CLIP4STR: A Simple Baseline for Scene Text Recognition with Pre-trained Vision-Language Model

0
👁️
Sign in to get full access
Overview
- Pre-trained vision-language models (VLMs) are powerful foundation models for various tasks, but scene text recognition (STR) methods often prefer single-modality visual backbones.
- CLIP, a popular VLM, can robustly identify both regular and irregular text in images, suggesting it could be a powerful STR tool.
- The paper introduces CLIP4STR, a simple yet effective STR method that builds on CLIP's image and text encoders.
Plain English Explanation
The paper focuses on pre-trained vision-language models, which are AI models that have been trained on a large amount of visual and textual data. These models have become the foundation for many different AI applications, as they can understand and process both images and text very well.
However, when it comes to the specific task of scene text recognition (STR) - which is about identifying and reading text within images - the researchers found that existing methods often use AI models that have only been trained on visual data, rather than the more powerful vision-language models.
The researchers show that one of these vision-language models, called CLIP, can actually do a great job at identifying both regular and irregular text in images, even text that is rotated, blurred, or partially obscured. This suggests that CLIP could be a very useful foundation for building STR systems.
So the researchers took CLIP and turned it into a new STR method called CLIP4STR. CLIP4STR has two main parts: a visual branch that makes an initial prediction based on the image, and a cross-modal branch that refines that prediction by considering the relationship between the visual features and the textual semantics.
By combining these two branches in a clever way, the researchers were able to create a simple yet powerful STR system that achieves state-of-the-art performance on a variety of STR benchmarks. They also did a thorough analysis to better understand how CLIP can be adapted for the STR task.
Technical Explanation
The paper introduces CLIP4STR, a scene text recognition (STR) method that leverages the capabilities of the pre-trained CLIP vision-language model.
CLIP4STR has two encoder-decoder branches:
- Visual Branch: This branch provides an initial prediction based solely on the visual features of the input image.
- Cross-Modal Branch: This branch refines the initial prediction by considering the discrepancy between the visual features and the text semantics.
To fully utilize the strengths of both branches, the researchers designed a "dual predict-and-refine" decoding scheme for inference. This allows the model to iteratively improve its text predictions by alternating between the visual and cross-modal branches.
The researchers scaled CLIP4STR by increasing the model size, pre-training data, and training data, which enabled the model to achieve state-of-the-art performance on 11 different STR benchmarks.
Additionally, the paper provides a comprehensive empirical study on the adaptation of CLIP to the STR task, exploring various design choices and their impact on performance. This helps to enhance the understanding of how vision-language models can be effectively leveraged for scene text recognition.
Critical Analysis
The paper demonstrates the potential of pre-trained vision-language models, like CLIP, to serve as powerful foundations for scene text recognition tasks. By building on CLIP's robust text understanding capabilities, the researchers were able to create a simple yet effective STR method that outperforms existing approaches.
However, the paper does acknowledge some limitations and areas for future research:
- The authors note that while CLIP4STR achieves state-of-the-art performance, there is still room for improvement, especially on more challenging STR benchmarks.
- The paper does not delve deeply into the potential biases or limitations of the underlying CLIP model, which could impact the performance and fairness of the CLIP4STR system.
- The researchers suggest that further investigation is needed to better understand the inner workings of the cross-modal branch and its role in refining the text predictions.
Additionally, one could question whether the significant computational and data requirements for scaling CLIP4STR might limit its practical applicability, especially for resource-constrained scenarios.
Overall, the paper makes a compelling case for the use of vision-language models in scene text recognition, but also highlights the need for continued research to address the remaining challenges and limitations.
Conclusion
The paper presents CLIP4STR, a novel scene text recognition method that leverages the powerful capabilities of the CLIP vision-language model. By combining a visual branch and a cross-modal branch, CLIP4STR is able to achieve state-of-the-art performance on a wide range of STR benchmarks.
This work demonstrates the potential of pre-trained vision-language models to serve as versatile foundations for various downstream tasks, including those traditionally dominated by single-modality approaches. The comprehensive analysis provided in the paper also enhances our understanding of how to effectively adapt these powerful models to specialized applications like scene text recognition.
