Zero-shot cross-lingual transfer in instruction tuning of large language models
2402.14778
0
0
Abstract
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
Create account to get full access
Overview
- This paper explores the ability of large language models to perform zero-shot cross-lingual transfer, where a model trained on instructions in one language can be applied to perform tasks in another language without additional fine-tuning.
- The researchers investigate techniques for "instruction tuning" - fine-tuning large language models on datasets of natural language instructions to enable them to follow instructions in a more robust and versatile way.
- Key findings include the ability to achieve strong cross-lingual performance on a wide range of tasks through careful instruction tuning, with potential applications in areas like multilingual virtual assistants and knowledge sharing across languages.
Plain English Explanation
Large language models like GPT-3 have shown impressive capabilities in understanding and generating human language. However, making these models truly multilingual - able to understand and follow instructions equally well in different languages - has remained a challenge.
This research paper examines ways to "train" these large models to be better at following instructions, not just in the language they were originally trained on, but in other languages as well. The key idea is "instruction tuning" - fine-tuning the model on datasets of natural language instructions covering a wide range of tasks.
The researchers found that with the right instruction tuning approach, these models can surprisingly perform well on instruction-following tasks in languages they weren't explicitly trained on. This "zero-shot" cross-lingual transfer could enable virtual assistants, knowledge sharing systems, and other applications to work seamlessly across languages.
While there are still limitations to address, this work represents an important step towards making large language models truly multilingual and universally useful, regardless of the user's native tongue. By focusing on instruction following, the models can learn to understand and execute a wide variety of tasks in a flexible, language-agnostic way.
Technical Explanation
The paper investigates techniques for instruction tuning of large language models to enable zero-shot cross-lingual transfer. Specifically, the authors train models on diverse instruction datasets in a source language (e.g. English), then evaluate their ability to follow instructions in a target language (e.g. French, Chinese) without any additional fine-tuning.
The authors experiment with different multilingual pretraining and instruction tuning strategies, including eliciting translation ability through prompting. They evaluate on a suite of cross-lingual instruction-following benchmarks covering diverse domains like arithmetic, common sense reasoning, and task completion.
The results demonstrate the ability to achieve strong zero-shot cross-lingual performance, outperforming prior approaches that relied on expensive multilingual fine-tuning. The authors attribute this success to the models' ability to learn robust, language-agnostic representations through careful instruction tuning.
Critical Analysis
The paper provides a thorough investigation of zero-shot cross-lingual transfer for instruction following, with a range of experiments and thoughtful analyses. However, some caveats and limitations are worth noting:
