Joint Audio and Symbolic Conditioning for Temporally Controlled Text-to-Music Generation
2406.10970
2
0
Abstract
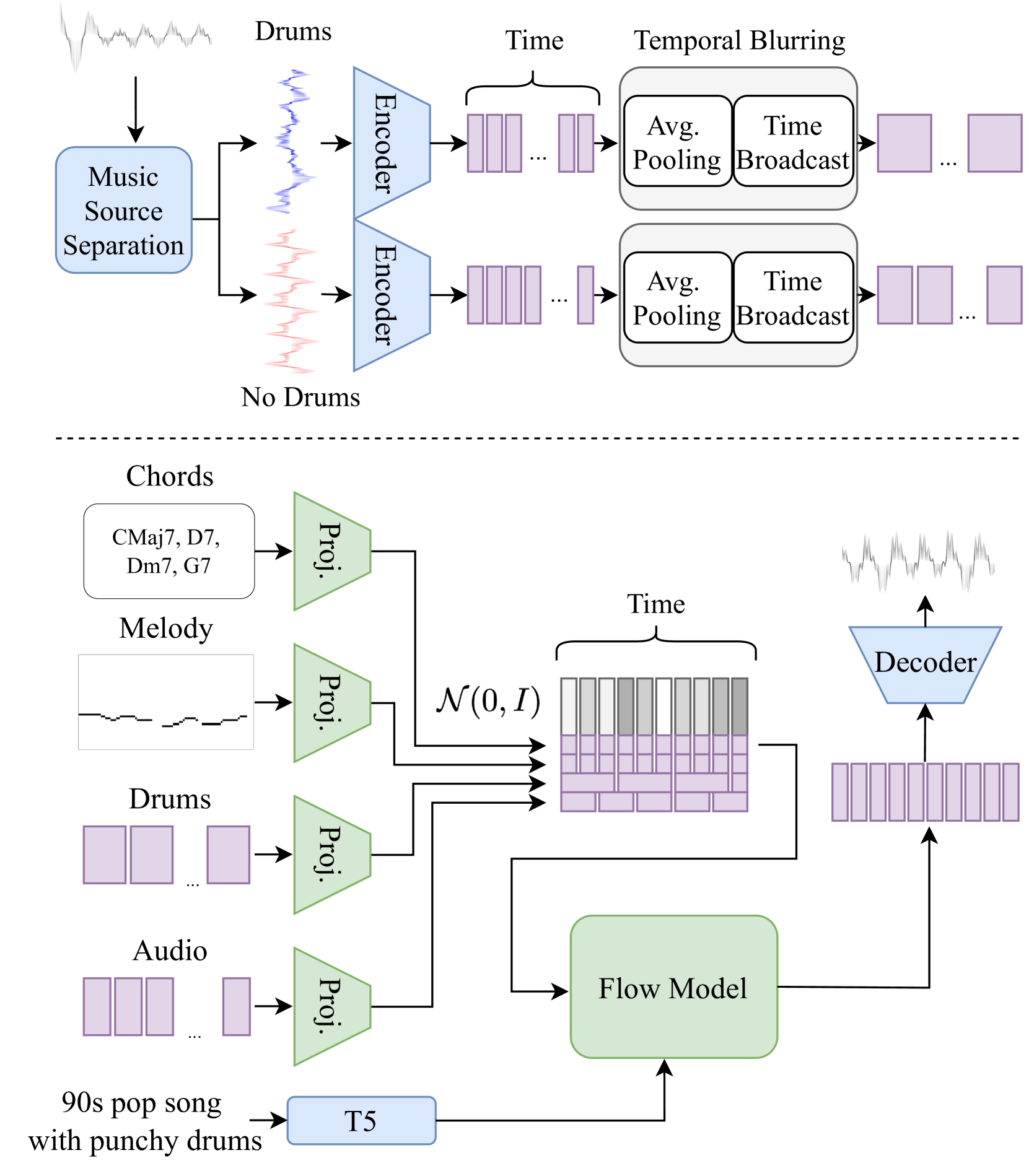
We present JASCO, a temporally controlled text-to-music generation model utilizing both symbolic and audio-based conditions. JASCO can generate high-quality music samples conditioned on global text descriptions along with fine-grained local controls. JASCO is based on the Flow Matching modeling paradigm together with a novel conditioning method. This allows music generation controlled both locally (e.g., chords) and globally (text description). Specifically, we apply information bottleneck layers in conjunction with temporal blurring to extract relevant information with respect to specific controls. This allows the incorporation of both symbolic and audio-based conditions in the same text-to-music model. We experiment with various symbolic control signals (e.g., chords, melody), as well as with audio representations (e.g., separated drum tracks, full-mix). We evaluate JASCO considering both generation quality and condition adherence, using both objective metrics and human studies. Results suggest that JASCO is comparable to the evaluated baselines considering generation quality while allowing significantly better and more versatile controls over the generated music. Samples are available on our demo page https://pages.cs.huji.ac.il/adiyoss-lab/JASCO.
