SwitchCIT: Switching for Continual Instruction Tuning of Large Language Models

0

Sign in to get full access
Overview
- This paper introduces "SwitchCIT", a novel approach for continual instruction tuning of large language models.
- Continual instruction tuning is the process of fine-tuning a pre-trained language model on a sequence of different tasks or instructions, without forgetting previous knowledge.
- SwitchCIT aims to address the challenge of catastrophic forgetting in continual instruction tuning, where a model forgets previously learned skills when trained on new tasks.
Plain English Explanation
SwitchCIT is a method that helps large language models, like GPT-3, learn new skills and tasks continuously without forgetting what they've learned before. This is an important problem, known as catastrophic forgetting, that occurs when AI models are trained on a sequence of tasks.
Imagine you're trying to teach a child multiple skills, like math and music, one after the other. If the child forgets what they learned in math when you start teaching them music, that would be like catastrophic forgetting. SwitchCIT aims to prevent this by allowing the language model to "switch" between different skills and tasks without losing what it's already learned.
The key idea is to add a special "switching" mechanism to the model that helps it keep track of and easily recall previous knowledge, even as it's learning new things. This allows the model to continuously expand its capabilities without forgetting the foundations it's built upon.
Technical Explanation
SwitchCIT builds upon prior work on continual learning in large language models and multimodal continual instruction tuning.
The core of the SwitchCIT approach is a switching mechanism that allows the model to dynamically allocate different sets of parameters for different instructions or tasks. This prevents catastrophic forgetting by ensuring that learning new tasks doesn't interfere with or overwrite the knowledge gained from previous tasks.
Specifically, SwitchCIT uses a "task-specific adapter" module that is appended to the language model's backbone. This adapter learns task-specific representations, while the backbone model retains general language understanding capabilities. When the model switches to a new task, it can quickly adapt the task-specific adapter without disrupting the backbone.
The authors also introduce techniques for zero-shot cross-lingual transfer of instruction-following skills, allowing the model to apply its learned capabilities to new languages without additional fine-tuning.
Critical Analysis
The SwitchCIT approach appears to be a promising solution for enabling continual instruction tuning of large language models. The authors provide strong empirical results on a range of benchmarks, demonstrating SwitchCIT's effectiveness at mitigating catastrophic forgetting.
However, the paper does not address several important limitations and potential concerns:
- The computational and memory overhead of the task-specific adapter modules may limit scalability to a large number of tasks.
- The reliance on task-specific adapters may hinder the model's ability to learn shared representations across tasks, potentially limiting the transfer of knowledge.
- The paper focuses on instruction-following tasks and does not explore the performance of SwitchCIT on other types of language understanding and generation tasks.
Further research is needed to address these limitations and explore the broader applicability of the SwitchCIT approach, particularly in real-world settings with more diverse and dynamic task distributions.
Conclusion
The SwitchCIT paper presents an innovative approach to enabling continual instruction tuning of large language models. By introducing a switching mechanism that allows the model to dynamically allocate parameters for different tasks, SwitchCIT effectively mitigates the problem of catastrophic forgetting.
This work has important implications for the development of AI systems that can continuously expand their capabilities without losing previously acquired knowledge. As language models become increasingly integral to a wide range of applications, the ability to retrain and update them without degrading performance will be crucial.
While the current approach has some limitations, the underlying principles of SwitchCIT could inspire further advancements in continual learning for large language models and contribute to the creation of more versatile and adaptable AI assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SwitchCIT: Switching for Continual Instruction Tuning of Large Language Models
Xinbo Wu, Max Hartman, Vidhata Arjun Jayaraman, Lav R. Varshney
Large language models (LLMs) have exhibited impressive capabilities in various domains, particularly in general language understanding. However these models, trained on massive text data, may not be finely optimized for specific tasks triggered by instructions. Continual instruction tuning is crucial to adapt LLMs to evolving tasks and domains, ensuring their effectiveness and relevance across a wide range of applications. In the context of continual instruction tuning, where models are sequentially trained on different tasks, catastrophic forgetting can occur, leading to performance degradation on previously learned tasks. This work addresses the catastrophic forgetting in continual instruction learning for LLMs through a switching mechanism for routing computations to parameter-efficient tuned models. We demonstrate the effectiveness of our method through experiments on continual instruction tuning of different natural language generation tasks.
