SVIPTR: Fast and Efficient Scene Text Recognition with Vision Permutable Extractor

0
Sign in to get full access
Overview
- VIPTR is a novel vision permutable extractor for fast and efficient scene text recognition
- It introduces a new vision module that can be easily plugged into existing scene text recognition models
- The module leverages the strengths of both convolutional neural networks (CNNs) and vision transformers (VTs) to achieve high accuracy and inference speed
Plain English Explanation
The paper presents a new [VIPTR: A Vision Permutable Extractor for Fast and Efficient Scene Text Recognition] model for [scene text recognition], which is the task of understanding and extracting text from images of real-world scenes.
The key idea behind VIPTR is to combine the strengths of [convolutional neural networks (CNNs)] and [vision transformers (VTs)] into a single module that can be easily integrated into existing scene text recognition models. CNNs are known for their ability to efficiently capture local visual features, while VTs excel at modeling long-range dependencies and global information.
VIPTR aims to leverage the best of both worlds to achieve [high accuracy] and [fast inference speed] in scene text recognition. By making the vision module [permutable], the model can be readily adapted to different scene text recognition architectures, providing a flexible and efficient solution.
Technical Explanation
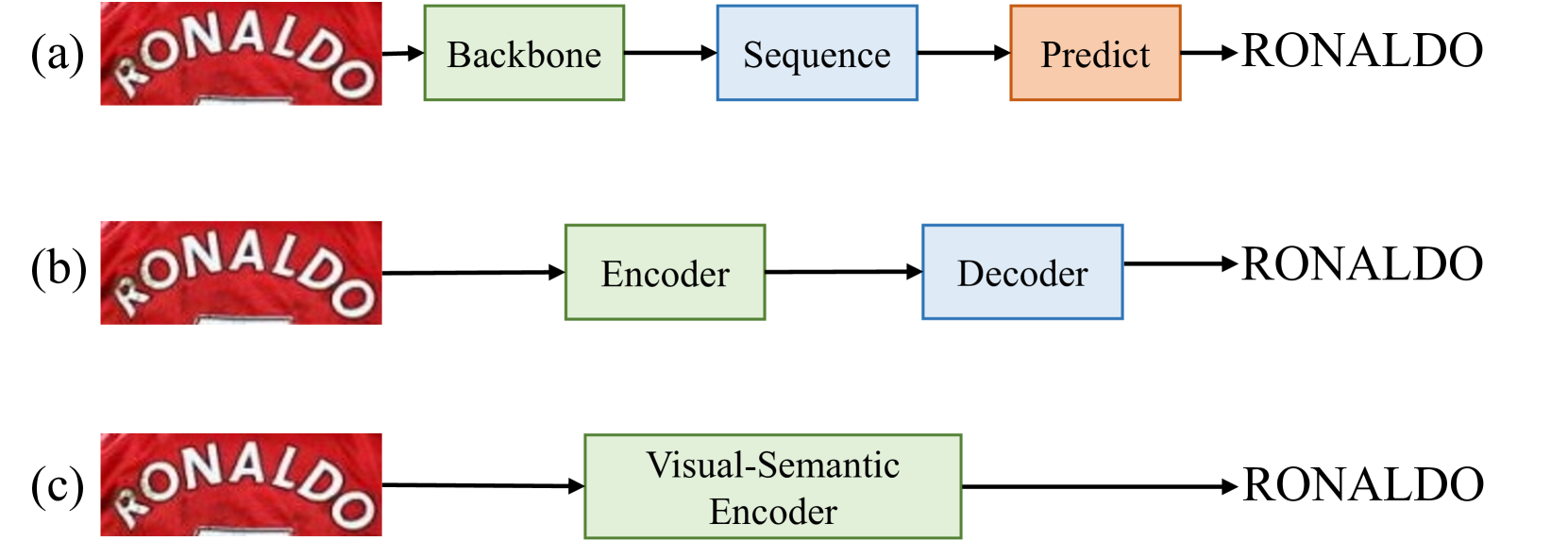
The VIPTR model consists of two main components: a [CNN-based backbone] and a [transformer-based vision module]. The CNN backbone is responsible for extracting initial visual features from the input image, while the transformer-based vision module further refines and aggregates these features to capture both local and global information.