Create account to get full access
Overview
- This paper presents a novel approach for temporally controlled text-to-music generation, where the generated music aligns with the semantics and timing of input text.
- The method leverages joint audio and symbolic conditioning, incorporating both audio and text-based information to produce more coherent and expressive musical outputs.
- The proposed model allows for fine-grained control over the timing and progression of the generated music, enabling users to precisely control the dynamics and structure of the output.
Plain English Explanation
This research paper introduces a new way to generate music that is closely tied to the meaning and timing of written text. The key idea is to combine audio information (the actual sound of the music) and symbolic information (the musical notation and structure) to create more coherent and expressive musical outputs that align with the input text.
The main benefit of this approach is that it gives users much more control over the timing and progression of the generated music. Instead of just getting a generic musical output, you can precisely control how the music evolves and changes over time to match the semantics and rhythm of the text. This could be useful for applications like linking to music generation for storylines or generating soundtracks for interactive experiences.
For example, imagine you're writing a script for a short film. With this technology, you could specify key moments in the text and have the music dynamically adapt to match the mood, pacing, and narrative flow. The music would feel much more in sync and tailored to the story, rather than just a generic background track.
Technical Explanation
The core of this work is a deep learning model that takes in both textual and audio inputs and learns to generate music that aligns with the semantics and timing of the text. The model architecture leverages a combination of text-based and audio-based conditioning to capture the multifaceted relationship between language and music.
Key aspects of the technical approach include:
- Text Encoding: The input text is encoded using a large language model to extract semantic and structural information.
- Audio Conditioning: Parallel audio processing modules extract low-level acoustic features and higher-level musical attributes from reference audio examples.
- Temporal Alignment: The model learns to map the text encoding to the appropriate musical dynamics and progression over time, enabling fine-grained temporal control of the generated output.
- Joint Optimization: The text-based and audio-based conditioning signals are combined and jointly optimized to produce musically coherent results that faithfully reflect the input text.
Through extensive experiments, the authors demonstrate the effectiveness of this approach in generating music that is both semantically and temporally aligned with the input text, outperforming previous text-to-music generation methods.
Critical Analysis
One potential limitation of this work is the reliance on parallel audio examples to condition the model. While this allows for better audio-text alignment, it may limit the model's ability to generate truly novel musical compositions from scratch. The authors acknowledge this and suggest exploring alternative conditioning methods that can learn to generate music without the need for reference examples.
Additionally, the evaluation of the model's performance is primarily based on human assessments and subjective measures of coherence and alignment. While these are important factors, more objective metrics for assessing the quality and creativity of the generated music could provide additional insights.
Further research could also explore the potential biases and limitations of the training data, as well as the model's ability to generalize to a wider range of text and musical styles. Investigating the model's interpretability and the extent to which users can fine-tune and control the generated outputs could also be valuable.
Conclusion
This paper presents a significant step forward in the field of text-to-music generation by introducing a novel approach that jointly leverages textual and audio-based conditioning. The resulting model allows for fine-grained temporal control over the generated music, aligning it closely with the semantics and rhythm of the input text.
