsistencies in data through internal reasoning capabilities. Additionally, through expert analysis, we infer that reference-free evaluation metrics such as G-Eval and Prometheus demonstrate reliability closely aligned with that of human evaluation.
Read more7/9/2024
👨🏫
0
Building Trust in Mental Health Chatbots: Safety Metrics and LLM-Based Evaluation Tools
Jung In Park, Mahyar Abbasian, Iman Azimi, Dawn Bounds, Angela Jun, Jaesu Han, Robert McCarron, Jessica Borelli, Jia Li, Mona Mahmoudi, Carmen Wiedenhoeft, Amir Rahmani
Objective: This study aims to develop and validate an evaluation framework to ensure the safety and reliability of mental health chatbots, which are increasingly popular due to their accessibility, human-like interactions, and context-aware support. Materials and Methods: We created an evaluation framework with 100 benchmark questions and ideal responses, and five guideline questions for chatbot responses. This framework, validated by mental health experts, was tested on a GPT-3.5-turbo-based chatbot. Automated evaluation methods explored included large language model (LLM)-based scoring, an agentic approach using real-time data, and embedding models to compare chatbot responses against ground truth standards. Results: The results highlight the importance of guidelines and ground truth for improving LLM evaluation accuracy. The agentic method, dynamically accessing reliable information, demonstrated the best alignment with human assessments. Adherence to a standardized, expert-validated framework significantly enhanced chatbot response safety and reliability. Discussion: Our findings emphasize the need for comprehensive, expert-tailored safety evaluation metrics for mental health chatbots. While LLMs have significant potential, careful implementation is necessary to mitigate risks. The superior performance of the agentic approach underscores the importance of real-time data access in enhancing chatbot reliability. Conclusion: The study validated an evaluation framework for mental health chatbots, proving its effectiveness in improving safety and reliability. Future work should extend evaluations to accuracy, bias, empathy, and privacy to ensure holistic assessment and responsible integration into healthcare. Standardized evaluations will build trust among users and professionals, facilitating broader adoption and improved mental health support through technology.
Read more8/12/2024