Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
2404.09715
0
0
Abstract
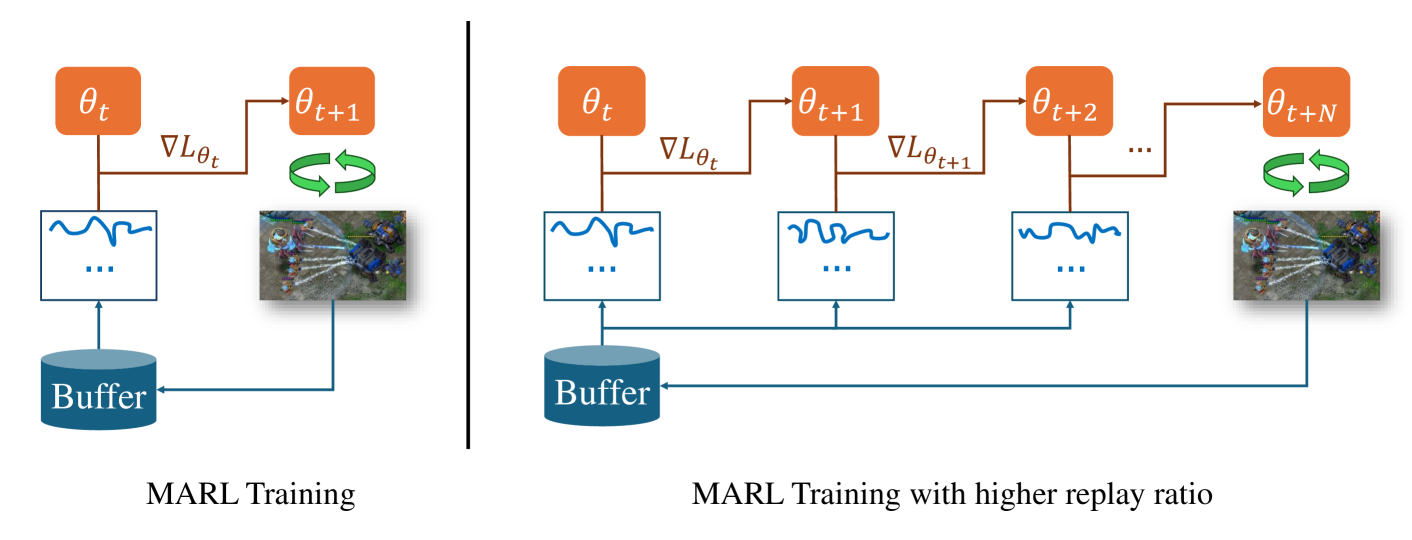
One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.
Create account to get full access
Overview
- This paper investigates improving sample efficiency in multi-agent reinforcement learning (MARL) by increasing the replay ratio, which is the number of samples used from the replay buffer compared to the number of new samples collected.
- The authors test their approach on the StarCraft II game environment and demonstrate significant improvements in sample efficiency compared to previous MARL methods.
- The key insight is that increasing the replay ratio allows the agents to learn more from their past experiences, leading to faster convergence and better performance.
Plain English Explanation
In the field of artificial intelligence, reinforcement learning is a powerful technique where agents learn to make decisions by interacting with an environment and receiving rewards or penalties. Multi-agent reinforcement learning (MARL) extends this concept to scenarios where multiple agents learn and interact simultaneously.
One challenge with MARL is that it can be very sample-inefficient, meaning the agents require a large number of interactions with the environment to learn effective policies. This can be particularly problematic in complex environments like video games, where generating new samples is time-consuming and expensive.
The researchers in this paper propose a simple yet effective solution: increase the ratio of samples from the agents' past experiences (the "replay buffer") compared to new samples collected. This "higher replay ratio" allows the agents to learn more from their previous experiences, leading to faster convergence and better performance.
The authors test their approach in the StarCraft II game environment, which is a popular benchmark for MARL due to its complexity and strategic depth. They show that their method significantly outperforms previous MARL techniques in terms of sample efficiency, achieving the same level of performance with far fewer interactions with the game environment.
Technical Explanation
The key innovation in this paper is the use of a higher replay ratio in the MARL training process. Traditionally, MARL algorithms use a fixed ratio of samples from the replay buffer to new samples collected from the environment. The authors hypothesize that increasing this ratio can lead to more efficient learning.
Specifically, the authors implement their approach in the context of the Distributed Multi-Agent Reinforcement Learning (DMRL) algorithm, which is a state-of-the-art MARL method. They modify DMRL to use a higher replay ratio and evaluate the performance on the StarCraft II environment.
The results show that the higher replay ratio approach significantly outperforms the original DMRL algorithm in terms of sample efficiency. For example, to achieve the same level of performance, the higher replay ratio method requires roughly half the number of environment interactions.
The authors attribute this improvement to the agents' ability to learn more effectively from their past experiences, which helps them converge to good policies more quickly. This is particularly beneficial in complex, dynamic environments like StarCraft II, where generating new samples can be computationally expensive.
Critical Analysis
The paper presents a compelling approach to improving sample efficiency in MARL, and the experimental results on the StarCraft II environment are quite impressive. However, there are a few potential limitations and areas for further research:
-
Generalization to other environments: While the authors demonstrate the effectiveness of their method in the StarCraft II domain, it would be valuable to evaluate its performance on a wider range of MARL benchmarks to assess its broader applicability.