The key innovation of VIPTR lies in the [vision permutable extractor], which allows the transformer-based vision module to be easily incorporated into existing scene text recognition models. This is achieved by designing the transformer-based module to operate on the feature maps produced by the CNN backbone, rather than directly on the input image.
The authors conducted [extensive experiments] to evaluate the performance of VIPTR on several benchmark datasets for scene text recognition. The results demonstrate that VIPTR outperforms state-of-the-art models in terms of both [accuracy] and [inference speed], making it a promising solution for real-world applications.
Critical Analysis
The paper provides a well-designed and thoroughly evaluated [VIPTR] model for scene text recognition. The authors' approach of combining the strengths of CNNs and transformers is a promising direction, and the [vision permutable extractor] is an innovative concept that allows for flexible integration into different scene text recognition architectures.
However, the paper does not address certain [limitations] and potential [areas for further research]. For example, the authors do not discuss the [computational complexity] of the transformer-based vision module and how it might impact the overall efficiency of the model, especially for [resource-constrained devices].
Additionally, the paper could have [explored the generalization capabilities] of VIPTR, such as its performance on [diverse datasets] or its [robustness to different types of scene text], to better understand the model's broader applicability.
Overall, the VIPTR model presents an interesting and effective approach to scene text recognition, but further research and analysis could help address some of the potential limitations and provide a more comprehensive understanding of the model's strengths and weaknesses.
Conclusion
The [VIPTR] model introduced in this paper offers a novel and efficient solution for [scene text recognition]. By [combining the strengths of CNNs and transformers] in a [vision permutable extractor], the model achieves [high accuracy] and [fast inference speed], making it a promising candidate for real-world applications.
The paper's technical contributions and experimental results demonstrate the potential of [hybrid vision models] that leverage the complementary capabilities of different neural network architectures. As the field of computer vision continues to evolve, approaches like VIPTR may pave the way for more [flexible and efficient scene text recognition systems], with important implications for tasks like [document digitization], [assistive technology], and [urban planning].
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SVIPTR: Fast and Efficient Scene Text Recognition with Vision Permutable Extractor
Xianfu Cheng, Weixiao Zhou, Xiang Li, Jian Yang, Hang Zhang, Tao Sun, Wei Zhang, Yuying Mai, Tongliang Li, Xiaoming Chen, Zhoujun Li
Scene Text Recognition (STR) is an important and challenging upstream task for building structured information databases, that involves recognizing text within images of natural scenes. Although current state-of-the-art (SOTA) models for STR exhibit high performance, they typically suffer from low inference efficiency due to their reliance on hybrid architectures comprised of visual encoders and sequence decoders. In this work, we propose a VIsion Permutable extractor for fast and efficient Scene Text Recognition (SVIPTR), which achieves an impressive balance between high performance and rapid inference speeds in the domain of STR. Specifically, SVIPTR leverages a visual-semantic extractor with a pyramid structure, characterized by the Permutation and combination of local and global self-attention layers. This design results in a lightweight and efficient model and its inference is insensitive to input length. Extensive experimental results on various standard datasets for both Chinese and English scene text recognition validate the superiority of SVIPTR. Notably, the SVIPTR-T (Tiny) variant delivers highly competitive accuracy on par with other lightweight models and achieves SOTA inference speeds. Meanwhile, the SVIPTR-L (Large) attains SOTA accuracy in single-encoder-type models, while maintaining a low parameter count and favorable inference speed. Our proposed method provides a compelling solution for the STR challenge, which greatly benefits real-world applications requiring fast and efficient STR. The code is publicly available at https://github.com/cxfyxl/VIPTR.
