SymPAC: Scalable Symbolic Music Generation With Prompts And Constraints

0

Sign in to get full access
Overview
- SymPAC is a system for generating symbolic music with prompts and constraints.
- It can create diverse, high-quality musical compositions by combining user-specified prompts and constraints.
- The system leverages large language models and diffusion models to generate musical scores in a scalable and efficient manner.
Plain English Explanation
SymPAC: Scalable Symbolic Music Generation With Prompts And Constraints is a research paper that introduces a new approach for generating symbolic music. The key idea is to allow users to provide prompts (e.g., a short melodic fragment) and constraints (e.g., the desired key or tempo) that guide the music generation process.
The system leverages large language models and diffusion models to generate diverse and high-quality musical compositions in a scalable way. This means that the system can produce a wide range of unique musical pieces while still allowing the user to maintain a level of control over the output.
By combining user-specified prompts and constraints, SymPAC enables a more controllable and personalized approach to symbolic music generation compared to traditional generative models. This can be useful for various applications, such as music composition, educational tools, and creative applications.
Technical Explanation
The SymPAC system consists of two main components: a prompt encoder and a diffusion-based generator. The prompt encoder takes in a user-provided prompt (e.g., a short melody) and encodes it into a latent representation. The diffusion-based generator then uses this latent representation, along with the user-specified constraints, to generate a complete musical score.
The diffusion-based generator is a powerful generative model that can produce diverse and high-quality musical compositions. By conditioning the generation process on the user's prompts and constraints, SymPAC ensures that the output aligns with the user's preferences and creative vision.
The researchers evaluate SymPAC on various music generation tasks and demonstrate its ability to produce diverse, coherent, and musically-relevant compositions. They also show that SymPAC outperforms other state-of-the-art music generation systems in terms of both objective and subjective metrics.
Critical Analysis
The SymPAC paper presents a promising approach to symbolic music generation, but it also acknowledges several limitations and areas for future research:
- The current system is trained on a relatively small dataset of MIDI files, which may limit its ability to generate more complex and diverse musical compositions. Expanding the training dataset could help improve the system's capabilities.
- The paper does not provide a detailed analysis of the computational complexity and scalability of the SymPAC system. As the model grows in size and complexity, the computational requirements may become a concern, especially for real-time applications.
- The paper focuses on symbolic music generation and does not address the integration of audio generation or the translation between symbolic and audio representations. Exploring these aspects could expand the system's applicability.
- The evaluation of SymPAC is primarily based on objective metrics and subjective human assessments. Incorporating more rigorous user studies and real-world deployment scenarios could provide additional insights into the system's practical utility and user experience.
Conclusion
SymPAC represents a significant advancement in the field of symbolic music generation by enabling users to guide the generation process through the use of prompts and constraints. The system's combination of large language models and diffusion-based generators allows for the creation of diverse and high-quality musical compositions in a scalable manner.
While the paper highlights several promising aspects of SymPAC, it also identifies areas for future research and improvement. Addressing the limitations related to dataset size, computational complexity, and the integration of audio generation could further enhance the system's capabilities and its potential impact on various music-related applications.
Overall, the SymPAC system demonstrates the value of user-centric approaches to music generation and the potential of large-scale language models and diffusion-based techniques in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SymPAC: Scalable Symbolic Music Generation With Prompts And Constraints
Haonan Chen, Jordan B. L. Smith, Janne Spijkervet, Ju-Chiang Wang, Pei Zou, Bochen Li, Qiuqiang Kong, Xingjian Du
Progress in the task of symbolic music generation may be lagging behind other tasks like audio and text generation, in part because of the scarcity of symbolic training data. In this paper, we leverage the greater scale of audio music data by applying pre-trained MIR models (for transcription, beat tracking, structure analysis, etc.) to extract symbolic events and encode them into token sequences. To the best of our knowledge, this work is the first to demonstrate the feasibility of training symbolic generation models solely from auto-transcribed audio data. Furthermore, to enhance the controllability of the trained model, we introduce SymPAC (Symbolic Music Language Model with Prompting And Constrained Generation), which is distinguished by using (a) prompt bars in encoding and (b) a technique called Constrained Generation via Finite State Machines (FSMs) during inference time. We show the flexibility and controllability of this approach, which may be critical in making music AI useful to creators and users.
Read more9/11/2024

0
Flexible Control in Symbolic Music Generation via Musical Metadata
Sangjun Han, Jiwon Ham, Chaeeun Lee, Heejin Kim, Soojong Do, Sihyuk Yi, Jun Seo, Seoyoon Kim, Yountae Jung, Woohyung Lim
In this work, we introduce the demonstration of symbolic music generation, focusing on providing short musical motifs that serve as the central theme of the narrative. For the generation, we adopt an autoregressive model which takes musical metadata as inputs and generates 4 bars of multitrack MIDI sequences. During training, we randomly drop tokens from the musical metadata to guarantee flexible control. It provides users with the freedom to select input types while maintaining generative performance, enabling greater flexibility in music composition. We validate the effectiveness of the strategy through experiments in terms of model capacity, musical fidelity, diversity, and controllability. Additionally, we scale up the model and compare it with other music generation model through a subjective test. Our results indicate its superiority in both control and music quality. We provide a URL link https://www.youtube.com/watch?v=-0drPrFJdMQ to our demonstration video.
Read more9/14/2024

