Swin-LiteMedSAM: A Lightweight Box-Based Segment Anything Model for Large-Scale Medical Image Datasets

0

Sign in to get full access
Overview
- Swin-LiteMedSAM is a lightweight, box-based Segment Anything Model (SAM) for large-scale medical image datasets.
- It uses a Swin Transformer architecture and supports multiple prompts to segment objects in medical images.
- The model is designed to be computationally efficient and suitable for deployment on resource-constrained devices.
Plain English Explanation
Swin-LiteMedSAM is a new AI system that can automatically identify and outline different objects in medical images, such as organs or tumors. Unlike previous models, Swin-LiteMedSAM is lightweight and efficient, making it well-suited for use on devices with limited computing power, like those found in hospitals or clinics.
The key innovation of Swin-LiteMedSAM is its use of a Swin Transformer architecture, which allows the model to process images more effectively than traditional approaches. Additionally, Swin-LiteMedSAM supports the use of multiple prompts, which means the user can provide various types of instructions or cues to guide the model's segmentation process.
By being lightweight and flexible, Swin-LiteMedSAM has the potential to make it easier for medical professionals to quickly and accurately identify relevant structures in medical images, which could lead to more efficient diagnoses and better patient outcomes.
Technical Explanation
Swin-LiteMedSAM is a novel Segment Anything Model (SAM) that uses a Swin Transformer architecture to provide efficient and accurate segmentation of objects in medical images. The model is designed to be computationally lightweight, making it suitable for deployment on resource-constrained devices commonly found in healthcare settings.
The key features of Swin-LiteMedSAM include:
-
Swin Transformer Architecture: The model employs a Swin Transformer, which has been shown to outperform traditional convolutional neural networks in various computer vision tasks. The Swin Transformer's efficient design and attention mechanisms allow it to effectively process and segment medical images.
-
Box-Based Segmentation: Swin-LiteMedSAM uses a box-based approach to segmentation, which means it first identifies bounding boxes around objects of interest and then refines the segmentation within those boxes. This approach is more computationally efficient than pixel-wise segmentation.
-
Multiple Prompts: The model supports the use of multiple prompts, which are textual or visual cues that guide the segmentation process. This flexibility allows medical professionals to customize the segmentation according to their specific needs or preferences.
The authors of the paper evaluate Swin-LiteMedSAM on several large-scale medical image datasets, demonstrating its superior performance in terms of segmentation accuracy and computational efficiency compared to other state-of-the-art SAM models.
Critical Analysis
The Swin-LiteMedSAM paper presents a promising approach to efficient and accurate object segmentation in medical images. The use of a Swin Transformer architecture and the box-based segmentation method are well-justified design choices that contribute to the model's computational efficiency.
However, the paper does not provide a comprehensive analysis of the model's performance on a wide range of medical image datasets or its ability to handle diverse types of medical objects. Additional studies evaluating Swin-LiteMedSAM on more varied datasets and use cases would be valuable to further assess its robustness and generalizability.
Moreover, the paper does not address potential limitations or challenges related to the deployment of Swin-LiteMedSAM in real-world clinical settings, such as the need for user-friendly interfaces, integration with existing medical imaging systems, and potential ethical concerns around the use of AI-powered segmentation tools in healthcare.
Overall, the Swin-LiteMedSAM model represents a promising step forward in the development of efficient and practical medical image segmentation tools, but further research and consideration of deployment-related factors would help to strengthen the practical impact of this work.
Conclusion
Swin-LiteMedSAM is a novel, lightweight Segment Anything Model that leverages a Swin Transformer architecture and a box-based segmentation approach to enable efficient and accurate object segmentation in medical images. By being computationally efficient, the model has the potential to be deployed on resource-constrained devices commonly found in healthcare settings, potentially leading to more timely and accurate diagnoses.
The key innovations of Swin-LiteMedSAM, such as its use of a Swin Transformer and support for multiple prompts, demonstrate the model's flexibility and adaptability to the needs of medical professionals. As the field of medical image analysis continues to evolve, advancements like Swin-LiteMedSAM will play an increasingly important role in enhancing the capabilities of AI-powered tools to assist healthcare practitioners and improve patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Swin-LiteMedSAM: A Lightweight Box-Based Segment Anything Model for Large-Scale Medical Image Datasets
Ruochen Gao, Donghang Lyu, Marius Staring
Medical imaging is essential for the diagnosis and treatment of diseases, with medical image segmentation as a subtask receiving high attention. However, automatic medical image segmentation models are typically task-specific and struggle to handle multiple scenarios, such as different imaging modalities and regions of interest. With the introduction of the Segment Anything Model (SAM), training a universal model for various clinical scenarios has become feasible. Recently, several Medical SAM (MedSAM) methods have been proposed, but these models often rely on heavy image encoders to achieve high performance, which may not be practical for real-world applications due to their high computational demands and slow inference speed. To address this issue, a lightweight version of the MedSAM (LiteMedSAM) can provide a viable solution, achieving high performance while requiring fewer resources and less time. In this work, we introduce Swin-LiteMedSAM, a new variant of LiteMedSAM. This model integrates the tiny Swin Transformer as the image encoder, incorporates multiple types of prompts, including box-based points and scribble generated from a given bounding box, and establishes skip connections between the image encoder and the mask decoder. In the textit{Segment Anything in Medical Images on Laptop} challenge (CVPR 2024), our approach strikes a good balance between segmentation performance and speed, demonstrating significantly improved overall results across multiple modalities compared to the LiteMedSAM baseline provided by the challenge organizers. Our proposed model achieved a DSC score of textbf{0.8678} and an NSD score of textbf{0.8844} on the validation set. On the final test set, it attained a DSC score of textbf{0.8193} and an NSD score of textbf{0.8461}, securing fourth place in the challenge.
Read more9/12/2024