While CLIP4STR represents an important step forward, the researchers acknowledge that there is still room for improvement, particularly in addressing the limitations and biases of the underlying CLIP model. Continued research in this direction could lead to even more robust and generalizable scene text recognition systems that can benefit a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
CLIP4STR: A Simple Baseline for Scene Text Recognition with Pre-trained Vision-Language Model
Shuai Zhao, Ruijie Quan, Linchao Zhu, Yi Yang
Pre-trained vision-language models~(VLMs) are the de-facto foundation models for various downstream tasks. However, scene text recognition methods still prefer backbones pre-trained on a single modality, namely, the visual modality, despite the potential of VLMs to serve as powerful scene text readers. For example, CLIP can robustly identify regular (horizontal) and irregular (rotated, curved, blurred, or occluded) text in images. With such merits, we transform CLIP into a scene text reader and introduce CLIP4STR, a simple yet effective STR method built upon image and text encoders of CLIP. It has two encoder-decoder branches: a visual branch and a cross-modal branch. The visual branch provides an initial prediction based on the visual feature, and the cross-modal branch refines this prediction by addressing the discrepancy between the visual feature and text semantics. To fully leverage the capabilities of both branches, we design a dual predict-and-refine decoding scheme for inference. We scale CLIP4STR in terms of the model size, pre-training data, and training data, achieving state-of-the-art performance on 11 STR benchmarks. Additionally, a comprehensive empirical study is provided to enhance the understanding of the adaptation of CLIP to STR. We believe our method establishes a simple yet strong baseline for future STR research with VLMs.
Read more5/3/2024
0
Decoder Pre-Training with only Text for Scene Text Recognition
Shuai Zhao, Yongkun Du, Zhineng Chen, Yu-Gang Jiang
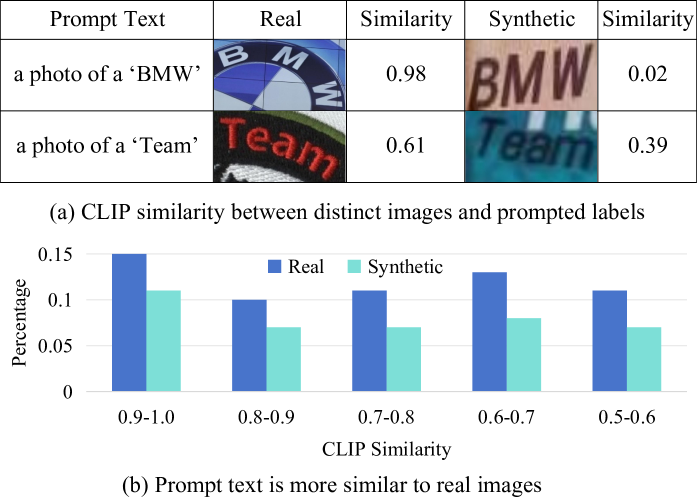
Scene text recognition (STR) pre-training methods have achieved remarkable progress, primarily relying on synthetic datasets. However, the domain gap between synthetic and real images poses a challenge in acquiring feature representations that align well with images on real scenes, thereby limiting the performance of these methods. We note that vision-language models like CLIP, pre-trained on extensive real image-text pairs, effectively align images and text in a unified embedding space, suggesting the potential to derive the representations of real images from text alone. Building upon this premise, we introduce a novel method named Decoder Pre-training with only text for STR (DPTR). DPTR treats text embeddings produced by the CLIP text encoder as pseudo