The potential applications of this technology are wide-ranging, from generating soundtracks for interactive experiences to creating more coherent and expressive music for storylines and narratives. As the field of artificial intelligence and creative technology continues to evolve, this work represents an important contribution towards more seamless and intuitive ways of combining language and music.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
ICGAN: An implicit conditioning method for interpretable feature control of neural audio synthesis
Yunyi Liu, Craig Jin
0
0
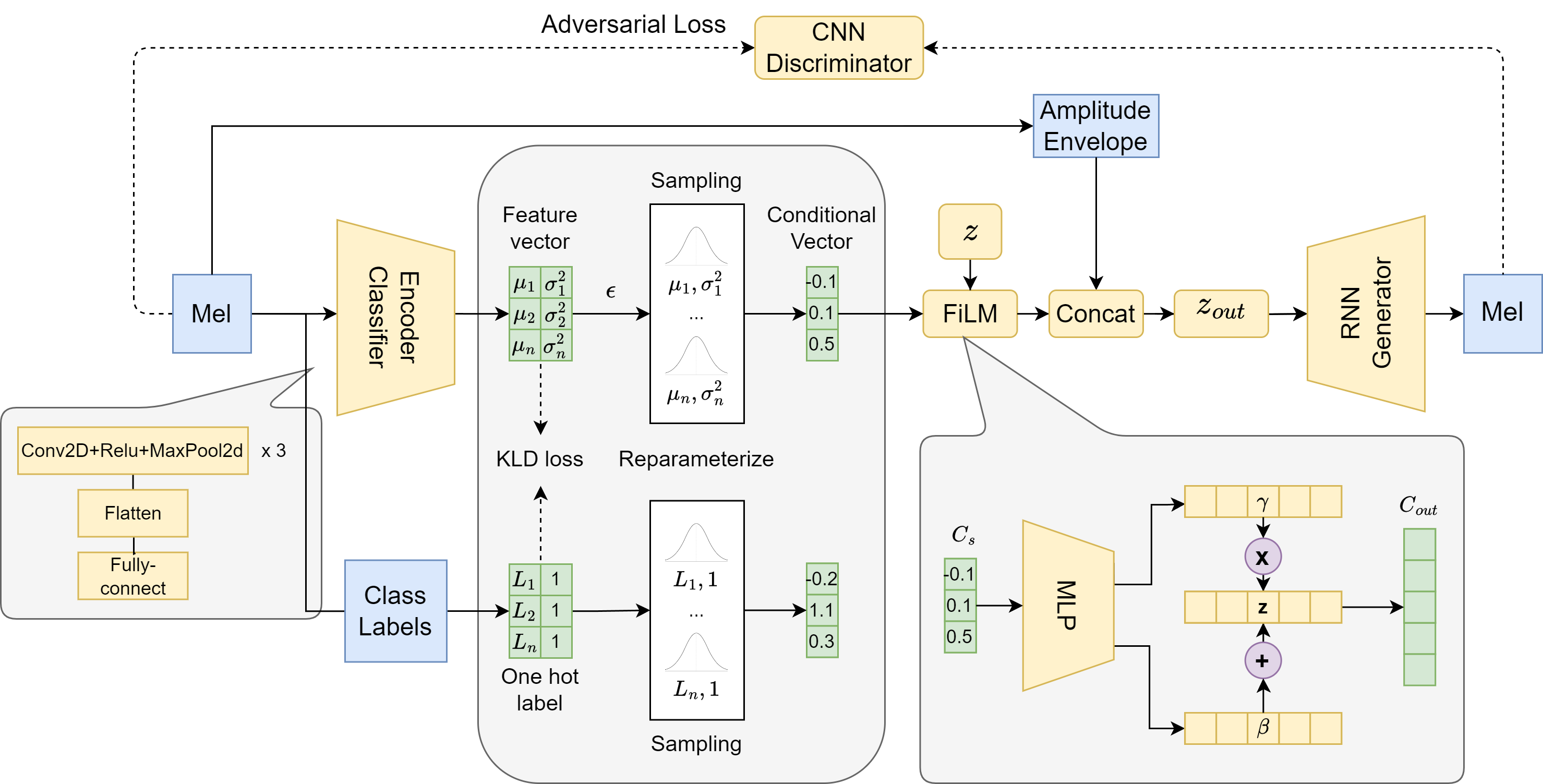
Neural audio synthesis methods can achieve high-fidelity and realistic sound generation by utilizing deep generative models. Such models typically rely on external labels which are often discrete as conditioning information to achieve guided sound generation. However, it remains difficult to control the subtle changes in sounds without appropriate and descriptive labels, especially given a limited dataset. This paper proposes an implicit conditioning method for neural audio synthesis using generative adversarial networks that allows for interpretable control of the acoustic features of synthesized sounds. Our technique creates a continuous conditioning space that enables timbre manipulation without relying on explicit labels. We further introduce an evaluation metric to explore controllability and demonstrate that our approach is effective in enabling a degree of controlled variation of different synthesized sound effects for in-domain and cross-domain sounds.