Read more7/17/2024
💬
0
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, Yue Zhang
Catastrophic forgetting (CF) is a phenomenon that occurs in machine learning when a model forgets previously learned information while acquiring new knowledge. As large language models (LLMs) have demonstrated remarkable performance, it is intriguing to investigate whether CF exists during the continual instruction tuning of LLMs. This study empirically evaluates the forgetting phenomenon in LLMs' knowledge during continual instruction tuning from the perspectives of domain knowledge, reasoning, and reading comprehension. The experiments reveal that catastrophic forgetting is generally observed in LLMs ranging from 1b to 7b parameters. Moreover, as the model scale increases, the severity of forgetting intensifies. Comparing the decoder-only model BLOOMZ with the encoder-decoder model mT0, BLOOMZ exhibits less forgetting and retains more knowledge. Interestingly, we also observe that LLMs can mitigate language biases, such as gender bias, during continual fine-tuning. Furthermore, our findings indicate that ALPACA maintains more knowledge and capacity compared to LLAMA during continual fine-tuning, suggesting that general instruction tuning can help alleviate the forgetting phenomenon in LLMs during subsequent fine-tuning processes.
Read more4/3/2024
💬
0
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, Hao Wang
The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as catastrophic forgetting. While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.
Read more7/2/2024
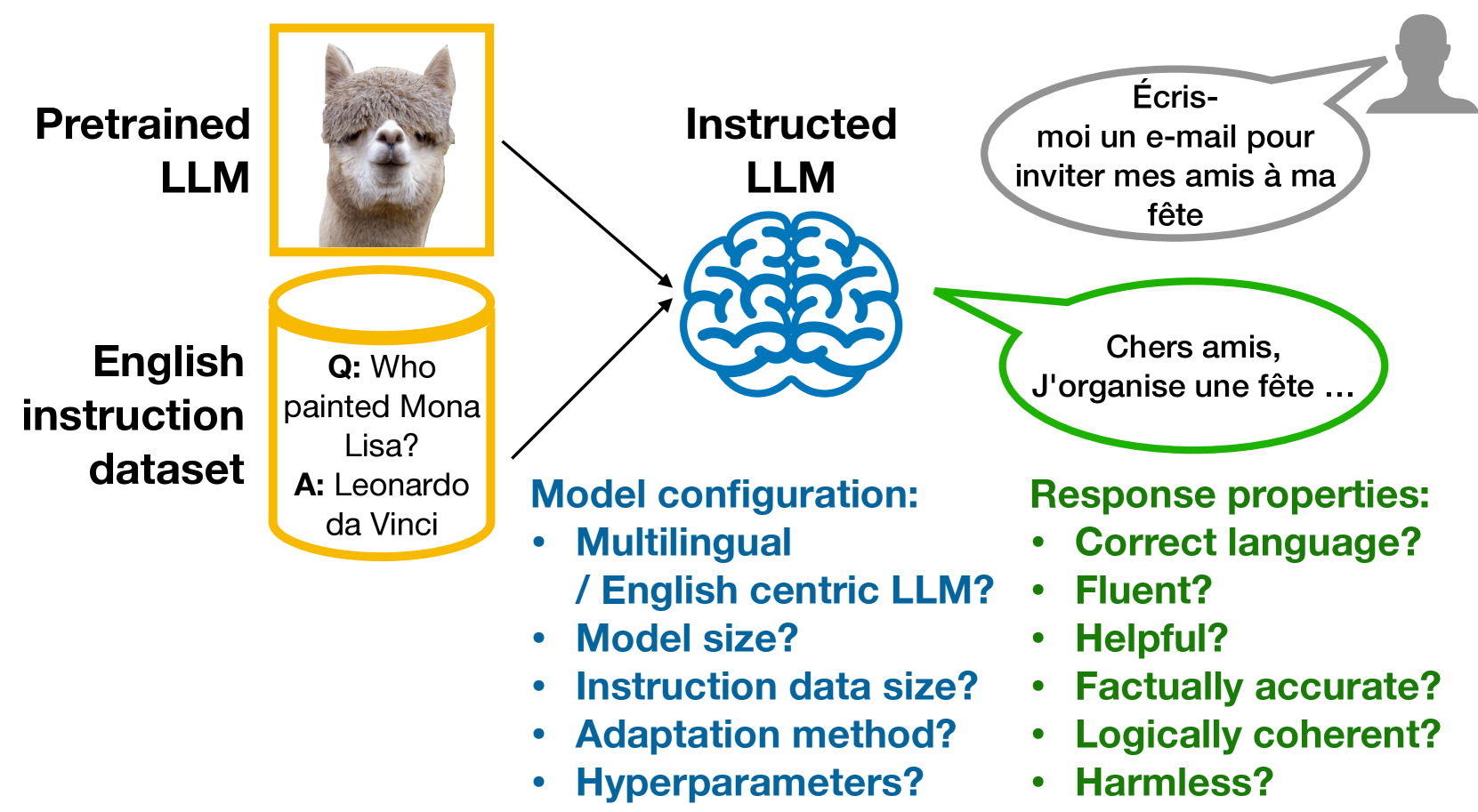
0
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
Read more4/23/2024