visual embeddings and uses them to pre-train the decoder. An Offline Randomized Perturbation (ORP) strategy is introduced. It enriches the diversity of text embeddings by incorporating natural image embeddings extracted from the CLIP image encoder, effectively directing the decoder to acquire the potential representations of real images. In addition, we introduce a Feature Merge Unit (FMU) that guides the extracted visual embeddings focusing on the character foreground within the text image, thereby enabling the pre-trained decoder to work more efficiently and accurately. Extensive experiments across various STR decoders and language recognition tasks underscore the broad applicability and remarkable performance of DPTR, providing a novel insight for STR pre-training. Code is available at https://github.com/Topdu/OpenOCR
Read more8/13/2024
0
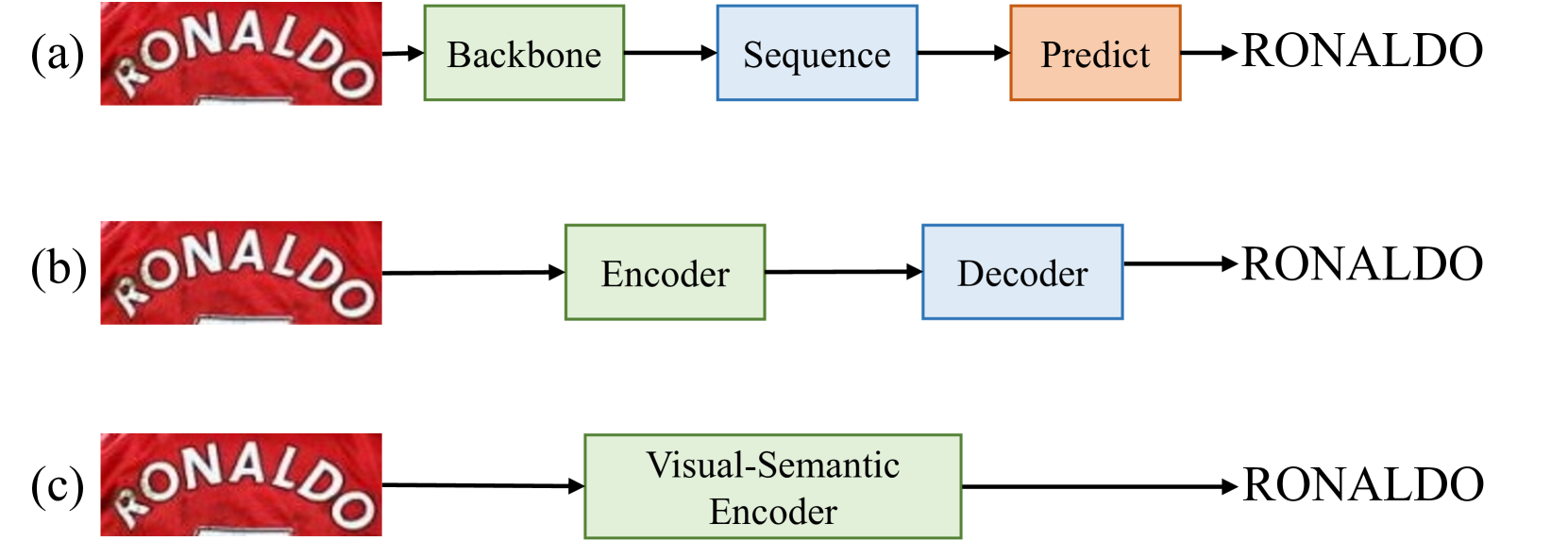
SVIPTR: Fast and Efficient Scene Text Recognition with Vision Permutable Extractor
Xianfu Cheng, Weixiao Zhou, Xiang Li, Jian Yang, Hang Zhang, Tao Sun, Wei Zhang, Yuying Mai, Tongliang Li, Xiaoming Chen, Zhoujun Li
Scene Text Recognition (STR) is an important and challenging upstream task for building structured information databases, that involves recognizing text within images of natural scenes. Although current state-of-the-art (SOTA) models for STR exhibit high performance, they typically suffer from low inference efficiency due to their reliance on hybrid architectures comprised of visual encoders and sequence decoders. In this work, we propose a VIsion Permutable extractor for fast and efficient Scene Text Recognition (SVIPTR), which achieves an impressive balance between high performance and rapid inference speeds in the domain of STR. Specifically, SVIPTR leverages a visual-semantic extractor with a pyramid structure, characterized by the Permutation and combination of local and global self-attention layers. This design results in a lightweight and efficient model and its inference is insensitive to input length. Extensive experimental results on various standard datasets for both Chinese and English scene text recognition validate the superiority of SVIPTR. Notably, the SVIPTR-T (Tiny) variant delivers highly competitive accuracy on par with other lightweight models and achieves SOTA inference speeds. Meanwhile, the SVIPTR-L (Large) attains SOTA accuracy in single-encoder-type models, while maintaining a low parameter count and favorable inference speed. Our proposed method provides a compelling solution for the STR challenge, which greatly benefits real-world applications requiring fast and efficient STR. The code is publicly available at https://github.com/cxfyxl/VIPTR.
Read more8/21/2024
0
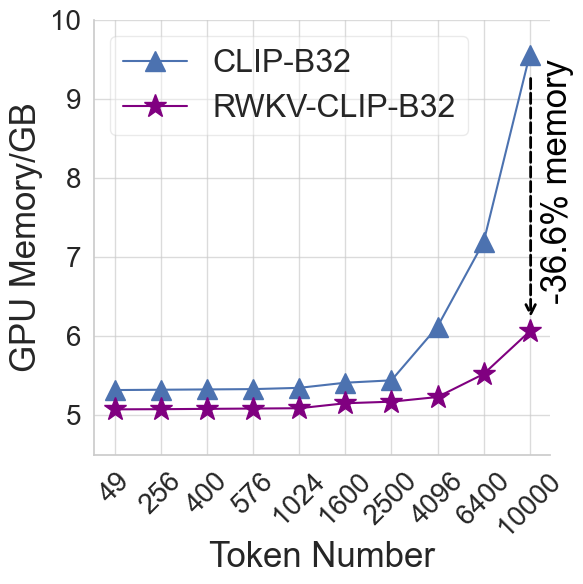
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
Read more6/12/2024