6/12/2024
Intelligent Text-Conditioned Music Generation
Zhouyao Xie, Nikhil Yadala, Xinyi Chen, Jing Xi Liu
0
0
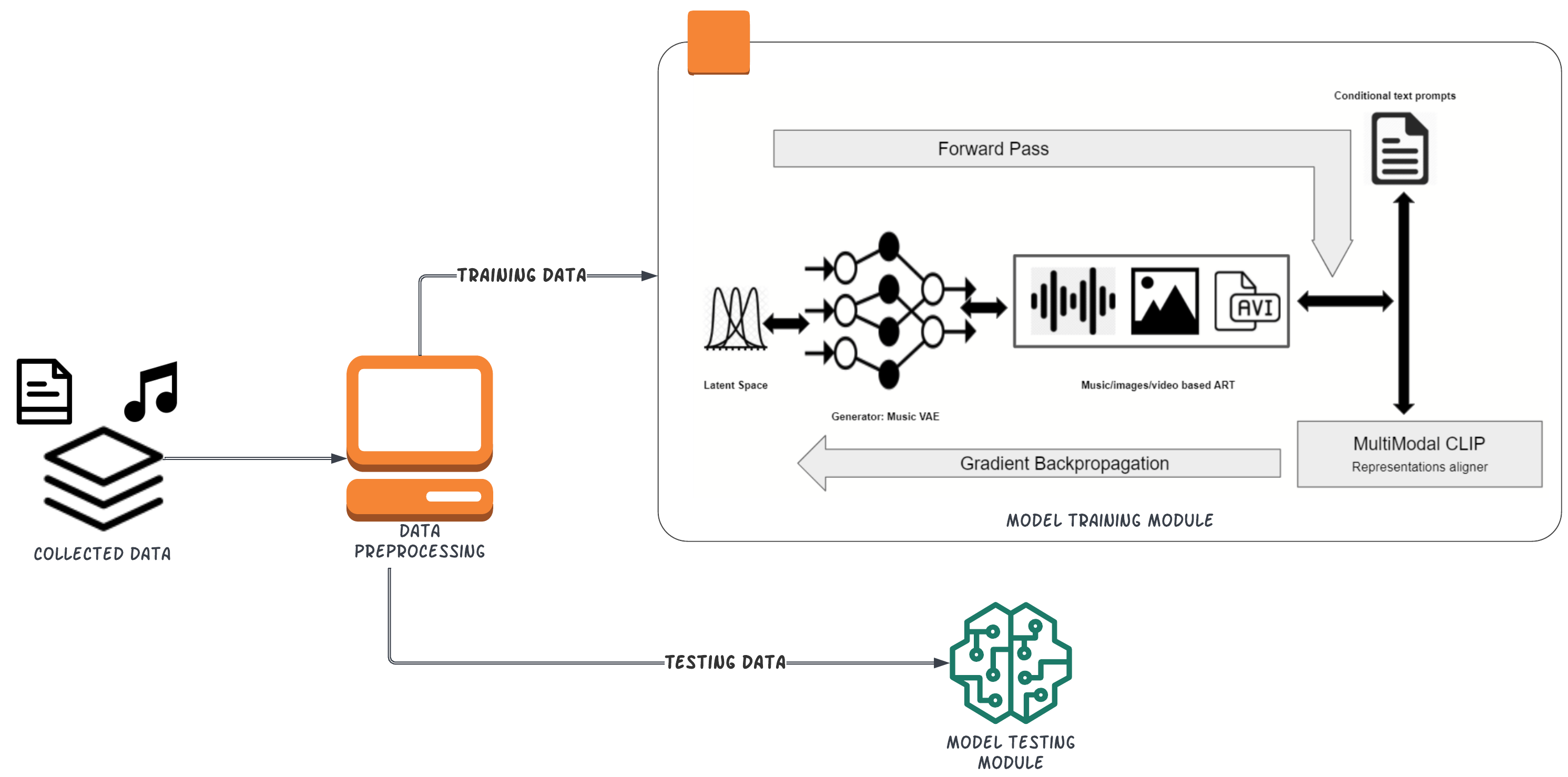
CLIP (Contrastive Language-Image Pre-Training) is a multimodal neural network trained on (text, image) pairs to predict the most relevant text caption given an image. It has been used extensively in image generation by connecting its output with a generative model such as VQGAN, with the most notable example being OpenAI's DALLE-2. In this project, we apply a similar approach to bridge the gap between natural language and music. Our model is split into two steps: first, we train a CLIP-like model on pairs of text and music over contrastive loss to align a piece of music with its most probable text caption. Then, we combine the alignment model with a music decoder to generate music. To the best of our knowledge, this is the first attempt at text-conditioned deep music generation. Our experiments show that it is possible to train the text-music alignment model using contrastive loss and train a decoder to generate music from text prompts.
6/4/2024
💬
Content-based Controls For Music Large Language Modeling
Liwei Lin, Gus Xia, Junyan Jiang, Yixiao Zhang
0
0
Recent years have witnessed a rapid growth of large-scale language models in the domain of music audio. Such models enable end-to-end generation of higher-quality music, and some allow conditioned generation using text descriptions. However, the control power of text controls on music is intrinsically limited, as they can only describe music indirectly through meta-data (such as singers and instruments) or high-level representations (such as genre and emotion). We aim to further equip the models with direct and content-based controls on innate music languages such as pitch, chords and drum track. To this end, we contribute Coco-Mulla, a content-based