0
Practical and Reproducible Symbolic Music Generation by Large Language Models with Structural Embeddings
Seungyeon Rhyu, Kichang Yang, Sungjun Cho, Jaehyeon Kim, Kyogu Lee, Moontae Lee
Music generation introduces challenging complexities to large language models. Symbolic structures of music often include vertical harmonization as well as horizontal counterpoint, urging various adaptations and enhancements for large-scale Transformers. However, existing works share three major drawbacks: 1) their tokenization requires domain-specific annotations, such as bars and beats, that are typically missing in raw MIDI data; 2) the pure impact of enhancing token embedding methods is hardly examined without domain-specific annotations; and 3) existing works to overcome the aforementioned drawbacks, such as MuseNet, lack reproducibility. To tackle such limitations, we develop a MIDI-based music generation framework inspired by MuseNet, empirically studying two structural embeddings that do not rely on domain-specific annotations. We provide various metrics and insights that can guide suitable encoding to deploy. We also verify that multiple embedding configurations can selectively boost certain musical aspects. By providing open-source implementations via HuggingFace, our findings shed light on leveraging large language models toward practical and reproducible music generation.
Read more7/30/2024
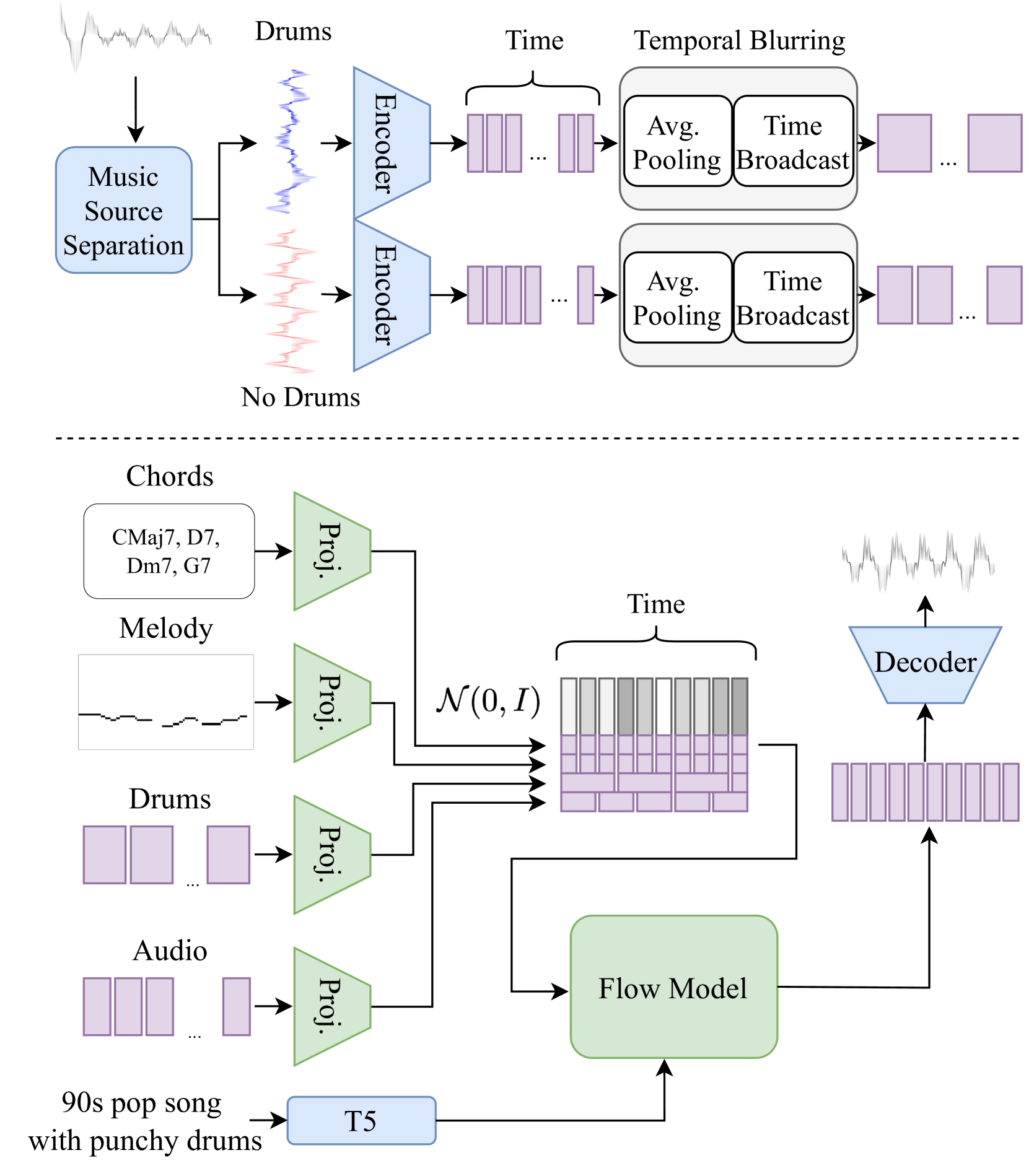
1
Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation
Or Tal, Alon Ziv, Itai Gat, Felix Kreuk, Yossi Adi
We present JASCO, a temporally controlled text-to-music generation model utilizing both symbolic and audio-based conditions. JASCO can generate high-quality music samples conditioned on global text descriptions along with fine-grained local controls. JASCO is based on the Flow Matching modeling paradigm together with a novel conditioning method. This allows music generation controlled both locally (e.g., chords) and globally (text description). Specifically, we apply information bottleneck layers in conjunction with temporal blurring to extract relevant information with respect to specific controls. This allows the incorporation of both symbolic and audio-based conditions in the same text-to-music model. We experiment with various symbolic control signals (e.g., chords, melody), as well as with audio representations (e.g., separated drum tracks, full-mix). We evaluate JASCO considering both generation quality and condition adherence, using both objective metrics and human studies. Results suggest that JASCO is comparable to the evaluated baselines considering generation quality while allowing significantly better and more versatile controls over the generated music. Samples are available on our demo page https://pages.cs.huji.ac.il/adiyoss-lab/JASCO.
Read more6/18/2024