Symmetric Replay Training: Enhancing Sample Efficiency in Deep Reinforcement Learning for Combinatorial Optimization

0
🤿
Sign in to get full access
Overview
- Deep reinforcement learning (DRL) has made significant advancements in combinatorial optimization, but it often requires a large number of reward evaluations, especially when dealing with computationally intensive tasks.
- To improve sample efficiency, the researchers propose a simple yet effective method called symmetric replay training (SRT) that can be easily integrated into various DRL algorithms.
- SRT leverages high-reward samples to encourage exploration of under-explored symmetric regions without additional online interactions, using replay training to maximize the likelihood of symmetric trajectories.
- Experiments show that SRT consistently improves sample efficiency across diverse DRL methods applied to real-world tasks like molecular optimization and hardware design.
Plain English Explanation
Deep reinforcement learning (DRL) is a powerful technique that has made great progress in solving complex optimization problems. However, one of its limitations is that it often requires a large number of reward evaluations, which can be very computationally intensive, especially for certain types of problems.
To address this issue, the researchers have developed a new method called symmetric replay training (SRT). The basic idea behind SRT is to leverage the information contained in high-reward samples to explore similar, but potentially underexplored, regions of the search space. This is done by training the DRL algorithm to maximize the likelihood of the symmetric trajectories of the discovered high-reward samples, without requiring any additional online interactions.
In other words, SRT allows the DRL algorithm to learn more efficiently from the best solutions it has found, by understanding the patterns and structures that lead to those high-reward outcomes. This helps the algorithm explore the search space more effectively, without having to start from scratch every time.
The researchers have tested SRT on a variety of real-world tasks, such as molecular optimization and hardware design, and have consistently found that it improves the sample efficiency of the DRL algorithms, compared to the standard approaches.
Technical Explanation
The key innovation of the proposed symmetric replay training (SRT) method is its ability to leverage high-reward samples to encourage exploration of under-explored symmetric regions, without requiring additional online interactions.
The researchers start by observing that many combinatorial optimization problems, such as molecular design and hardware layout, exhibit inherent symmetries. This means that there may be multiple solutions that are equivalent in terms of their objective function value, but differ in their representation.
SRT takes advantage of this by training the DRL policy to maximize the likelihood of the symmetric trajectories of the discovered high-reward samples. This is done through a replay training process, where the policy is updated to increase the probability of generating these symmetric trajectories, without having to interact with the environment again.
The researchers have integrated SRT into various DRL methods, including policy gradient and actor-critic algorithms, and have demonstrated its effectiveness across a range of real-world tasks. Their experiments show that SRT consistently improves sample efficiency, allowing the DRL algorithms to find high-performing solutions with fewer reward evaluations.
Critical Analysis
The researchers have demonstrated the effectiveness of SRT in improving the sample efficiency of DRL algorithms applied to combinatorial optimization problems. However, there are a few potential limitations and areas for further research that are worth considering:
-
Generalization to different problem domains: While the experiments cover a diverse set of tasks, it would be valuable to test SRT on an even broader range of combinatorial optimization problems, including those that may not exhibit obvious symmetries. This would help assess the broader applicability of the method.
-
Handling complex symmetries: The current implementation of SRT focuses on relatively simple symmetries, such as rotations and reflections. Exploring methods to handle more complex and higher-dimensional symmetries could further expand the scope of the technique.
-
Combining SRT with other sample efficiency techniques: SRT could potentially be combined with other approaches for improving sample efficiency, such as curriculum learning or data augmentation, to synergistically enhance the performance of DRL algorithms.
-
Theoretical analysis: A deeper theoretical understanding of the mechanisms underlying SRT's success and its convergence properties could provide valuable insights and guide further improvements to the method.
Overall, the proposed symmetric replay training method represents a promising step towards addressing the sample efficiency challenges in deep reinforcement learning for combinatorial optimization problems. The consistent improvements demonstrated across diverse tasks suggest that SRT is a practical and versatile technique worth further exploration and development.
Conclusion
The paper presents a simple but effective method called symmetric replay training (SRT) that can significantly improve the sample efficiency of deep reinforcement learning (DRL) algorithms applied to combinatorial optimization problems. By leveraging high-reward samples to encourage exploration of under-explored symmetric regions, SRT enables DRL to find high-performing solutions with fewer reward evaluations, which is particularly important for computationally intensive tasks.
The experimental results across a range of real-world applications, such as molecular optimization and hardware design, highlight the consistent and substantial benefits of SRT in enhancing the sample efficiency of various DRL methods. This work represents an important step forward in making DRL more practical and accessible for solving complex combinatorial optimization challenges, with potential implications for a wide variety of industries and research fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Symmetric Replay Training: Enhancing Sample Efficiency in Deep Reinforcement Learning for Combinatorial Optimization
Hyeonah Kim, Minsu Kim, Sungsoo Ahn, Jinkyoo Park
Deep reinforcement learning (DRL) has significantly advanced the field of combinatorial optimization (CO). However, its practicality is hindered by the necessity for a large number of reward evaluations, especially in scenarios involving computationally intensive function assessments. To enhance the sample efficiency, we propose a simple but effective method, called symmetric replay training (SRT), which can be easily integrated into various DRL methods. Our method leverages high-reward samples to encourage exploration of the under-explored symmetric regions without additional online interactions - free. Through replay training, the policy is trained to maximize the likelihood of the symmetric trajectories of discovered high-rewarded samples. Experimental results demonstrate the consistent improvement of our method in sample efficiency across diverse DRL methods applied to real-world tasks, such as molecular optimization and hardware design.
Read more7/18/2024
0
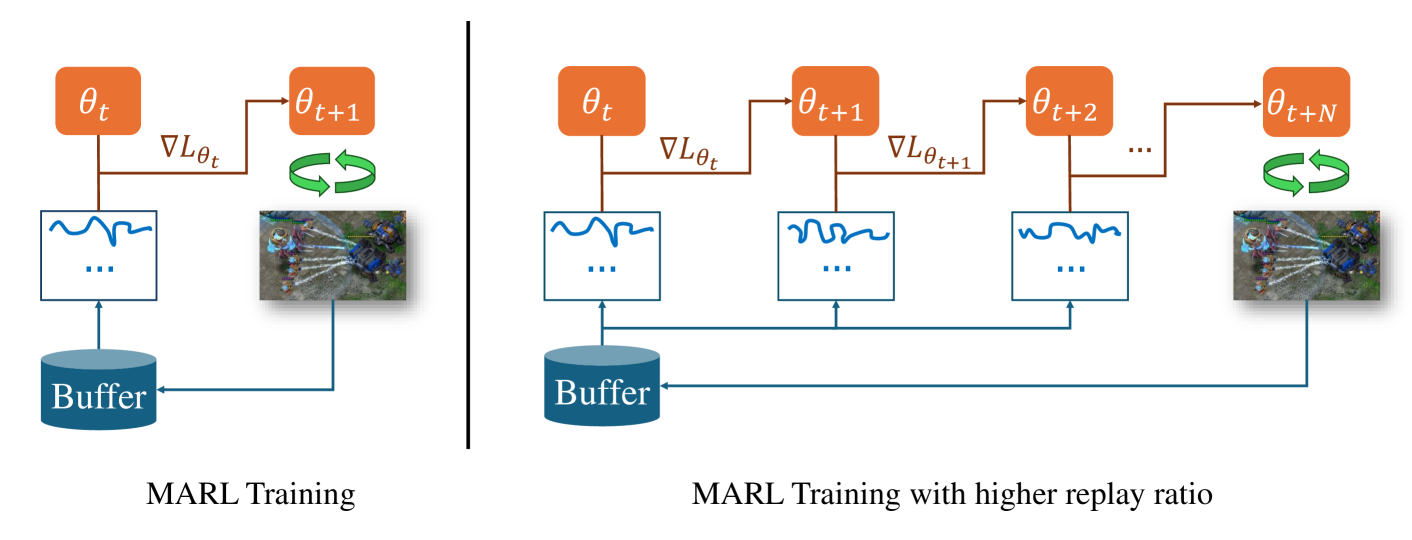
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Linjie Xu, Zichuan Liu, Alexander Dockhorn, Diego Perez-Liebana, Jinyu Wang, Lei Song, Jiang Bian
One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.
Read more4/16/2024