control method for music large language modeling. It uses a parameter-efficient fine-tuning (PEFT) method tailored for Transformer-based audio models. Experiments show that our approach achieved high-quality music generation with low-resource semi-supervised learning, tuning with less than 4% parameters compared to the original model and training on a small dataset with fewer than 300 songs. Moreover, our approach enables effective content-based controls, and we illustrate the control power via chords and rhythms, two of the most salient features of music audio. Furthermore, we show that by combining content-based controls and text descriptions, our system achieves flexible music variation generation and arrangement. Our source codes and demos are available online.
4/16/2024
🌐
Fast Timing-Conditioned Latent Audio Diffusion
Zach Evans, CJ Carr, Josiah Taylor, Scott H. Hawley, Jordi Pons
0
0
Generating long-form 44.1kHz stereo audio from text prompts can be computationally demanding. Further, most previous works do not tackle that music and sound effects naturally vary in their duration. Our research focuses on the efficient generation of long-form, variable-length stereo music and sounds at 44.1kHz using text prompts with a generative model. Stable Audio is based on latent diffusion, with its latent defined by a fully-convolutional variational autoencoder. It is conditioned on text prompts as well as timing embeddings, allowing for fine control over both the content and length of the generated music and sounds. Stable Audio is capable of rendering stereo signals of up to 95 sec at 44.1kHz in 8 sec on an A100 GPU. Despite its compute efficiency and fast inference, it is one of the best in two public text-to-music and -audio benchmarks and, differently from state-of-the-art models, can generate music with structure and stereo sounds.
5/14/2024