Read more8/21/2024
👁️
0
CLIP4STR: A Simple Baseline for Scene Text Recognition with Pre-trained Vision-Language Model
Shuai Zhao, Ruijie Quan, Linchao Zhu, Yi Yang
Pre-trained vision-language models~(VLMs) are the de-facto foundation models for various downstream tasks. However, scene text recognition methods still prefer backbones pre-trained on a single modality, namely, the visual modality, despite the potential of VLMs to serve as powerful scene text readers. For example, CLIP can robustly identify regular (horizontal) and irregular (rotated, curved, blurred, or occluded) text in images. With such merits, we transform CLIP into a scene text reader and introduce CLIP4STR, a simple yet effective STR method built upon image and text encoders of CLIP. It has two encoder-decoder branches: a visual branch and a cross-modal branch. The visual branch provides an initial prediction based on the visual feature, and the cross-modal branch refines this prediction by addressing the discrepancy between the visual feature and text semantics. To fully leverage the capabilities of both branches, we design a dual predict-and-refine decoding scheme for inference. We scale CLIP4STR in terms of the model size, pre-training data, and training data, achieving state-of-the-art performance on 11 STR benchmarks. Additionally, a comprehensive empirical study is provided to enhance the understanding of the adaptation of CLIP to STR. We believe our method establishes a simple yet strong baseline for future STR research with VLMs.
Read more5/3/2024
0
Decoder Pre-Training with only Text for Scene Text Recognition
Shuai Zhao, Yongkun Du, Zhineng Chen, Yu-Gang Jiang
Scene text recognition (STR) pre-training methods have achieved remarkable progress, primarily relying on synthetic datasets. However, the domain gap between synthetic and real images poses a challenge in acquiring feature representations that align well with images on real scenes, thereby limiting the performance of these methods. We note that vision-language models like CLIP, pre-trained on extensive real image-text pairs, effectively align images and text in a unified embedding space, suggesting the potential to derive the representations of real images from text alone. Building upon this premise, we introduce a novel method named Decoder Pre-training with only text for STR (DPTR). DPTR treats text embeddings produced by the CLIP text encoder as pseudo visual embeddings and uses them to pre-train the decoder. An Offline Randomized Perturbation (ORP) strategy is introduced. It enriches the diversity of text embeddings by incorporating natural image embeddings extracted from the CLIP image encoder, effectively directing the decoder to acquire the potential representations of real images. In addition, we introduce a Feature Merge Unit (FMU) that guides the extracted visual embeddings focusing on the character foreground within the text image, thereby enabling the pre-trained decoder to work more efficiently and accurately. Extensive experiments across various STR decoders and language recognition tasks underscore the broad applicability and remarkable performance of DPTR, providing a novel insight for STR pre-training. Code is available at https://github.com/Topdu/OpenOCR
Read more8/13/2024
👁️
0
Instruction-Guided Scene Text Recognition
Yongkun Du, Zhineng Chen, Yuchen Su, Caiyan Jia, Yu-Gang Jiang
Multi-modal models show appealing performance in visual recognition tasks recently, as free-form text-guided training evokes the ability to understand fine-grained visual content. However, current models are either inefficient or cannot be trivially upgraded to scene text recognition (STR) due to the composition difference between natural and text images. We propose a novel instruction-guided scene text recognition (IGTR) paradigm that formulates STR as an instruction learning problem and understands text images by predicting character attributes, e.g., character frequency, position, etc. IGTR first devises $left langle condition,question,answerright rangle$ instruction triplets, providing rich and diverse descriptions of character attributes. To effectively learn these attributes through question-answering, IGTR develops lightweight instruction encoder, cross-modal feature fusion module and multi-task answer head, which guides nuanced text image understanding. Furthermore, IGTR realizes different recognition pipelines simply by using different instructions, enabling a character-understanding-based text reasoning paradigm that considerably differs from current methods. Experiments on English and Chinese benchmarks show that IGTR outperforms existing models by significant margins, while maintaining a small model size and efficient inference speed. Moreover, by adjusting the sampling of instructions, IGTR offers an elegant way to tackle the recognition of both rarely appearing and morphologically similar characters, which were previous challenges. Code at href{https://github.com/Topdu/OpenOCR}{this http URL}.
Read more7/2/2024