-
The evaluation datasets, while diverse, may not fully capture the breadth of real-world instruction-following challenges. More work is needed to test the models on a wider range of tasks and settings.
-
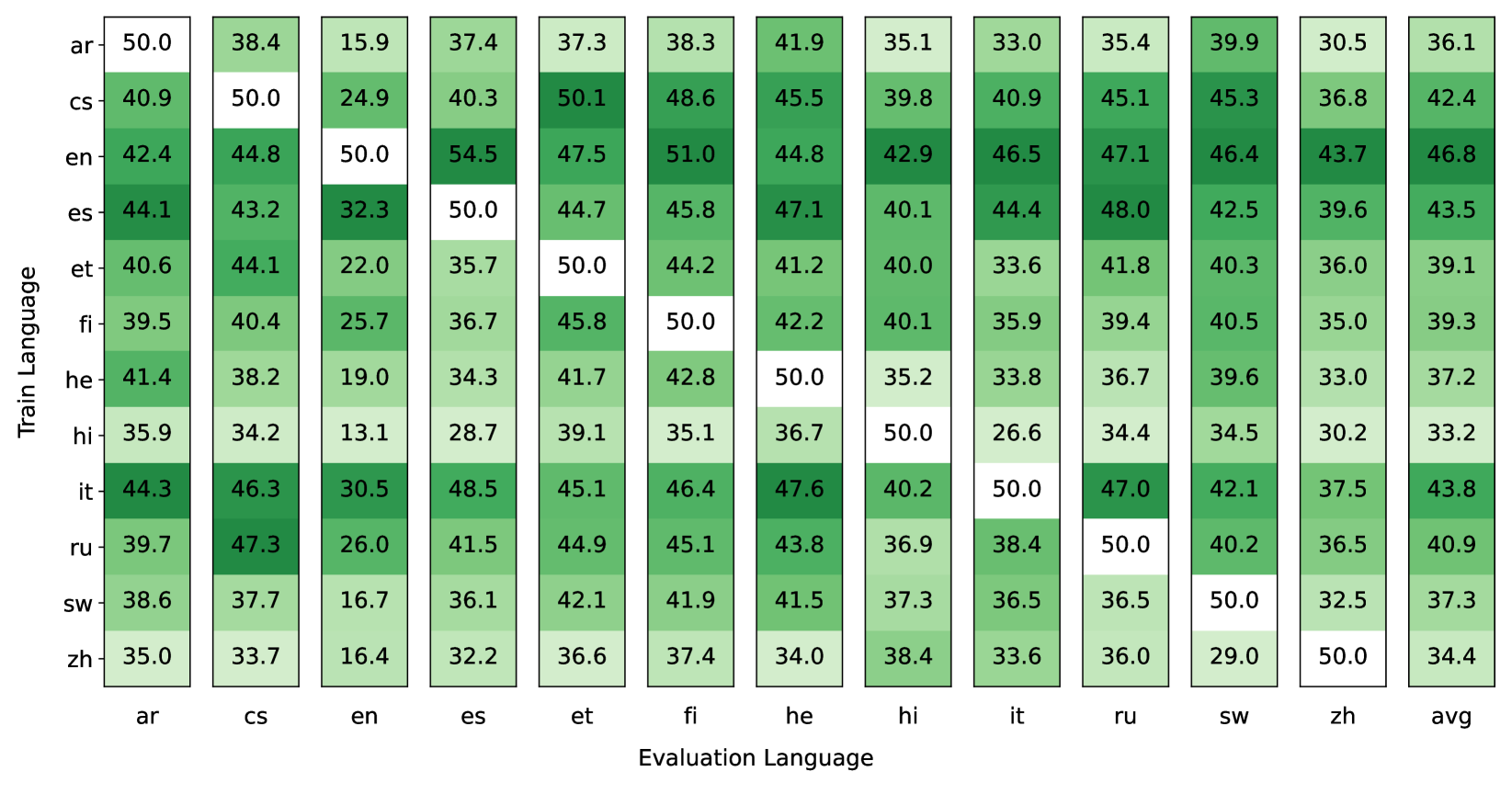
The paper does not explore the impact of the source and target language pairs, or how performance varies across different language combinations. This could provide helpful insights for practical deployment.
-
While the models exhibit strong zero-shot transfer, there is still a performance gap compared to models fine-tuned on target language data. Narrowing this gap remains an open challenge.
-
The instruction tuning approach relies on carefully curated datasets, which may be difficult to obtain for all languages of interest. Techniques for cross-lingual knowledge transfer could help address this limitation.
Overall, this work represents an important step forward in making large language models more multilingual and versatile. However, continued research is needed to further improve cross-lingual instruction following and unlock the full potential of these models for practical applications.
Conclusion
This paper demonstrates the potential of "instruction tuning" to enable large language models to perform well on instruction-following tasks in languages they were not explicitly trained on. By learning robust, language-agnostic representations through exposure to diverse natural language instructions, the models can successfully transfer their skills to new languages in a zero-shot manner.
The findings have promising implications for building more versatile and multilingual AI systems, such as virtual assistants and knowledge-sharing platforms that can seamlessly operate across languages. While challenges remain, this work represents an important step towards making large language models truly universal tools, capable of understanding and executing instructions regardless of the user's native tongue.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Multilingual Instruction Tuning With Just a Pinch of Multilinguality
Uri Shaham, Jonathan Herzig, Roee Aharoni, Idan Szpektor, Reut Tsarfaty, Matan Eyal
0
0
As instruction-tuned large language models (LLMs) gain global adoption, their ability to follow instructions in multiple languages becomes increasingly crucial. In this work, we investigate how multilinguality during instruction tuning of a multilingual LLM affects instruction-following across languages from the pre-training corpus. We first show that many languages transfer some instruction-following capabilities to other languages from even monolingual tuning. Furthermore, we find that only 40 multilingual examples integrated in an English tuning set substantially improve multilingual instruction-following, both in seen and unseen languages during tuning. In general, we observe that models tuned on multilingual mixtures exhibit comparable or superior performance in multiple languages compared to monolingually tuned models, despite training on 10x fewer examples in those languages. Finally, we find that diversifying the instruction tuning set with even just 2-4 languages significantly improves cross-lingual generalization. Our results suggest that building massively multilingual instruction-tuned models can be done with only a very small set of multilingual instruction-responses.