0
I-MedSAM: Implicit Medical Image Segmentation with Segment Anything
Xiaobao Wei, Jiajun Cao, Yizhu Jin, Ming Lu, Guangyu Wang, Shanghang Zhang
With the development of Deep Neural Networks (DNNs), many efforts have been made to handle medical image segmentation. Traditional methods such as nnUNet train specific segmentation models on the individual datasets. Plenty of recent methods have been proposed to adapt the foundational Segment Anything Model (SAM) to medical image segmentation. However, they still focus on discrete representations to generate pixel-wise predictions, which are spatially inflexible and scale poorly to higher resolution. In contrast, implicit methods learn continuous representations for segmentation, which is crucial for medical image segmentation. In this paper, we propose I-MedSAM, which leverages the benefits of both continuous representations and SAM, to obtain better cross-domain ability and accurate boundary delineation. Since medical image segmentation needs to predict detailed segmentation boundaries, we designed a novel adapter to enhance the SAM features with high-frequency information during Parameter-Efficient Fine-Tuning (PEFT). To convert the SAM features and coordinates into continuous segmentation output, we utilize Implicit Neural Representation (INR) to learn an implicit segmentation decoder. We also propose an uncertainty-guided sampling strategy for efficient learning of INR. Extensive evaluations on 2D medical image segmentation tasks have shown that our proposed method with only 1.6M trainable parameters outperforms existing methods including discrete and implicit methods. The code will be available at: https://github.com/ucwxb/I-MedSAM.
Read more7/12/2024

0
Segment Anything in Medical Images and Videos: Benchmark and Deployment
Jun Ma, Sumin Kim, Feifei Li, Mohammed Baharoon, Reza Asakereh, Hongwei Lyu, Bo Wang
Recent advances in segmentation foundation models have enabled accurate and efficient segmentation across a wide range of natural images and videos, but their utility to medical data remains unclear. In this work, we first present a comprehensive benchmarking of the Segment Anything Model 2 (SAM2) across 11 medical image modalities and videos and point out its strengths and weaknesses by comparing it to SAM1 and MedSAM. Then, we develop a transfer learning pipeline and demonstrate SAM2 can be quickly adapted to medical domain by fine-tuning. Furthermore, we implement SAM2 as a 3D slicer plugin and Gradio API for efficient 3D image and video segmentation. The code has been made publicly available at url{https://github.com/bowang-lab/MedSAM}.
Read more8/7/2024
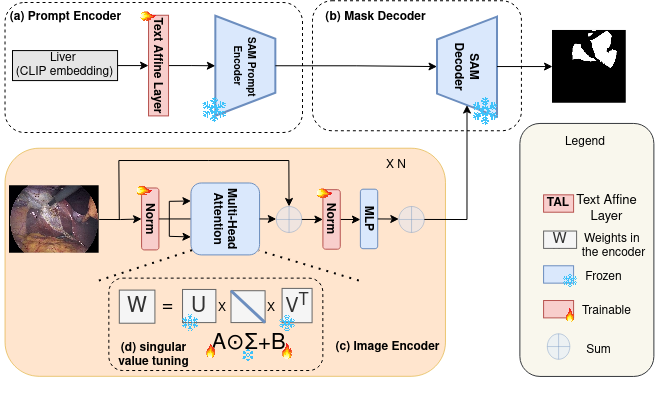
0
S-SAM: SVD-based Fine-Tuning of Segment Anything Model for Medical Image Segmentation
Jay N. Paranjape, Shameema Sikder, S. Swaroop Vedula, Vishal M. Patel
Medical image segmentation has been traditionally approached by training or fine-tuning the entire model to cater to any new modality or dataset. However, this approach often requires tuning a large number of parameters during training. With the introduction of the Segment Anything Model (SAM) for prompted segmentation of natural images, many efforts have been made towards adapting it efficiently for medical imaging, thus reducing the training time and resources. However, these methods still require expert annotations for every image in the form of point prompts or bounding box prompts during training and inference, making it tedious to employ them in practice. In this paper, we propose an adaptation technique, called S-SAM, that only trains parameters equal to 0.4% of SAM's parameters and at the same time uses simply the label names as prompts for producing precise masks. This not only makes tuning SAM more efficient than the existing adaptation methods but also removes the burden of providing expert prompts. We call this modified version S-SAM and evaluate it on five different modalities including endoscopic images, x-ray, ultrasound, CT, and histology images. Our experiments show that S-SAM outperforms state-of-the-art methods as well as existing SAM adaptation methods while tuning a significantly less number of parameters. We release the code for S-SAM at https://github.com/JayParanjape/SVDSAM.
Read more8/14/2024