-
Theoretical analysis: The paper focuses primarily on the empirical evaluation of the higher replay ratio approach, but a more thorough theoretical analysis of its underlying principles and guarantees could provide additional insights.
-
Hyperparameter tuning: The authors mention that the optimal replay ratio may depend on the specific task and environment. Further research into principled methods for selecting this hyperparameter could be beneficial.
-
Scalability to larger teams: The experiments in the paper involve relatively small teams of agents (up to 5). Investigating the scalability of the higher replay ratio approach to larger multi-agent systems would be an interesting area for future work.
Overall, this paper presents a simple yet effective technique for improving sample efficiency in MARL, which has the potential to significantly impact the field and enable more practical real-world applications of multi-agent systems.
Conclusion
This paper introduces a novel approach to enhancing sample efficiency in multi-agent reinforcement learning (MARL) by increasing the ratio of samples from the agents' past experiences (the replay buffer) compared to new samples collected from the environment. The authors demonstrate the effectiveness of this "higher replay ratio" method on the challenging StarCraft II game environment, where it significantly outperforms previous MARL techniques in terms of sample efficiency.
The key insight is that allowing the agents to learn more from their past experiences leads to faster convergence and better performance, which is particularly valuable in complex, dynamic environments where generating new samples is computationally expensive. While the paper focuses on the StarCraft II domain, the higher replay ratio approach has the potential for broader applicability in the field of MARL and could enable more practical real-world deployments of multi-agent systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient Multi-agent Reinforcement Learning by Planning
Qihan Liu, Jianing Ye, Xiaoteng Ma, Jun Yang, Bin Liang, Chongjie Zhang
0
0
Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
5/21/2024
🏅
Provably Efficient Information-Directed Sampling Algorithms for Multi-Agent Reinforcement Learning
Qiaosheng Zhang, Chenjia Bai, Shuyue Hu, Zhen Wang, Xuelong Li
0
0
This work designs and analyzes a novel set of algorithms for multi-agent reinforcement learning (MARL) based on the principle of information-directed sampling (IDS). These algorithms draw inspiration from foundational concepts in information theory, and are proven to be sample efficient in MARL settings such as two-player zero-sum Markov games (MGs) and multi-player general-sum MGs. For episodic two-player zero-sum MGs, we present three sample-efficient algorithms for learning Nash equilibrium. The basic algorithm, referred to as MAIDS, employs an asymmetric learning structure where the max-player first solves a minimax optimization problem based on the joint information ratio of the joint policy, and the min-player then minimizes the marginal information ratio with the max-player's policy fixed. Theoretical analyses show that it achieves a Bayesian regret of tilde{O}(sqrt{K}) for K episodes. To reduce the computational load of MAIDS, we develop an improved algorithm called Reg-MAIDS, which has the same Bayesian regret bound while enjoying less computational complexity. Moreover, by leveraging the flexibility of IDS principle in choosing the learning target, we propose two methods for constructing compressed environments based on rate-distortion theory, upon which we develop an algorithm Compressed-MAIDS wherein the learning target is a compressed environment. Finally, we extend Reg-MAIDS to multi-player general-sum MGs and prove that it can learn either the Nash equilibrium or coarse correlated equilibrium in a sample efficient manner.
5/1/2024
Sample-Efficient Robust Multi-Agent Reinforcement Learning in the Face of Environmental Uncertainty
Laixi Shi, Eric Mazumdar, Yuejie Chi, Adam Wierman
0
0
To overcome the sim-to-real gap in reinforcement learning (RL), learned policies must maintain robustness against environmental uncertainties. While robust RL has been widely studied in single-agent regimes, in multi-agent environments, the problem remains understudied -- despite the fact that the problems posed by environmental uncertainties are often exacerbated by strategic interactions. This work focuses on learning in distributionally robust Markov games (RMGs), a robust variant of standard Markov games, wherein each agent aims to learn a policy that maximizes its own worst-case performance when the deployed environment deviates within its own prescribed uncertainty set. This results in a set of robust equilibrium strategies for all agents that align with classic notions of game-theoretic equilibria. Assuming a non-adaptive sampling mechanism from a generative model, we propose a sample-efficient model-based algorithm (DRNVI) with finite-sample complexity guarantees for learning robust variants of various notions of game-theoretic equilibria. We also establish an information-theoretic lower bound for solving RMGs, which confirms the near-optimal sample complexity of DRNVI with respect to problem-dependent factors such as the size of the state space, the target accuracy, and the horizon length.
5/10/2024

Representation Learning For Efficient Deep Multi-Agent Reinforcement Learning
Dom Huh, Prasant Mohapatra
0
0
Sample efficiency remains a key challenge in multi-agent reinforcement learning (MARL). A promising approach is to learn a meaningful latent representation space through auxiliary learning objectives alongside the MARL objective to aid in learning a successful control policy. In our work, we present MAPO-LSO (Multi-Agent Policy Optimization with Latent Space Optimization) which applies a form of comprehensive representation learning devised to supplement MARL training. Specifically, MAPO-LSO proposes a multi-agent extension of transition dynamics reconstruction and self-predictive learning that constructs a latent state optimization scheme that can be trivially extended to current state-of-the-art MARL algorithms. Empirical results demonstrate MAPO-LSO to show notable improvements in sample efficiency and learning performance compared to its vanilla MARL counterpart without any additional MARL hyperparameter tuning on a diverse suite of MARL tasks.
6/6/2024