0
Deep reinforcement learning with symmetric data augmentation applied for aircraft lateral attitude tracking control
Yifei Li, Erik-jan van Kampen
Symmetry is an essential property in some dynamical systems that can be exploited for state transition prediction and control policy optimization. This paper develops two symmetry-integrated Reinforcement Learning (RL) algorithms based on standard Deep Deterministic Policy Gradient (DDPG),which leverage environment symmetry to augment explored transition samples of a Markov Decision Process(MDP). The firstly developed algorithm is named as Deep Deterministic Policy Gradient with Symmetric Data Augmentation (DDPG-SDA), which enriches dataset of standard DDPG algorithm by symmetric data augmentation method under symmetry assumption of a dynamical system. To further improve sample utilization efficiency, the second developed RL algorithm incorporates one extra critic network, which is independently trained with augmented dataset. A two-step approximate policy iteration method is proposed to integrate training for two critic networks and one actor network. The resulting RL algorithm is named as Deep Deterministic Policy Gradient with Symmetric Critic Augmentation (DDPG-SCA). Simulation results demonstrate enhanced sample efficiency and tracking performance of developed two RL algorithms in aircraft lateral tracking control task.
Read more7/17/2024

0
Symmetric Reinforcement Learning Loss for Robust Learning on Diverse Tasks and Model Scales
Ju-Seung Byun, Andrew Perrault
Reinforcement learning (RL) training is inherently unstable due to factors such as moving targets and high gradient variance. Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning from AI Feedback (RLAIF) can introduce additional difficulty. Differing preferences can complicate the alignment process, and prediction errors in a trained reward model can become more severe as the LLM generates unseen outputs. To enhance training robustness, RL has adopted techniques from supervised learning, such as ensembles and layer normalization. In this work, we improve the stability of RL training by adapting the reverse cross entropy (RCE) from supervised learning for noisy data to define a symmetric RL loss. We demonstrate performance improvements across various tasks and scales. We conduct experiments in discrete action tasks (Atari games) and continuous action space tasks (MuJoCo benchmark and Box2D) using Symmetric A2C (SA2C) and Symmetric PPO (SPPO), with and without added noise with especially notable performance in SPPO across different hyperparameters. Furthermore, we validate the benefits of the symmetric RL loss when using SPPO for large language models through improved performance in RLHF tasks, such as IMDB positive sentiment sentiment and TL;DR summarization tasks.
Read more5/30/2024