5/22/2024

X-Instruction: Aligning Language Model in Low-resource Languages with Self-curated Cross-lingual Instructions
Chong Li, Wen Yang, Jiajun Zhang, Jinliang Lu, Shaonan Wang, Chengqing Zong
0
0
Large language models respond well in high-resource languages like English but struggle in low-resource languages. It may arise from the lack of high-quality instruction following data in these languages. Directly translating English samples into these languages can be a solution but unreliable, leading to responses with translation errors and lacking language-specific or cultural knowledge. To address this issue, we propose a novel method to construct cross-lingual instruction following samples with instruction in English and response in low-resource languages. Specifically, the language model first learns to generate appropriate English instructions according to the natural web texts in other languages as responses. The candidate cross-lingual instruction tuning samples are further refined and diversified. We have employed this method to build a large-scale cross-lingual instruction tuning dataset on 10 languages, namely X-Instruction. The instruction data built using our method incorporate more language-specific knowledge compared with the naive translation method. Experimental results have shown that the response quality of the model tuned on X-Instruction greatly exceeds the model distilled from a powerful teacher model, reaching or even surpassing the ones of ChatGPT. In addition, we find that models tuned on cross-lingual instruction following samples can follow the instruction in the output language without further tuning.
5/31/2024

Deep Exploration of Cross-Lingual Zero-Shot Generalization in Instruction Tuning
Janghoon Han, Changho Lee, Joongbo Shin, Stanley Jungkyu Choi, Honglak Lee, Kynghoon Bae
0
0
Instruction tuning has emerged as a powerful technique, significantly boosting zero-shot performance on unseen tasks. While recent work has explored cross-lingual generalization by applying instruction tuning to multilingual models, previous studies have primarily focused on English, with a limited exploration of non-English tasks. For an in-depth exploration of cross-lingual generalization in instruction tuning, we perform instruction tuning individually for two distinct language meta-datasets. Subsequently, we assess the performance on unseen tasks in a language different from the one used for training. To facilitate this investigation, we introduce a novel non-English meta-dataset named KORANI (Korean Natural Instruction), comprising 51 Korean benchmarks. Moreover, we design cross-lingual templates to mitigate discrepancies in language and instruction-format of the template between training and inference within the cross-lingual setting. Our experiments reveal consistent improvements through cross-lingual generalization in both English and Korean, outperforming baseline by average scores of 20.7% and 13.6%, respectively. Remarkably, these enhancements are comparable to those achieved by monolingual instruction tuning and even surpass them in some tasks. The result underscores the significance of relevant data acquisition across languages over linguistic congruence with unseen tasks during instruction tuning.
6/14/2024
🔄
Key ingredients for effective zero-shot cross-lingual knowledge transfer in generative tasks
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Zero-shot cross-lingual knowledge transfer enables a multilingual pretrained language model, finetuned on a task in one language, make predictions for this task in other languages. While being broadly studied for natural language understanding tasks, the described setting is understudied for generation. Previous works notice a frequent problem of generation in a wrong language and propose approaches to address it, usually using mT5 as a backbone model. In this work we compare various approaches proposed from the literature in unified settings, also including alternative backbone models, namely mBART and NLLB-200. We first underline the importance of tuning learning rate used for finetuning, which helps to substantially alleviate the problem of generation in the wrong language. Then, we show that with careful learning rate tuning, the simple full finetuning of the model acts as a very strong baseline and alternative approaches bring only marginal improvements. Finally, we find that mBART performs similarly to mT5 of the same size, and NLLB-200 can be competitive in some cases. Our final zero-shot models reach the performance of the approach based on data translation which is usually considered as an upper baseline for zero-shot cross-lingual transfer in generation.
4/23/2024